[转帖]TiKV 多副本丢失以及修复实践
https://tidb.net/blog/ad45bad9#6%E6%80%BB%E7%BB%93
1实验目的
随着tidb使用场景的越来越多,接入的业务越来越重要,不由得想试验下tidb组件的高可用性以及故障或者灾难如何恢复,恢复主要涉及的是pd组件和tikv组件,本文主要涉及tikv组件,
pd组件请参考另外一篇文章《pd集群多副本数据丢失以及修复实践》pd集群多副本数据丢失以及修复实践
2试验环境
2.1版本以及部署拓扑:
tidb版本:5.2.1
部署方式:tiup
部署拓扑
$ cat tidb-test.yaml
global:
user: "tidb"
ssh_port: 22
deploy_dir: "/data/tidb/tidb-deploy"
data_dir: "/data/tidb/tidb-data"
pd_servers:
- host: 10.12.16.225
- host: 10.12.16.226
- host: 10.12.16.227
tidb_servers:
- host: 10.12.16.225
- host: 10.12.16.226
- host: 10.12.16.227
tikv_servers:
- host: 10.12.16.224
- host: 10.12.16.225
- host: 10.12.16.226
- host: 10.12.16.227
- host: 10.12.16.228
monitoring_servers:
- host: 10.12.16.228
grafana_servers:
- host: 10.12.16.228
alertmanager_servers:
- host: 10.12.16.228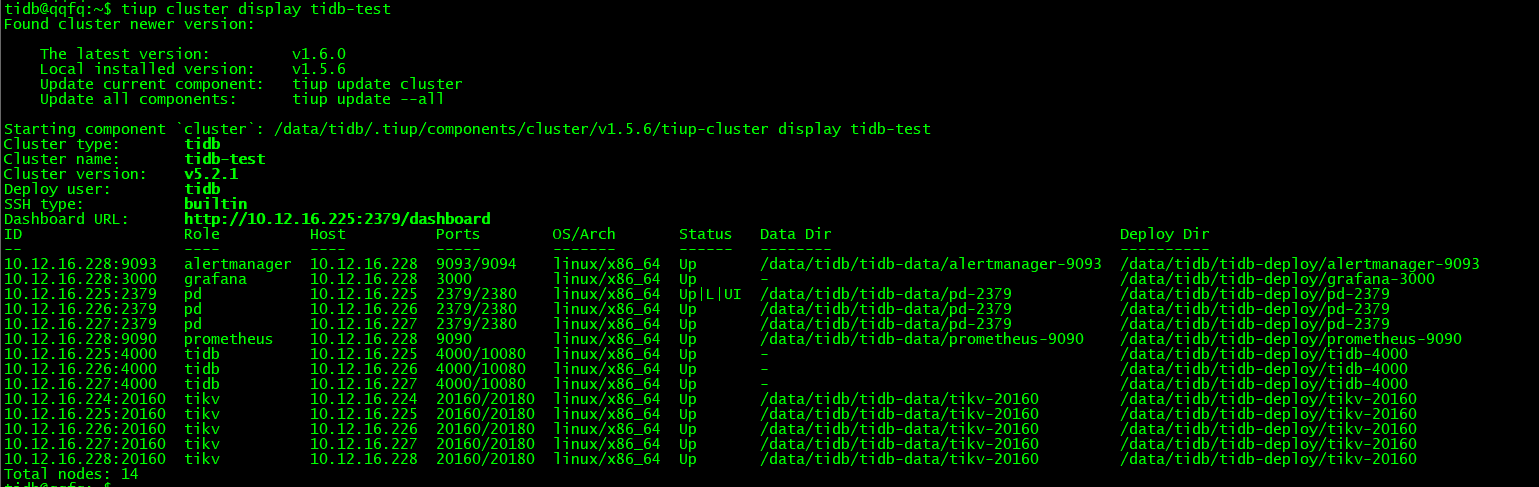
5*TIKV
replica=3
温馨提示:
防止tiup部署后,在破坏掉tikv实例后,tikv-server被自动拉起来,影响试验效果,需要做如下修改
1、在/etc/systemd/system/tikv-20160.service中去掉 Restart=always或者改Restart=no,
2、执行systemctl daemon-reload 重新加载
2.2查看测试表数据
CREATE TABLE `t_test` (
`name` varchar(200) DEFAULT '',
`honor` varchar(200) DEFAULT ''
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin /*T! SHARD_ROW_ID_BITS=4 PRE_SPLIT_REGIONS=4 */
mysql> desc t_test;
+-------+--------------+------+------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+------+---------+-------+
| name | varchar(200) | YES | | | |
| honor | varchar(200) | YES | | | |
+-------+--------------+------+------+---------+-------+
2 rows in set (0.00 sec)
mysql> select count(*) from t_test;
+----------+
| count(*) |
+----------+
| 1024288 |
+----------+
1 row in set (3.68 sec)3单副本损毁及修复
过程略
提示:
此种场景也是最常见的场景,replica>=3的时候,不会影响业务读写,也不会丢失数据,只需要扩容新TiKV节点,缩容下线故障节点即可。
如果是3*TiKV集群,必须只能先扩容,否则此时即便强制缩容下线故障节点,数据也不会发生replica均衡调度,因为无法补齐三副本。
4双副本同时损毁及修复
4.1查看测试表region分布
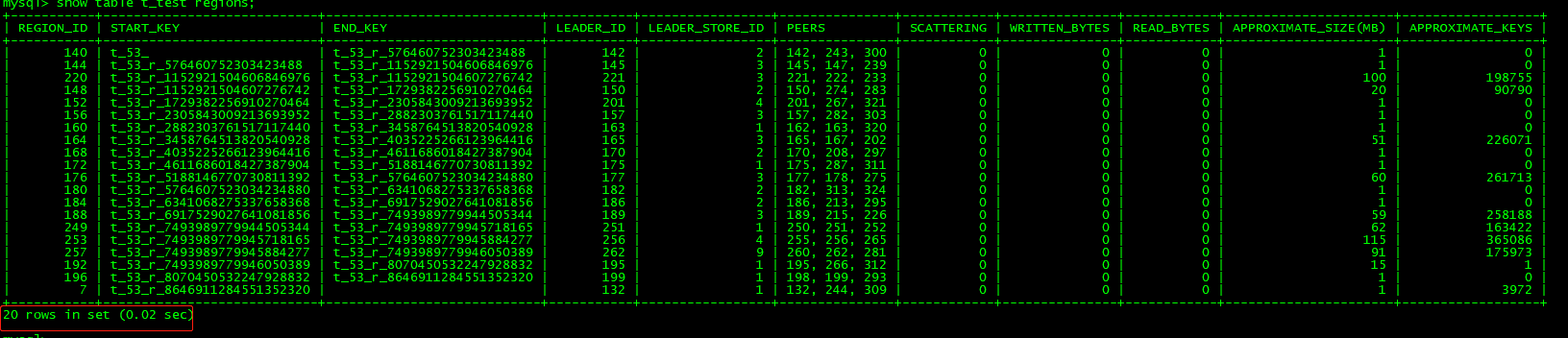
mysql> select STORE_ID,ADDRESS,LEADER_COUNT,REGION_COUNT from information_schema.TIKV_STORE_STATUS ;
+----------+--------------------+--------------+--------------+
| STORE_ID | ADDRESS | LEADER_COUNT | REGION_COUNT |
+----------+--------------------+--------------+--------------+
| 1 | 10.12.16.228:20160 | 12 | 25 |
| 2 | 10.12.16.225:20160 | 11 | 33 |
| 4 | 10.12.16.226:20160 | 9 | 14 |
| 3 | 10.12.16.227:20160 | 6 | 38 |
| 9 | 10.12.16.224:20160 | 7 | 25 |
+----------+--------------------+--------------+--------------+
5 rows in set (0.01 sec)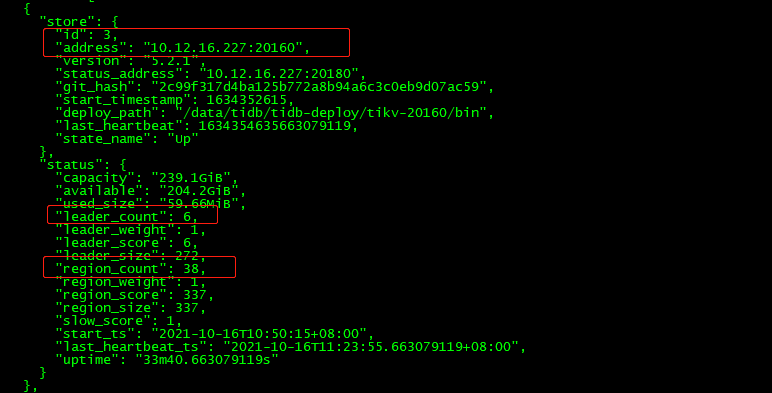
4.2模拟2个tikv同时损坏
同时损坏的TiKV节点是10.12.16.227:20160和10.12.16.228:20160
在10.12.16.227(store_id=3)和10.12.16.228(store_id=1)上分别执行
$ cd /data/tidb/tidb-data/
$ ls
monitor-9100 pd-2379 tikv-20160
$ rm -rf tikv-20160
$ ls
monitor-9100 pd-2379查看集群状态:

查看store_id=3和store_id=1的状态:
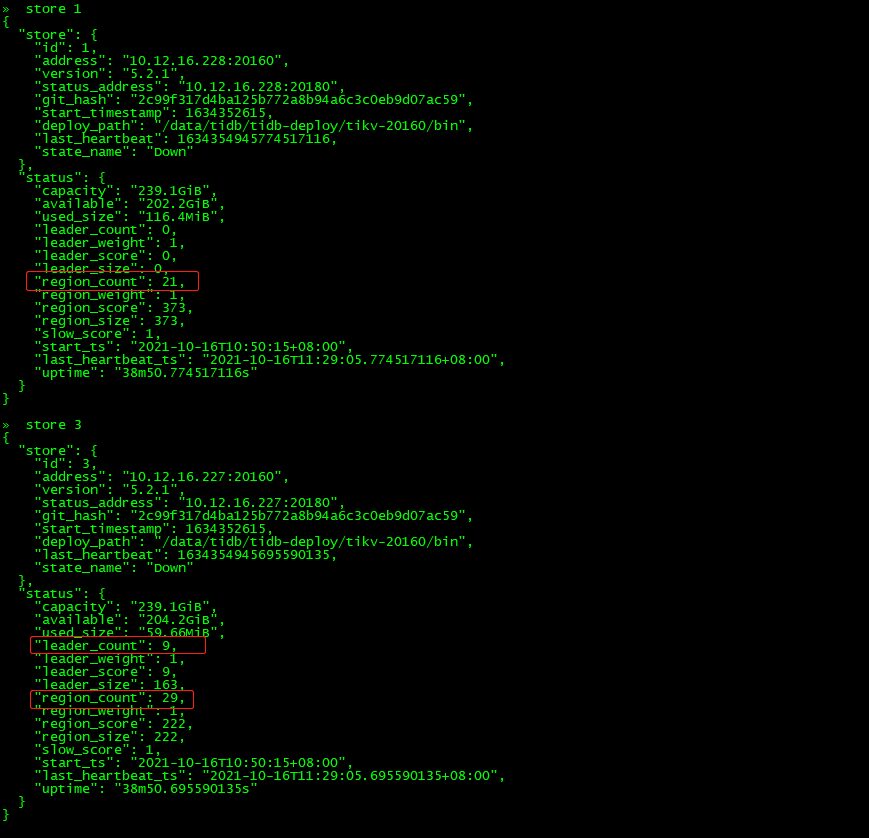
可以发现30分钟过后(store的状态从disconnecting–》down),store 1和3上的region的leader和replica还存在,并不是因为store是down状态,其上面的regionleader和replica进行切换和调度,那是因为部分region同时失去两个副本,导致无法发生leader选举。
mysql> select count(*) from t_test;
ERROR 9002 (HY000): TiKV server timeout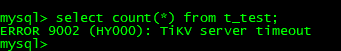
tidb查询发现hang住直到超时
4.3修复tidb集群
4.3.1关闭调度
关闭调度原因:防止恢复期间出现其他的异常情况
关闭调度方法:config set region-schedule-limit、replica-schedule-limit、leader-schedule-limit、merge-schedule-limit 这4个值
» config set region-schedule-limit 0
» config set replica-schedule-limit 0
» config set leader-schedule-limit 0
» config set merge-schedule-limit 04.3.2查询出大多数副本在故障tikv上的region id
检查大于等于一半副本数在故障节点(store_id in(1,3))上的region,并记录它们的region id
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total |map(if .==(1,3) then . else empty end)|length>=$total-length)}'
4.3.3关闭正常的tikv节点
$ tiup cluster stop tidb-test -N 10.12.16.224:20160
$ tiup cluster stop tidb-test -N 10.12.16.225:20160
$ tiup cluster stop tidb-test -N 10.12.16.226:20160
4.3.4清理故障store的region
清理方法:
在正常的tikv(已经关闭掉)上执行命令:
$ ./tikv-ctl --data-dir /data/tidb/tidb-data/tikv-20160 unsafe-recover remove-fail-stores -s 1,3 --all-regions执行命令在输出的结尾有success字样,说明执行成功
清理原因:在正常tikv上清理掉region peer落在故障tikv(1和3)peer
4.3.5重启pd集群
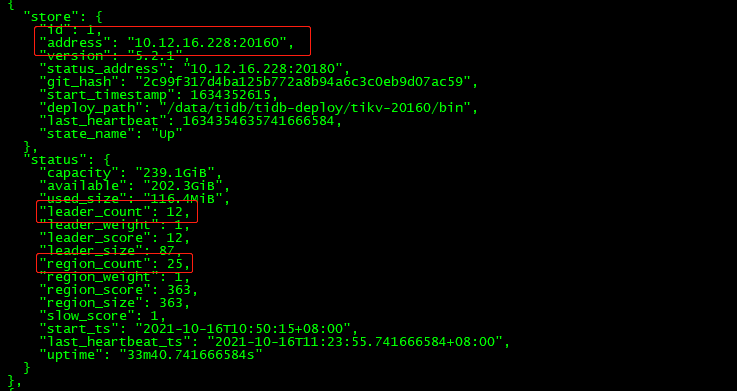
$ tiup cluster restart tidb-test -R pd查看store 1和store 3
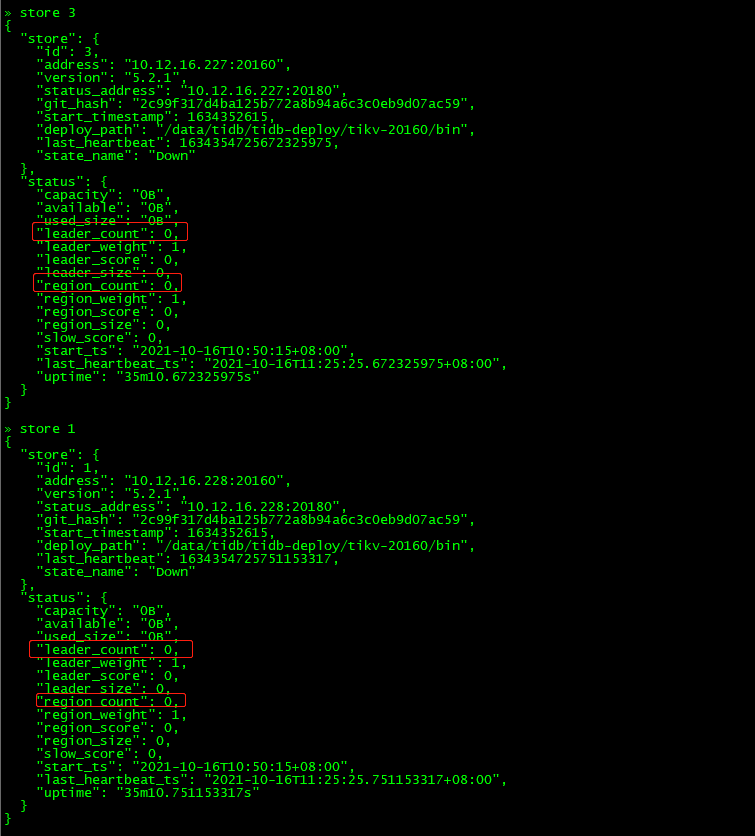
发现上面的leader_count和region_count都变成0,如果pd集群不重启,则不会消失。
4.3.6启动正常的tikv节点
$ tiup cluster start tidb-test -N 10.12.16.224:20160
$ tiup cluster start tidb-test -N 10.12.16.225:20160
$ tiup cluster start tidb-test -N 10.12.16.226:20160
查看副本数为2的region:
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length==2) } '{"id":36,"peer_stores":[2,9]}
{"id":140,"peer_stores":[2,9]}
{"id":249,"peer_stores":[2,4]}
{"id":46,"peer_stores":[2,9]}
{"id":168,"peer_stores":[2,9]}
{"id":176,"peer_stores":[2,9]}
{"id":188,"peer_stores":[4,9]}
{"id":48,"peer_stores":[9,2]}
{"id":184,"peer_stores":[2,9]}
{"id":26,"peer_stores":[2,9]}
{"id":152,"peer_stores":[4,2]}
{"id":52,"peer_stores":[2,4]}
{"id":40,"peer_stores":[4,2]}
{"id":253,"peer_stores":[4,9]}
{"id":44,"peer_stores":[2,9]}查看只有单副本的region:
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length==1) } '{"id":42,"peer_stores":[2]}
{"id":62,"peer_stores":[9]}
{"id":192,"peer_stores":[9]}
{"id":180,"peer_stores":[2]}
{"id":196,"peer_stores":[2]}
{"id":60,"peer_stores":[9]}
{"id":160,"peer_stores":[2]}
{"id":164,"peer_stores":[4]}
{"id":54,"peer_stores":[9]}
{"id":172,"peer_stores":[2]}
{"id":220,"peer_stores":[2]}
{"id":7,"peer_stores":[9]}
{"id":50,"peer_stores":[9]}
{"id":144,"peer_stores":[9]}
{"id":156,"peer_stores":[2]}
{"id":38,"peer_stores":[2]}
{"id":56,"peer_stores":[2]}4.3.7打开调度
config set region-schedule-limit 2048
config set replica-schedule-limit 64
config set leader-schedule-limit 4
config set merge-schedule-limit 84.3.8验证数据
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total |map(if .==(1,3) then . else empty end)|length>=$total-length)}' 输出为空
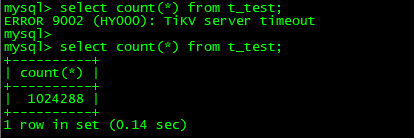
数据已经可以查询,并且数据没有丢失
查看只有单副本的region:

查看副本数为2的region:

4.3.9清理收尾
发现store 1和3还是存在(状态为Down),需要在集群中剔除掉
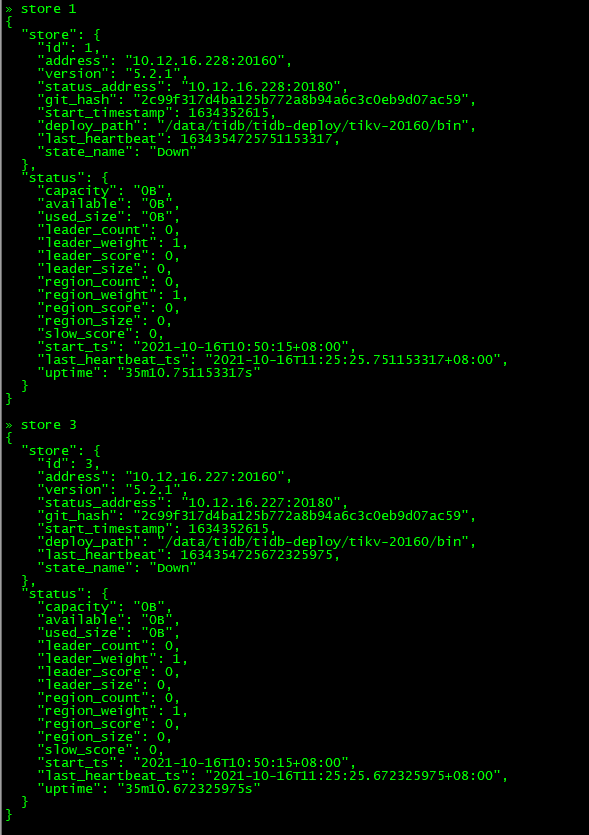
删除掉store 1和3
» store delete 1
Success!
» store delete 3
Success!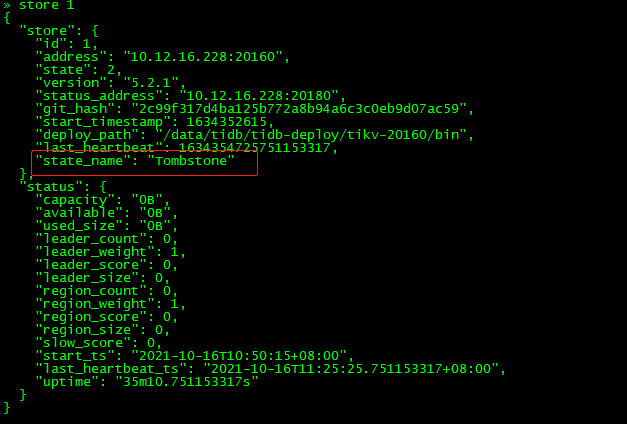

$ tiup cluster prune tidb-test$ tiup cluster display tidb-test
发现227和228已经不在集群
至此,双副本同时丢失的情景已经修复完毕
5三副本同时损毁及修复
5.1查看测试表region分布
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length==3) } '{"id":220,"peer_stores":[2,9,497041]}
{"id":249,"peer_stores":[2,4,497042]}
{"id":7,"peer_stores":[9,497041,497042]}
{"id":36,"peer_stores":[2,9,497041]}
{"id":140,"peer_stores":[2,497042,497041]}
{"id":144,"peer_stores":[9,497042,2]}
{"id":156,"peer_stores":[2,4,497042]}
{"id":168,"peer_stores":[2,9,497042]}
{"id":176,"peer_stores":[2,497042,4]}
{"id":188,"peer_stores":[497042,9,497041]}
{"id":38,"peer_stores":[2,9,497041]}
{"id":46,"peer_stores":[9,2,497041]}
{"id":50,"peer_stores":[9,497041,497042]}
{"id":48,"peer_stores":[2,9,497041]}
{"id":56,"peer_stores":[9,497041,497042]}
{"id":184,"peer_stores":[2,9,497041]}
{"id":152,"peer_stores":[4,9,497041]}
{"id":192,"peer_stores":[9,497042,497041]}
{"id":26,"peer_stores":[497042,497041,2]}
{"id":42,"peer_stores":[2,9,497042]}
{"id":62,"peer_stores":[9,497041,497042]}
{"id":180,"peer_stores":[2,9,497042]}
{"id":196,"peer_stores":[2,497041,497042]}
{"id":22,"peer_stores":[4,497042,9]}
{"id":52,"peer_stores":[4,497042,9]}
{"id":148,"peer_stores":[4,9,497041]}
{"id":40,"peer_stores":[4,9,497042]}
{"id":160,"peer_stores":[2,9,497041]}
{"id":164,"peer_stores":[4,497041,497042]}
{"id":253,"peer_stores":[4,2,497042]}
{"id":257,"peer_stores":[4,9,497041]}
{"id":34,"peer_stores":[4,497041,497042]}
{"id":58,"peer_stores":[4,497042,9]}
{"id":60,"peer_stores":[9,497041,497042]}
{"id":44,"peer_stores":[2,9,497041]}
{"id":54,"peer_stores":[9,497041,497042]}
{"id":172,"peer_stores":[497041,9,497042]}mysql> select count(*) from t_test;
+----------+
| count(*) |
+----------+
| 1024288 |
+----------+
1 row in set (0.14 sec)
mysql> select count(*) from t_test;
+----------+
| count(*) |
+----------+
| 1024288 |
+----------+
1 row in set (0.14 sec)5.2模拟3个(所有副本)tikv同时损坏
模拟10.12.16.226:20160 10.12.16.227:20160 10.12.16.228:20160三个tikv节点同时挂掉
在226、227、228上执行:
$ cd /data/tidb/tidb-data
$ ls
monitor-9100 pd-2379 tikv-20160
$ rm -rf tikv-20160
$ ls
monitor-9100 pd-2379查看集群状态:
$ tiup cluster display tidb-test
5.3修复tidb集群
5.3.1关闭调度
config set region-schedule-limit 0
config set replica-schedule-limit 0
config set leader-schedule-limit 0
config set merge-schedule-limit 05.3.2查询出三个(所有)副本在故障tikv上的region id
mysql> select STORE_ID,ADDRESS,LEADER_COUNT,REGION_COUNT,STORE_STATE_NAME from information_schema.TIKV_STORE_STATUS order by STORE_STATE_NAME;
+----------+--------------------+--------------+--------------+------------------+
| STORE_ID | ADDRESS | LEADER_COUNT | REGION_COUNT | STORE_STATE_NAME |
+----------+--------------------+--------------+--------------+------------------+
| 497041 | 10.12.16.228:20160 | 2 | 25 | Disconnected |
| 497042 | 10.12.16.227:20160 | 2 | 26 | Disconnected |
| 4 | 10.12.16.226:20160 | 12 | 13 | Disconnected |
| 2 | 10.12.16.225:20160 | 11 | 19 | Up |
| 9 | 10.12.16.224:20160 | 10 | 28 | Up |
+----------+--------------------+--------------+--------------+------------------+
5 rows in set (0.00 sec)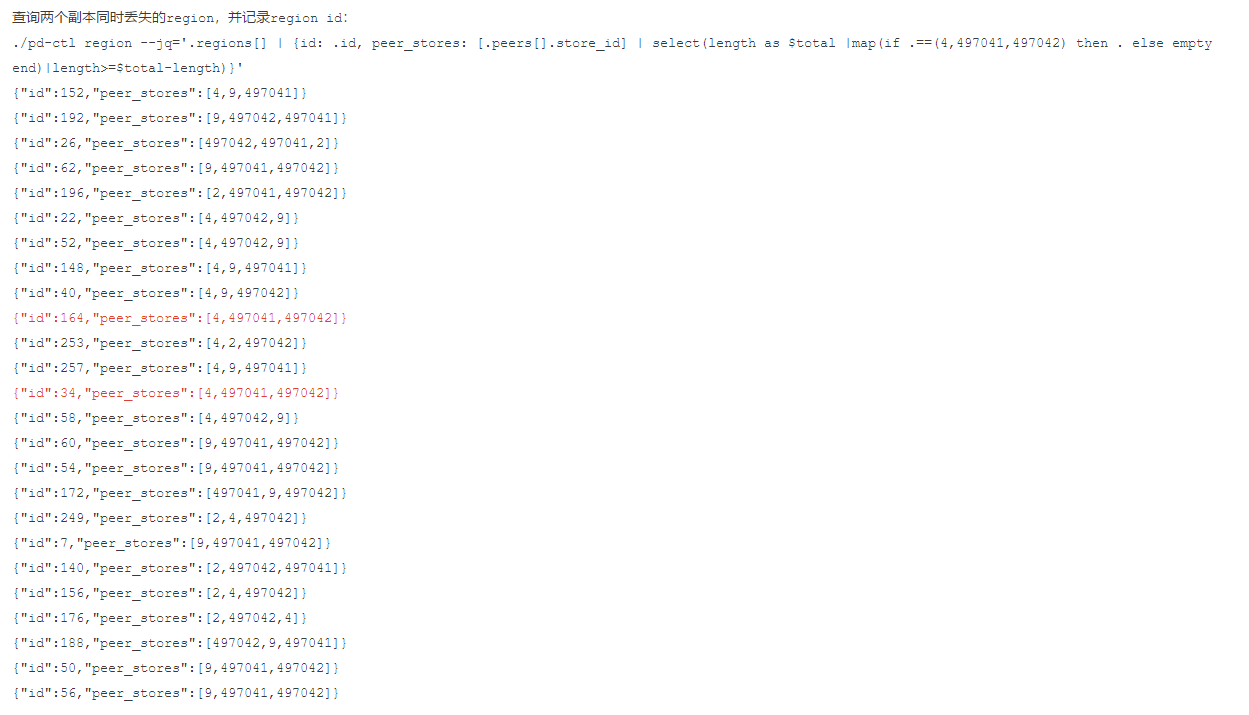
5.3.3关闭正常的tikv节点
$ tiup cluster stop tidb-test -N 10.12.16.224:20160
$ tiup cluster stop tidb-test -N 10.12.16.225:20160
$ tiup cluster display tidb-test
5.3.4清理故障store的region
清理方法:
在正常的tikv(已经关闭掉)上执行命令:
$ ./tikv-ctl --data-dir /data/tidb/tidb-data/tikv-20160 unsafe-recover remove-fail-stores -s 4,497041,497042 --all-regions执行命令在输出的结尾有success字样,说明执行成功
清理原因:在正常tikv上清理掉region peer落在故障tikv(4,497041,497042)peer
5.3.5重启pd集群
$ tiup cluster restart tidb-test -R pd5.3.6启动正常的tikv节点
$ tiup cluster start tidb-test -N 10.12.16.224:20160
$ tiup cluster start tidb-test -N 10.12.16.225:20160
$ tiup cluster display tidb-test 
5.3.7打开调度
config set region-schedule-limit 2048
config set replica-schedule-limit 64
config set leader-schedule-limit 4
config set merge-schedule-limit 85.3.8验证数据
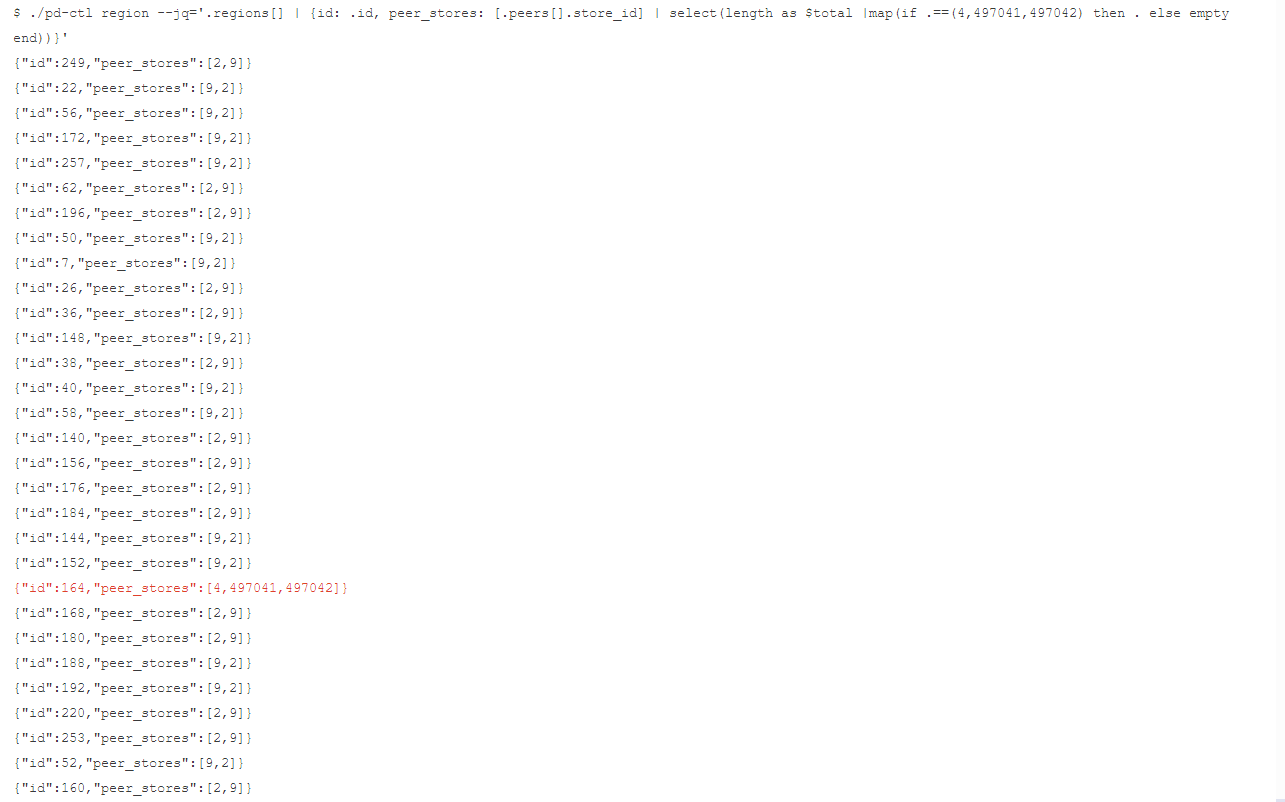
mysql> select count(*) from t_test;
ERROR 9005 (HY000): Region is unavailable
5.3.9补偿所有副本都丢失的region
5.3.9.1查询所有副本都丢失的region,并记录region id
$ ./pd-ctl region --jq='.regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length as $total |map(if .==(4,497041,497042) then . else empty end)|length>$total-length)}'{"id":164,"peer_stores":[4,497041,497042]}
5.3.9.2停止实例
停止10.12.16.225:20160 tikv实例(可以是其他任意正常的tikv实例)
5.3.9.3根据上面查询出丢失的region id创建空region
$ ./tikv-ctl --data-dir /data/tidb/tidb-data/tikv-20160 recreate-region -p 127.0.0.1:2379 -r 164命令输出结尾有success字样,说明创建成功
5.3.9.4验证数据
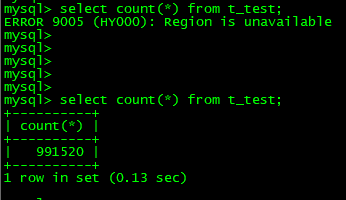
原来总数为1024288,发现数据有丢失
5.3.10收尾
$ tiup cluster display tidb-test 
» store delete 4
Success!
» store delete 497041
Success!
» store delete 497042
Success!如果通过tiup cluster display tidb-test执行命令发现226、227、228上的store状态为up,说明开启了自动拉起
$ tiup cluster prune tidb-test6总结
1、如果region的单个副本丢失(小于replica一半的情况下),集群是不会丢失数据,此场景是绝大多数用户tikv挂掉场景;
2、如果region多副本(副本数大于replica/2)丢失,如果开启sync-log=true则不会丢失数据,否则可能会丢失数据;
3、如果region所有副本丢失,此时必定会丢失数据,需要进行破坏性修复;
4、如果单机多tikv实例部署,一定需要打label,否则主机挂掉,region的多副本或者全部副本可能会丢失,从而导致丢失数据;
[转帖]TiKV 多副本丢失以及修复实践的更多相关文章
- XenServer 5.5 断电重启虚拟机磁盘丢失的修复
1.现象 公司云平台使用的是XenServer 5.5,版本比较老了.最近几天因为机房改造,导致云环境断电,重启之后发现有2台机器无法ping到,所以再次重启,登录修复网卡,最后发现无法用XenCen ...
- HBase2.0 meta信息丢失的修复方法
在HBase入库日志中发现有一个表入库失败,检查HBase服务端后发现该表的meta信息丢失了: 而HDFS上的region还在: 而HBCK工具不支持HBase2.0版本,只好自己写一个修复工具.网 ...
- 微软官方出的各种dll丢失的修复工具
例如 :因为计算机中丢失 api-ms-win-crt-runtime-l1-1-0.dll.尝试重新安装该程序以解决此问题. 软件名称: Visual C++ Redistributable for ...
- grub2配置文件丢失如何修复
实验操作准备 此步骤因实验需要所做,系统开机属grub界面无需此步! lsblk命令为了查看根分区挂载在什么位置 rm -rf /boot/grub2/grub.cfg命令为删除grub2配置文件到达 ...
- grub丢失的修复
使用安装光盘进入rescure模式,经过配置后进入一个bashbash# grubgrub> root (hd0,6)grub> setup (hd0)重启即可
- 微信 SQLite 数据库修复实践
1.前言 众所周知,微信在后台服务器不保存聊天记录,微信在移动客户端所有的聊天记录都存储在一个 SQLite 数据库中,一旦这个数据库损坏,将会丢失用户多年的聊天记录.而我们监控到现网的损坏率是0.0 ...
- Android热修复实践应用--AndFix
一直关注App的热修复的技术发展,之前做的应用也没用使用到什么热修复开源框架.在App的热修复框架没有流行之前,做的应用上线后发现一个小小的Bug,就要马上发一个新的版本.我亲身经历过一周发两个版本, ...
- atitit.修复xp 操作系统--重装系统--保留原来文件不丢失
atitit.修复xp 操作系统--重装系统--保留原来文件不丢失 1. 修复目标...保持c盘文件,恢复system文件走ok... 1 2. 重装系统以前的操作 1 2.1. 避免格式化c盘/gh ...
- SQL Server 损坏修复
目录: 一. 常见错误解读 二. DBCC CHECKDB 三 .不同部位损坏的应对 四. Database Mirroring和AlwaysOn的页面自动修复功能 一 常见错误解读 SQL Serv ...
- 修复发生“由于数据移动,未能继续以 NOLOCK 方式扫描”错误的数据库
最近在系统运行中发现了一个错误,错误信息如下: 错误信息:查询A201412C20568单证信息错误 ---> System.Data.OleDb.OleDbException: 由于数据移动, ...
随机推荐
- 扩展中国剩余定理(Excrt)笔记
扩展中国剩余定理(excrt) 本来应该先学中国剩余定理的.但是有了扩展中国剩余定理,朴素的 CRT 就没用了. 扩展中国剩余定理用来求解如下形式的同余方程组: \[\begin{cases} x \ ...
- LeetCode DFS、BFS篇(102、200、111、752)
102. 二叉树的层序遍历 给你一个二叉树,请你返回其按 层序遍历 得到的节点值. (即逐层地,从左到右访问所有节点). 示例: 二叉树:[3,9,20,null,null,15,7], 3 / 9 ...
- 从部署和运维说说DLI(1)
DLI是支持多模引擎的Serverless大数据计算服务,其很好的实现了Serverless的特性: 1. 弱化了存储和计算之间的联系: 2. 代码的执行不再需要手动分配资源: 3. 按使用量计费 ...
- Tarjan:这个算法大神
摘要:图的算法是进行静态分析的基础数据算法,如何提高图的分析效率,就需要对图的算法有进一步的认识. 1. 引言 在静态分析技术中, 我们常用会将代码转成抽象语法树(AST), 然后采用深度遍历(DFS ...
- 不信谣不传谣,亲自动手验证ModelBox推理是否真的“高性能”
摘要:"高性能推理"是ModelBox宣传的主要特性之一,不信谣不传谣的我决定通过原生API和ModelBox实现相同案例进行对比,看一下ModelBox推理是否真的"高 ...
- 个性化联邦学习算法框架发布,赋能AI药物研发
摘要:近期,中科院上海药物所.上海科技大学联合华为云医疗智能体团队,在Science China Life Sciences 发表题为"Facing Small and Biased Dat ...
- 小熊派:用OpenHarmory3.0点亮LED
摘要:作为一个代表性的完整的开发,本案例可以分成3大部分:代码文件的规划,LED灯的驱动开发,点亮LED的业务开发. 本文分享自华为云社区<在小熊派Micro上用OpenHarmory3.0点亮 ...
- 从原理带你掌握Spring MVC拦截处理器知识
摘要:SpringWebMVC的处理器拦截器,类似于Servlet开发中的过滤器Filter,用于处理器进行预处理和后处理. 本文分享自华为云社区<不讲废话,全程干货,0基础带你学习Spring ...
- 一起玩转LiteOS组件:Pixman
摘要:本文将以Pixman Demo为例,详细说明Pixman的功能. 本文分享自华为云社区<LiteOS组件尝鲜-玩转Pixman>,作者:Lionlace. 基本介绍 Pixman是由 ...
- Windows 2016 安装 Jenkins
Docker Jenkins 安装配置 Windows 2016 安装 Jenkins Jenkins + SVN Jenkins + SVN/Git + Maven + Docker + 阿里云镜像 ...