Python脚本批量造数据、跑定时任务协助测试
批量造数据
- 连接Mysql的信息
1 import pymysql
2 # 数据库连接信息
3 # 多个库要有多个conn
4 conn = pymysql.connect(
5 host="主机",
6 user="用户名",
7 password="密码",
8 database="库名"
9 )
10 conn1 = pymysql.connect(
11 host="主机",
12 user="用户名",
13 password="密码",
14 database="库名"
15 )
16
17 # 创建游标对象
18 cursor = conn.cursor()
19 cursor1 = conn1.cursor()
20
21 # 执行对应的SQL
22 cursor.execute
23 # 获取执行结果
24 Result=cursor.fetchall()
场景一:基于已有的csv文件,分批次读取csv文件中的字段值作为变量填充到执行的SQL语句
- 分批读取csv文件中的值
1 csv_file_path = 'csv文件目录'
2 with open(csv_file_path, 'r',encoding='utf-8') as file:
3 reader = csv.reader(file)
4 next(reader) # Skip the header row
5
6 batch_size = 100 # 每批处理的数量
7 total_items = 3100 # 总共需要处理的数量
8
9 for i in range(0, total_items, batch_size):
10 # 在每次循环中处理 batch_size 个项目
11 # 可以在循环体内部使用 i 作为起始索引
12
13 for j in range(i, min(i + batch_size, total_items)):
14 row = next(reader)
15 # 打印这一行的数据
16 print(row)
场景二:随机生成特殊字段的值,作为变量填充到Insert语句中
- 随机生成统代
1 import random
2 import string
3 def generate_credit_code():
4 # 生成第1位登记管理部门代码
5 管理部门代码 = ['1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D']
6 register_department = random.choice(管理部门代码)
7 # print('管理部门代码为',register_department)
8
9 # 生成2-9位组织机构代码
10 organizations_code = []
11 for _ in range(8):
12 org_code = ''
13 for _ in range(8):
14 org_code += random.choice(string.ascii_uppercase + string.digits)
15 organizations_code.append(org_code)
16 organizations_code=random.choice(organizations_code)
17 # print('组织机构代码为',organizations_code)
18
19
20 # 生成10-17位统一社会信用代码
21 unification_credit_code = ''
22 for _ in range(8):
23 unification_credit_code += random.choice(string.ascii_uppercase + string.digits)
24 # print('统一社会信用代码为',unification_credit_code)
25
26 # 组合统一社会信用代码
27 credit_code = f"{register_department}{''.join(organizations_code)}{unification_credit_code}"
28 return credit_code
- 随机生成注册号
1 mport random
2
3 #这个注册号是由15个随机数字组成的,使用random.choice方法从0-9中随机选择数字。这个方法会被调用15次,每次都会生成一个随机数字,然后通过字符串的join方法将这15个数字拼接在一起。
4 def generate_reg_code():
5 # 15位注册号,以0开头
6 reg_code = ''.join(random.choice('0123456789') for i in range(15))
7 return reg_code
结合python+pytest+fixture 实现定时任务接口调用
目录结构
(有些乱。。。
-- config.ini 存放的是系统固定的url之类的
-- conftest.py 一般用于放登录接口,用户返回token,利用fixture被其他接口使用
1 import pytest
2 import requests
3 import pymysql
4 from config import readconfig
5 readcon = readconfig.Read()
6
7
8 @pytest.fixture(scope="session")
9 # 这个方法是pytest封装公共方法的一个文件,文件名必须是(conftest.py)
10 # 作用: 其他地方在使用这个方法时就不用from XX import cc 然后也不用实例化了
11
12
13 def test_login():
14 msg = {
15 "username": '用户名',
16 "password": '加密后的密码'
17 }
18
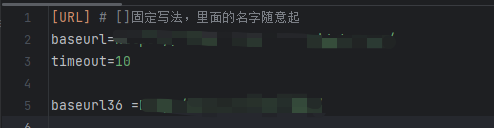
19 url =readcon.get_URL("baseurl")
20 cc = requests.post(url+"api/uxxxxxxr/login", params=msg)
21 getjson = cc.json()
22
23 # 获取token
24 tok = getjson['data']['token']
25 userid = getjson['data']['userId']
26 return tok, userid
定时任务
1 import pytest
2 import requests
3 from config import readconfig
4
5 read = readconfig.Read()
6
7 class TestCase1:
8 global url, tim # 全局变量,便于其他地方调用
9 url = read.get_URL("baseurl") # https://abchina-zx-dev.hsjdata.com/
10 tim = read.get_URL("timeout")
11 '''小姐姐的定时任务'''
12 def test_case1(self, test_login):
13 head = {'Content-Type': 'application/json', 'Authorization': test_login[0]} # test_login[0]为token
14
15 NewtestGsEidList = []
16 NewtestGsCreditCodeList = []
17 NewtestGsEntNameList = []
18 # 取非工商表最新插入的100家企业 同步到es中
19 SelectNewtestGs = "select eid,entname,credit_code from enterprisebaseinfocollect order by id desc limit 100"
20 cursor.execute(SelectNewtestGs)
21 SelectNewtestGsResult = cursor.fetchall()
22
23 for tuple in SelectNewtestGsResult:
24 NewtestGsCreditCodeList.append(tuple[2])
25
26
27 NewtestGsCreditCodeListResult = ', '.join('"' + i + '"' for i in NewtestGsCreditCodeList)
28 print('企业统代为', NewtestGsCreditCodeListResult)
29
30 print(r.json())
import pytest
import requests
import json
import random
from config import readconfig
read = readconfig.Read()
import pymysql
# data_dat =20230907
conn = pymysql.connect(
host="10.1.1.106",
user="cpdev",
password="9abZ7mak2",
database="abchina_home"
)
cursor = conn.cursor()
class TestCase1:
global url, tim # 全局变量,便于其他地方调用
url = read.get_URL("baseurl") # https://abchina-zx-dev.hsjdata.com/
tim = read.get_URL("timeout")
'''小姐姐的定时任务'''
def test_case1(self, test_login):
head = {'Content-Type': 'application/json', 'Authorization': test_login[0]} # test_login[0]为token
NewtestGsEidList = []
NewtestGsCreditCodeList = []
NewtestGsEntNameList = []
# 取非工商表最新插入的100家企业 同步到es中
SelectNewtestGs = "select eid,entname,credit_code from enterprisebaseinfocollect order by id desc limit 100"
cursor.execute(SelectNewtestGs)
SelectNewtestGsResult = cursor.fetchall()
for tuple in SelectNewtestGsResult:
NewtestGsEidList.append(tuple[0])
NewtestGsEntNameList.append(tuple[1])
NewtestGsCreditCodeList.append(tuple[2])
NewtestGsEidListResult = ', '.join(i for i in NewtestGsEidList)
print('最新插入的工商企业的eid',NewtestGsEidListResult)
print('-----------------------------------------------------------------')
NewtestGsEntNameListResult = ', '.join('"' + i + '"' for i in NewtestGsEntNameList)
print('最新插入的工商企业的名称为', NewtestGsEntNameListResult)
print('-----------------------------------------------------------------')
NewtestGsCreditCodeListResult = ', '.join('"' + i + '"' for i in NewtestGsCreditCodeList)
print('最新插入的工商企业的统代为', NewtestGsCreditCodeListResult)
r = requests.get(url + 'api/ent-search/task/initGs?eid='+NewtestGsEidListResult, headers=head)
# assert r.json()['message'] == '成功'
print(r.json())
Python脚本批量造数据、跑定时任务协助测试的更多相关文章
- 使用python脚本批量造数据
本篇将采用 Python 脚本的方式进行批量给mysql造数据. 为了使 Python 可以连上数据库(MySQL),并且可以与数据库交互(增删改查等操作),则需要安装 MySQL 客户端操作库. ...
- python脚本批量生成数据
在平时的工作中,经常会遇到造数据,特别是性能测试的时候更是需要大量的数据.如果一条条的插入数据库或者一条条的创建数据,效率未免有点低.如何快速的造大量的测试数据呢?在不熟悉存储过程的情况下,今天给大家 ...
- Delphi中使用python脚本读取Excel数据
Delphi中使用python脚本读取Excel数据2007-10-18 17:28:22标签:Delphi Excel python原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 . ...
- Jmeter(二十三)Jmeter-Question之“批量造数据”
日常工作中,无论是在做功能测试.接口测试还是性能测试,经常会有这么一个场景出现,“那个谁谁谁,帮我加几条订单”,“那个某某某,给购物车增添几个产品”,“在数据库加几百条数据”...等等,通常少数量,或 ...
- SpringBoot(18)---通过Lua脚本批量插入数据到Redis布隆过滤器
通过Lua脚本批量插入数据到布隆过滤器 有关布隆过滤器的原理之前写过一篇博客: 算法(3)---布隆过滤器原理 在实际开发过程中经常会做的一步操作,就是判断当前的key是否存在. 那这篇博客主要分为三 ...
- 怎样通过excel录入来批量造数据
背景: 自动化测试除了验证系统功能外,还能够为测试人员根据测试要求造数据实现测试需要!但是一般的自动化测试,都是在编写脚本的时候,写死在程序里的.所以本文是为了在满足系统操作流程的基础上,根据测试的要 ...
- 除了binlog2sql工具外,使用python脚本闪回数据(数据库误操作)
利用binlog日志恢复数据库误操作数据 在人工手动进行一些数据库写操作的时候(比方说数据修改),尤其是一些不可控的批量更新或删除,通常都建议备份后操作.不过不怕万一,就怕一万,有备无患总是好的.在线 ...
- 使用Python脚本批量裁切栅格
对栅格的裁切,我们通常使用裁切(数据管理-栅格-栅格处理)或按掩膜提取(空间分析-提取分析)来裁切,裁切的矢量要素通常是一个要素图层或Shape文件.如果要进行批量处理,可以使用ToolBox中的批量 ...
- 使用python脚本批量设置nginx站点的rewrite规则
一般情况下,配置rewrite重写规则使用shell脚本即可: 把url拼凑成1,2文件中中的格式,运行 chongxie.sh 即可生成我们需要的rewrite规则 [root@web01:/opt ...
- python脚本批量生成50000条插入数据的sql语句
f = open("xx.txt",'w') for i in range(1,50001): str_i = str(i) realname = "lxs"+ ...
随机推荐
- 2023-05-27:给你一个只包含小写英文字母的字符串 s 。 每一次 操作 ,你可以选择 s 中两个 相邻 的字符,并将它们交换。 请你返回将 s 变成回文串的 最少操作次数 。 注意 ,输入数据
2023-05-27:给你一个只包含小写英文字母的字符串 s . 每一次 操作 ,你可以选择 s 中两个 相邻 的字符,并将它们交换. 请你返回将 s 变成回文串的 最少操作次数 . 注意 ,输入数据 ...
- hvv蓝初面试常见漏洞问题(下)
hvv蓝初面试常见漏洞问题(上) 6.ssrf 服务端伪造请求 原理 服务端提供了向其他服务器应用获取数据的功能,而没有对目标地址做任何过滤和限制.攻击者进而利用其对内部资源进行攻击.(通俗来说:就是 ...
- 【踩坑记录】字节流数据按照string的方式读取然后按照string的方案存储,编码导致二进制数据发生变化,原理记录
目录 问题缘由 背后原理 C#代码示例 总结 问题缘由 由于公司需求,需要读取游戏Redis数据做内外网数据迁移,没有与游戏组过多的沟通. 使用的数据类型是Hash, key是string,va ...
- 一次有关 DNS 解析导致 APP 慢的问题探究
目录 一.业务背景 二. 问题 三.问题排查 3.1.问题一: 基于DNS 延迟的解析 3.2.问题二:HTTPDNS侧 HTTPDNS基础理论 相关问题 四.优化方向 4.1.域名解析配置 4.2. ...
- 2023-06-11:redis中,如何在100个亿URL中快速判断某URL是否存在?
2023-06-11:redis中,如何在100个亿URL中快速判断某URL是否存在? 答案2023-06-11: 传统数据结构的不足 当然有人会想,我直接将网页URL存入数据库进行查找不就好了,或者 ...
- 批量生成,本地推理,人工智能声音克隆框架PaddleSpeech本地批量克隆实践(Python3.10)
云端炼丹固然是极好的,但不能否认的是,成本要比本地高得多,同时考虑到深度学习的训练相对于推理来说成本也更高,这主要是因为它需要大量的数据.计算资源和时间等资源,并且对超参数的调整也要求较高,更适合在云 ...
- CKS 考试题整理 (03)-kube-bench 修复不安全项
Context 针对 kubeadm 创建的 cluster 运行 CIS 基准测试工具时,发现了多个必须立即解决的问题. Task 通过配置修复所有问题并重新启动受影响的组件以确保新的设置生效. 修 ...
- tvm relay IR 可视化
本文地址: https://www.cnblogs.com/wanger-sjtu/p/16819877.html 发现最近relay 的可视化已经在tvm主线上支持了,这里有一个简单的demo代码记 ...
- MAC地址、IP地址与子网———计算机网络
计算机具有强大的功能.除了体现与计算机本身具有的计算能力外,其他的功能大多是基于与其他计算机联网提供的. 然而,计算机之间的联网不是一根网线就能解决嘛? 答案当然是否定的.实际上计算机间的交流过程十分 ...
- 云享·案例丨打造数智物流底座,华为云DTSE助力物联云仓解锁物流新“速度”
摘要:华为云凭借领先的技术和快速响应的开发者支持服务,助力物联亿达实现云上资源高可用.提升系统安全性与稳定性,为物联亿达提供了扎实的数字化基础. 本文分享自华为云社区<云享·案例丨打造数智物流底 ...