Nebula Graph 源码解读系列 | Vol.03 Planner 的实现

上篇我们讲到 Validator 会将由 Parser 生成的抽象语法树(AST)转化为执行计划,这次,我们来讲下执行计划是如何生成的。
概述
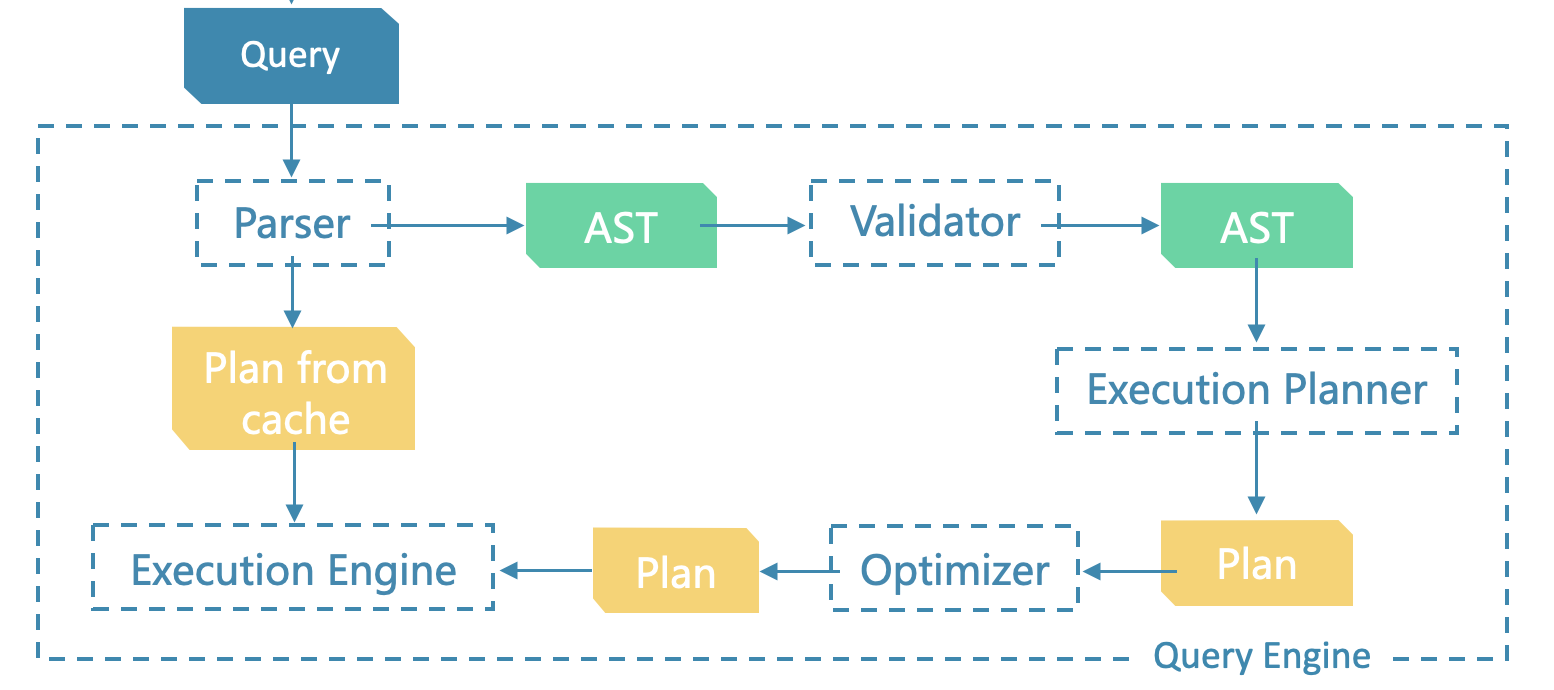
Planner 是执行计划(Execution Plan)生成器,它会根据 Validator 校验过、语义合法的查询语法树生成可供执行器(Executor)执行的未经优化的执行计划,而该执行计划会在之后交由 Optimizer 生成一个优化的执行计划,并最终交给 Executor 执行。执行计划由一系列节点(PlanNode)组成。
源码目录结构
src/planner
├── CMakeLists.txt
├── match/
├── ngql/
├── plan/
├── Planner.cpp
├── Planner.h
├── PlannersRegister.cpp
├── PlannersRegister.h
├── SequentialPlanner.cpp
├── SequentialPlanner.h
└── test
其中,Planner.h中定义了 SubPlan 的数据结构和 planner 的几个接口。
struct SubPlan {
// root and tail of a subplan.
PlanNode* root{nullptr};
PlanNode* tail{nullptr};
};
PlannerRegister 负责注册可用的 planner,Nebula Graph 目前注册了 SequentialPlanner、PathPlanner、LookupPlanner、GoPlanner、MatchPlanner。
SequentialPlanner 对应的语句是 SequentialSentences,而 SequentialSentence 是由多个 Sentence 及间隔分号组成的组合语句。每个语句又可能是 GO/LOOKUP/MATCH等语句,所以 SequentialPlanner 是通过调用其他几个语句的 planner 来生成多个 plan,并用 Validator::appendPlan 将它们首尾相连。
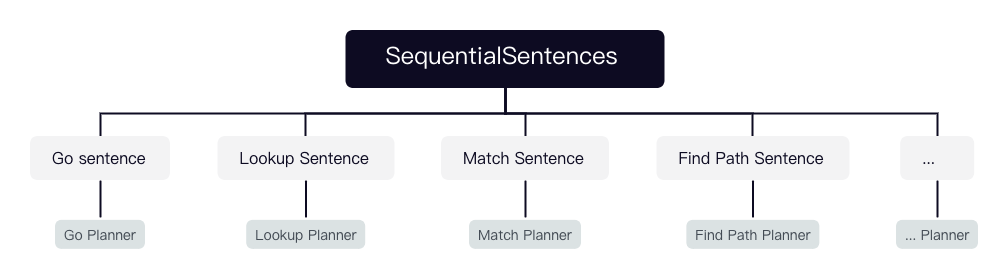
match 目录定义了 openCypher 相关语句及子句(如 MATCH、UNWIND、WITH、RETURN、WHERE、ORDER BY、SKIP、LIMIT)的 planner 和 SubPlan 之间的连接策略等。SegmentsConnector 根据 SubPlan 之间的关系使用相应的连接策略(AddInput、addDependency、innerJoinSegments 等)将它们首尾连接成一个完整的 plan。
src/planner/match
├── AddDependencyStrategy.cpp
├── AddDependencyStrategy.h
├── AddInputStrategy.cpp
├── AddInputStrategy.h
├── CartesianProductStrategy.cpp
├── CartesianProductStrategy.h
├── CypherClausePlanner.h
├── EdgeIndexSeek.h
├── Expand.cpp
├── Expand.h
├── InnerJoinStrategy.cpp
├── InnerJoinStrategy.h
├── LabelIndexSeek.cpp
├── LabelIndexSeek.h
├── LeftOuterJoinStrategy.h
├── MatchClausePlanner.cpp
├── MatchClausePlanner.h
├── MatchPlanner.cpp
├── MatchPlanner.h
├── MatchSolver.cpp
├── MatchSolver.h
├── OrderByClausePlanner.cpp
├── OrderByClausePlanner.h
├── PaginationPlanner.cpp
├── PaginationPlanner.h
├── PropIndexSeek.cpp
├── PropIndexSeek.h
├── ReturnClausePlanner.cpp
├── ReturnClausePlanner.h
├── SegmentsConnector.cpp
├── SegmentsConnector.h
├── SegmentsConnectStrategy.h
├── StartVidFinder.cpp
├── StartVidFinder.h
├── UnionStrategy.h
├── UnwindClausePlanner.cpp
├── UnwindClausePlanner.h
├── VertexIdSeek.cpp
├── VertexIdSeek.h
├── WhereClausePlanner.cpp
├── WhereClausePlanner.h
├── WithClausePlanner.cpp
├── WithClausePlanner.h
├── YieldClausePlanner.cpp
└── YieldClausePlanner.h
ngql 目录定义了 nGQL 语句相关的 planner(如 GO、LOOKUP、FIND PATH)
src/planner/ngql
├── GoPlanner.cpp
├── GoPlanner.h
├── LookupPlanner.cpp
├── LookupPlanner.h
├── PathPlanner.cpp
└── PathPlanner.h
plan 目录定义了 7 大类,共计 100 多种 Plan Node。
src/planner/plan
├── Admin.cpp
├── Admin.h
├── Algo.cpp
├── Algo.h
├── ExecutionPlan.cpp
├── ExecutionPlan.h
├── Logic.cpp
├── Logic.h
├── Maintain.cpp
├── Maintain.h
├── Mutate.cpp
├── Mutate.h
├── PlanNode.cpp
├── PlanNode.h
├── Query.cpp
├── Query.h
└── Scan.h
部分节点说明:
- Admin 是数据库管理相关节点
- Algo 是路径、子图等算法相关节点
- Logic 是逻辑控制节点,如循环、二元选择等
- Maintain 是 schema 相关节点
- Mutate 是 DML 相关节点
- Query 是查询计算相关的节点
- Scan 是索引扫描相关节点
每个 PlanNode 在 Executor(执行器)阶段会生成相应的 executor,每种 executor 负责一个具体的功能。
eg. GetNeighbors 节点:
static GetNeighbors* make(QueryContext* qctx,
PlanNode* input,
GraphSpaceID space,
Expression* src,
std::vector<EdgeType> edgeTypes,
Direction edgeDirection,
std::unique_ptr<std::vector<VertexProp>>&& vertexProps,
std::unique_ptr<std::vector<EdgeProp>>&& edgeProps,
std::unique_ptr<std::vector<StatProp>>&& statProps,
std::unique_ptr<std::vector<Expr>>&& exprs,
bool dedup = false,
bool random = false,
std::vector<storage::cpp2::OrderBy> orderBy = {},
int64_t limit = -1,
std::string filter = "")
GetNeighbors 是存储层边的 kv 的语义上的封装:它根据给定类型边的起点,找到边的终点。在找边过程中,GetNeighbors 可以获取边上属性(edgeProps)。因为出边随起点存储在同一个 partition(数据切片)上,所以我们还可以方便地获得边上起点的属性(vertexProps)。
Aggregate 节点:
static Aggregate* make(QueryContext* qctx,
PlanNode* input,
std::vector<Expression*>&& groupKeys = {},
std::vector<Expression*>&& groupItems = {})
Aggregate 节点为聚合计算节点,它根据 groupKeys 作分组,根据 groupItems 做聚合计算作为组内值。
Loop 节点:
static Loop* make(QueryContext* qctx,
PlanNode* input,
PlanNode* body = nullptr,
Expression* condition = nullptr);
loop 为循环节点,它会一直执行 body 到最近一个 start 节点之间的 PlanNode 片段直到 condition 值为 false。
InnerJoin 节点:
static InnerJoin* make(QueryContext* qctx,
PlanNode* input,
std::pair<std::string, int64_t> leftVar,
std::pair<std::string, int64_t> rightVar,
std::vector<Expression*> hashKeys = {},
std::vector<Expression*> probeKeys = {})
InnerJoin 节点对两个表(Table、DataSet)做内联,leftVar 和 rightVar 分别用来引用两个表。
入口函数
planner 入口函数是 Validator::toPlan
Status Validator::toPlan() {
auto* astCtx = getAstContext();
if (astCtx != nullptr) {
astCtx->space = space_;
}
auto subPlanStatus = Planner::toPlan(astCtx);
NG_RETURN_IF_ERROR(subPlanStatus);
auto subPlan = std::move(subPlanStatus).value();
root_ = subPlan.root;
tail_ = subPlan.tail;
VLOG(1) << "root: " << root_->kind() << " tail: " << tail_->kind();
return Status::OK();
}
具体步骤
1.调用 getAstContext()
首先调用 getAstContext() 获取由 validator 校验并重写过的 AST 上下文,这些 context 相关数据结构定义在 src/context中。
src/context/ast
├── AstContext.h
├── CypherAstContext.h
└── QueryAstContext.h
struct AstContext {
QueryContext* qctx; // 每个查询请求的 context
Sentence* sentence; // query 语句的 ast
SpaceInfo space; // 当前 space
};
CypherAstContext 中定义了 openCypher 相关语法的 ast context,QueryAstContext 中定义了 nGQL 相关语法的 ast context。
2.调用Planner::toPlan(astCtx)
然后调用 Planner::toPlan(astCtx),根据 ast context 在 PlannerMap 中找到语句对应注册过的 planner,然后生成相应的执行计划。
每个 Plan 由一系列 PlanNode 组成,PlanNode 之间有执行依赖和数据依赖两大关系。
执行依赖:从执行顺序上看,plan 是一个有向无环图,节点间的依赖关系在生成 plan 时确定。在执行阶段,执行器会对每个节点生成一个对应的算子,并且从根节点开始调度,此时发现此节点依赖其他节点,就先递归调用依赖的节点,一直找到没有任何依赖的节点(Start 节点),然后开始执行,执行此节点后,继续执行此节点被依赖的其他节点,一直到根节点为止。
数据依赖:节点的数据依赖一般和执行依赖相同,即来自前面一个调度执行的节点的输出。有的节点,如:InnerJoin 会有多个输入,那么它的输入可能是和它间隔好几个节点的某个节点的输出。
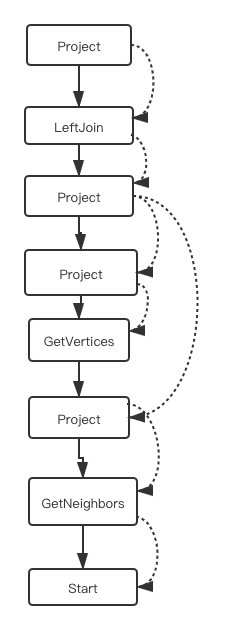
(实线为执行依赖,虚线为数据依赖)
举个例子
我们以 MatchPlanner 为例,来看一个执行计划是如何生成的:
语句:
MATCH (v:player)-[:like*2..4]-(v2:player)\
WITH v, v2.age AS age ORDER BY age WHERE age > 18\
RETURN id(v), age
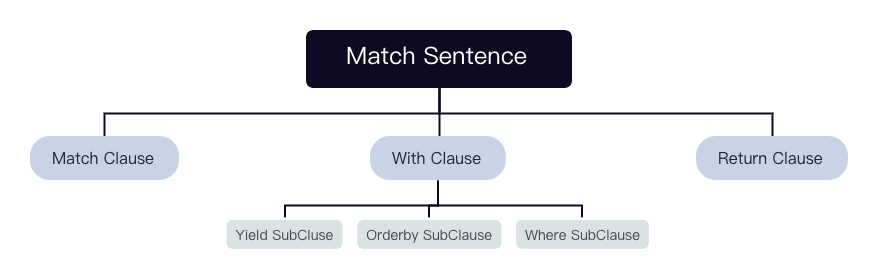
该语句经过 MatchValidator 的校验和重写后会输出一个 context 组成的 tree。
=>
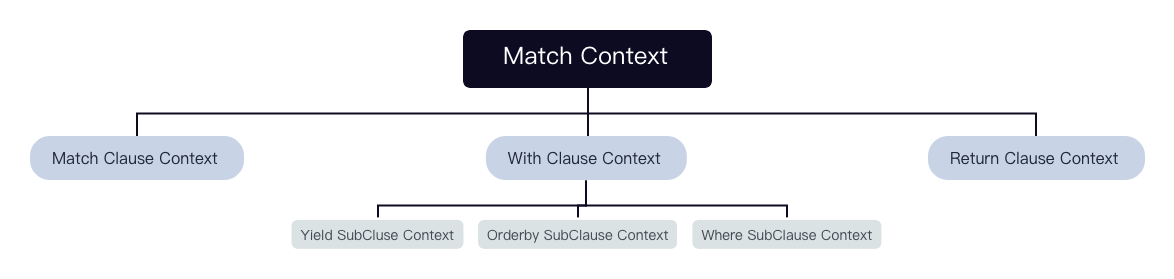
每个 Clause 及 SubClause 对应一个 context:
enum class CypherClauseKind : uint8_t {
kMatch,
kUnwind,
kWith,
kWhere,
kReturn,
kOrderBy,
kPagination,
kYield,
};
struct CypherClauseContextBase : AstContext {
explicit CypherClauseContextBase(CypherClauseKind k) : kind(k) {}
virtual ~CypherClauseContextBase() = default;
const CypherClauseKind kind;
};
struct MatchClauseContext final : CypherClauseContextBase {
MatchClauseContext() : CypherClauseContextBase(CypherClauseKind::kMatch) {}
std::vector<NodeInfo> nodeInfos; // pattern 中涉及的顶点信息
std::vector<EdgeInfo> edgeInfos; // pattern 中涉及的边信息
PathBuildExpression* pathBuild{nullptr}; // 构建 path 的表达式
std::unique_ptr<WhereClauseContext> where; // filter SubClause
std::unordered_map<std::string, AliasType>* aliasesUsed{nullptr}; // 输入的 alias 信息
std::unordered_map<std::string, AliasType> aliasesGenerated; // 产生的 alias 信息
};
...
然后:
1.找语句 planner
找到对应语句的 planner,该语句类型为 Match。在 PlannersMap 中找到该语句的 planner MatchPlanner。
2.生成 plan
调用 MatchPlanner::transform 方法生成 plan:
StatusOr<SubPlan> MatchPlanner::transform(AstContext* astCtx) {
if (astCtx->sentence->kind() != Sentence::Kind::kMatch) {
return Status::Error("Only MATCH is accepted for match planner.");
}
auto* matchCtx = static_cast<MatchAstContext*>(astCtx);
std::vector<SubPlan> subplans;
for (auto& clauseCtx : matchCtx->clauses) {
switch (clauseCtx->kind) {
case CypherClauseKind::kMatch: {
auto subplan = std::make_unique<MatchClausePlanner>()->transform(clauseCtx.get());
NG_RETURN_IF_ERROR(subplan);
subplans.emplace_back(std::move(subplan).value());
break;
}
case CypherClauseKind::kUnwind: {
auto subplan = std::make_unique<UnwindClausePlanner>()->transform(clauseCtx.get());
NG_RETURN_IF_ERROR(subplan);
auto& unwind = subplan.value().root;
std::vector<std::string> inputCols;
if (!subplans.empty()) {
auto input = subplans.back().root;
auto cols = input->colNames();
for (auto col : cols) {
inputCols.emplace_back(col);
}
}
inputCols.emplace_back(unwind->colNames().front());
unwind->setColNames(inputCols);
subplans.emplace_back(std::move(subplan).value());
break;
}
case CypherClauseKind::kWith: {
auto subplan = std::make_unique<WithClausePlanner>()->transform(clauseCtx.get());
NG_RETURN_IF_ERROR(subplan);
subplans.emplace_back(std::move(subplan).value());
break;
}
case CypherClauseKind::kReturn: {
auto subplan = std::make_unique<ReturnClausePlanner>()->transform(clauseCtx.get());
NG_RETURN_IF_ERROR(subplan);
subplans.emplace_back(std::move(subplan).value());
break;
}
default: { return Status::Error("Unsupported clause."); }
}
}
auto finalPlan = connectSegments(astCtx, subplans, matchCtx->clauses);
NG_RETURN_IF_ERROR(finalPlan);
return std::move(finalPlan).value();
}
match 语句可能由多个 MATCH/UNWIND/WITH/RETURN Clause 组成,所以在 transform 中,根据 Clause 的类型,直接调用相应的 ClausePlanner 生成 SubPlan,最后再由 SegmentsConnector 依据各种连接策略将它们连接起来。
在我们的示例语句中,
第一个 Clause 是 Match Clause: MATCH (v:player)-[:like*2..4]-(v2:player),所以会调用 MatchClause::transform 方法:
StatusOr<SubPlan> MatchClausePlanner::transform(CypherClauseContextBase* clauseCtx) {
if (clauseCtx->kind != CypherClauseKind::kMatch) {
return Status::Error("Not a valid context for MatchClausePlanner.");
}
auto* matchClauseCtx = static_cast<MatchClauseContext*>(clauseCtx);
auto& nodeInfos = matchClauseCtx->nodeInfos;
auto& edgeInfos = matchClauseCtx->edgeInfos;
SubPlan matchClausePlan;
size_t startIndex = 0;
bool startFromEdge = false;
NG_RETURN_IF_ERROR(findStarts(matchClauseCtx, startFromEdge, startIndex, matchClausePlan));
NG_RETURN_IF_ERROR(
expand(nodeInfos, edgeInfos, matchClauseCtx, startFromEdge, startIndex, matchClausePlan));
NG_RETURN_IF_ERROR(projectColumnsBySymbols(matchClauseCtx, startIndex, matchClausePlan));
NG_RETURN_IF_ERROR(appendFilterPlan(matchClauseCtx, matchClausePlan));
return matchClausePlan;
}
该 transform 方法又分为以下几个步骤:
- 寻找拓展的起点:
目前有三个寻找起点的策略,由 planner 注册在 startVidFinders 里:
// MATCH(n) WHERE id(n) = value RETURN n
startVidFinders.emplace_back(&VertexIdSeek::make);
// MATCH(n:Tag{prop:value}) RETURN n
// MATCH(n:Tag) WHERE n.prop = value RETURN n
startVidFinders.emplace_back(&PropIndexSeek::make);
// seek by tag or edge(index)
// MATCH(n: tag) RETURN n
// MATCH(s)-[:edge]->(e) RETURN e
startVidFinders.emplace_back(&LabelIndexSeek::make);
这三个策略中,VertexIdSeek 最佳,可以确定具体的起点 VID;PropIndexSeek 次之,会被转换为一个附带属性 filter 的 IndexScan;LabelIndexSeek 会被转换为一个 IndexScan。
findStarts 函数会对每个寻找起点策略,分别遍历 match pattern 中的所有节点信息,直到找到一个可以作为起点的 node,并生成相应的找起点的 Plan Nodes。
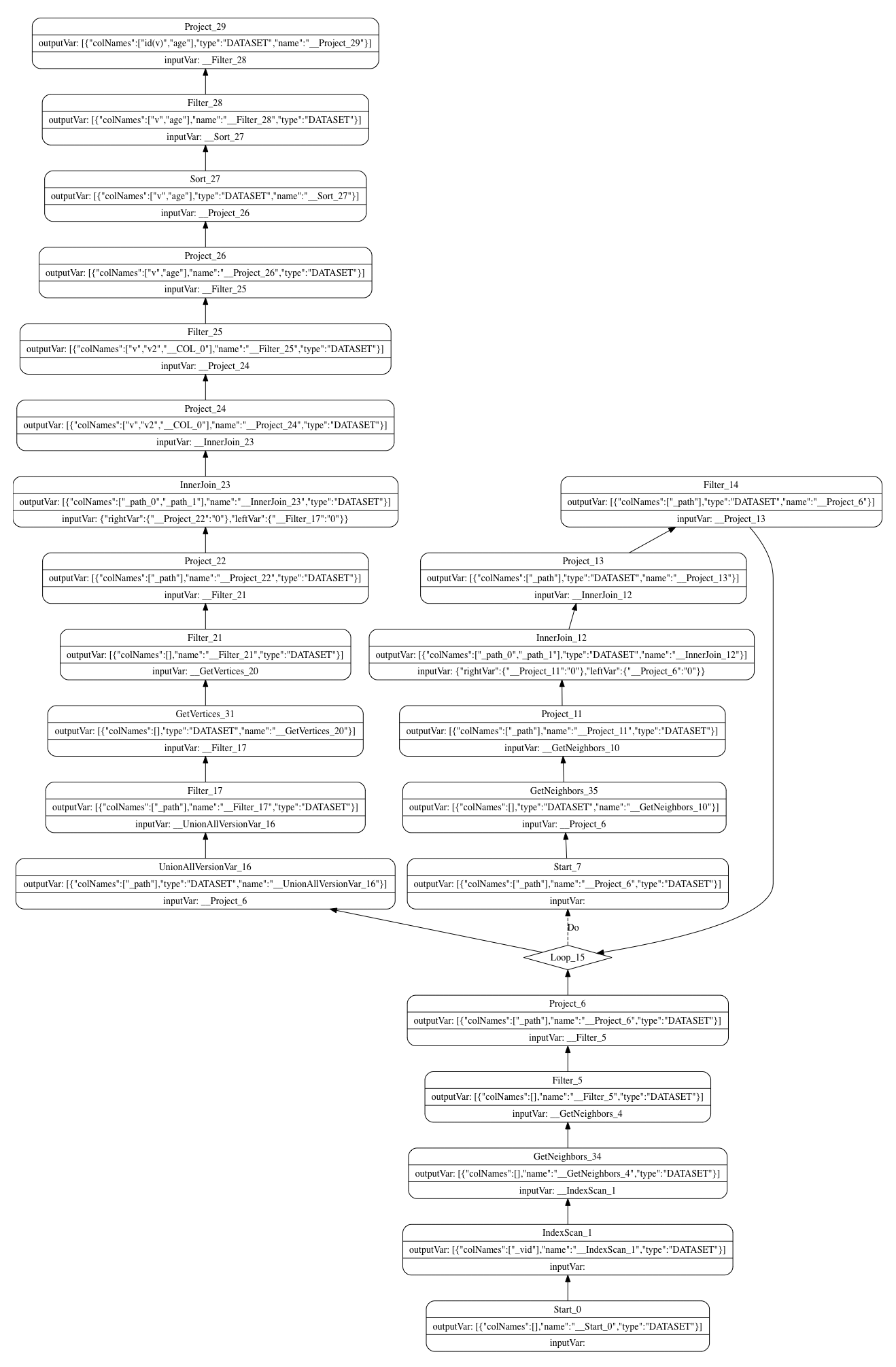
示例语句的寻点策略是 LabelIndexScan,确定的起点是 v。最终生成一个 IndexScan 节点,索引为 player 这个 tag 上的索引。
- 根据起点及 match pattern,进行多步拓展:
示例中句子的 match pattern 为:(v:player)-[:like*1..2]-(v2:player),以 v 为起点,沿着边 like 拓展一到二步,终点拥有 player 类型 tag。
先做拓展:
Status Expand::doExpand(const NodeInfo& node, const EdgeInfo& edge, SubPlan* plan) {
NG_RETURN_IF_ERROR(expandSteps(node, edge, plan));
NG_RETURN_IF_ERROR(filterDatasetByPathLength(edge, plan->root, plan));
return Status::OK();
}
多步拓展会生成 Loop 节点,loop body 为 expandStep 意为根据给定起点拓展一步,拓展一步需要生成 GetNeighbors 节点。每一步拓展的终点作为后面一步拓展的起点,一直循环下去,直到达到 pattern 中指定的最大步数。
在做第 M 步拓展时,以前面得到的长度为 M-1 的 path 的终点作为本次拓展的起点,向外延伸一步,并根据拓展的结果构建一个以边的起点和边本身组成的步长为 1 的 path,然后将该步长为 1 的 path 与前面的步长为 M-1 的 path 做一个 InnerJoin 得到步长为 M 的一组 path。
再调用对这组 path 做过滤,去除掉有重复边的 path(openCypher 路径的拓展不允许有重复边),最后将 path 的终点输出作为下一步拓展的起点。下一步拓展继续做上述步骤,直至达到最大中指定的最大步数。
loop 之后会生成 UnionAllVersionVar 节点,将 loop body 每次循环构建出的步长分别为 1 到 M 步的 path 合并起来。filterDatasetByPathLength()函数会生成一个 Filter 节点过滤掉步长小于 match pattern 中指定最小步数的 path。
最终得到的 path 形如(v)-like-()-e-(v)-?,还缺少最后一步的终点的属性信息。因此,我们还需要生成一个 GetVertices 节点,然后将获取到的终点与之前的 M 步 path 再做一个 InnerJoin,得到的就是符合 match pattern 要求的 path 集合了!
match 多步拓展原理会在 Variable Length Pattern Match 一文中有更详细的解释。
// Build Start node from first step
SubPlan loopBodyPlan;
PlanNode* startNode = StartNode::make(matchCtx_->qctx);
startNode->setOutputVar(firstStep->outputVar());
startNode->setColNames(firstStep->colNames());
loopBodyPlan.tail = startNode;
loopBodyPlan.root = startNode;
// Construct loop body
NG_RETURN_IF_ERROR(expandStep(edge,
startNode, // dep
startNode->outputVar(), // inputVar
nullptr,
&loopBodyPlan));
NG_RETURN_IF_ERROR(collectData(startNode, // left join node
loopBodyPlan.root, // right join node
&firstStep, // passThrough
&subplan));
// Union node
auto body = subplan.root;
// Loop condition
auto condition = buildExpandCondition(body->outputVar(), startIndex, maxHop);
// Create loop
auto* loop = Loop::make(matchCtx_->qctx, firstStep, body, condition);
// Unionize the results of each expansion which are stored in the firstStep node
auto uResNode = UnionAllVersionVar::make(matchCtx_->qctx, loop);
uResNode->setInputVar(firstStep->outputVar());
uResNode->setColNames({kPathStr});
subplan.root = uResNode;
plan->root = subplan.root;
- 输出 table,确定 table 的列名:
将 match pattern 中所有出现的具名符号作为 table 列名,生成一个 table,以供后续子句使用。这会生成一个 Project 节点。
第二个 clause 是 WithClause,调用 WithClause::transform 生成 SubPlan:
WITH v, v2.age AS age ORDER BY age WHERE age > 18
该 WITH 子句先 yield v 和 v2.age 两列作为一个 table,然后以 age 作为 sort item 进行排序,然后对排序后的 table 作 filter。
YIELD 部分会生成一个 Project 节点,ORDER BY 部分会生成一个 Sort 节点,WHERE 部分对应一个会生成一个 Filter 节点。
第三个 clause 是 Return Clause,会生成一个 Project 节点。
RETURN id(v), age
最终整合语句完整的的执行计划如下图:
以上为本篇文章的介绍内容。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
Nebula Graph 源码解读系列 | Vol.03 Planner 的实现的更多相关文章
- 新手阅读 Nebula Graph 源码的姿势
摘要:在本文中,我们将通过数据流快速学习 Nebula Graph,以用户在客户端输入一条 nGQL 语句 SHOW SPACES 为例,使用 GDB 追踪语句输入时 Nebula Graph 是怎么 ...
- Alamofire源码解读系列(二)之错误处理(AFError)
本篇主要讲解Alamofire中错误的处理机制 前言 在开发中,往往最容易被忽略的内容就是对错误的处理.有经验的开发者,能够对自己写的每行代码负责,而且非常清楚自己写的代码在什么时候会出现异常,这样就 ...
- Alamofire源码解读系列(四)之参数编码(ParameterEncoding)
本篇讲解参数编码的内容 前言 我们在开发中发的每一个请求都是通过URLRequest来进行封装的,可以通过一个URL生成URLRequest.那么如果我有一个参数字典,这个参数字典又是如何从客户端传递 ...
- Alamofire源码解读系列(三)之通知处理(Notification)
本篇讲解swift中通知的用法 前言 通知作为传递事件和数据的载体,在使用中是不受限制的.由于忘记移除某个通知的监听,会造成很多潜在的问题,这些问题在测试中是很难被发现的.但这不是我们这篇文章探讨的主 ...
- Alamofire源码解读系列(五)之结果封装(Result)
本篇讲解Result的封装 前言 有时候,我们会根据现实中的事物来对程序中的某个业务关系进行抽象,这句话很难理解.在Alamofire中,使用Response来描述请求后的结果.我们都知道Alamof ...
- Alamofire源码解读系列(六)之Task代理(TaskDelegate)
本篇介绍Task代理(TaskDelegate.swift) 前言 我相信可能有80%的同学使用AFNetworking或者Alamofire处理网络事件,并且这两个框架都提供了丰富的功能,我也相信很 ...
- Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager)
Alamofire源码解读系列(七)之网络监控(NetworkReachabilityManager) 本篇主要讲解iOS开发中的网络监控 前言 在开发中,有时候我们需要获取这些信息: 手机是否联网 ...
- Alamofire源码解读系列(八)之安全策略(ServerTrustPolicy)
本篇主要讲解Alamofire中安全验证代码 前言 作为开发人员,理解HTTPS的原理和应用算是一项基本技能.HTTPS目前来说是非常安全的,但仍然有大量的公司还在使用HTTP.其实HTTPS也并不是 ...
- Alamofire源码解读系列(九)之响应封装(Response)
本篇主要带来Alamofire中Response的解读 前言 在每篇文章的前言部分,我都会把我认为的本篇最重要的内容提前讲一下.我更想同大家分享这些顶级框架在设计和编码层次究竟有哪些过人的地方?当然, ...
- Alamofire源码解读系列(十)之序列化(ResponseSerialization)
本篇主要讲解Alamofire中如何把服务器返回的数据序列化 前言 和前边的文章不同, 在这一篇中,我想从程序的设计层次上解读ResponseSerialization这个文件.更直观的去探讨该功能是 ...
随机推荐
- java浅拷贝BeanUtils.copyProperties引发的RPC异常 | 京东物流技术团队
背景 近期参与了一个攻坚项目,前期因为其他流程原因,测试时间已经耽搁了好几天了,本以为已经解决了卡点,后续流程应该顺顺利利的,没想到 人在地铁上,bug从咚咚来~ 没有任何修改的服务接口,抛出异常: ...
- JavaScript一种新的数据结构类型Map
什么是map 它类似于对象,是键值对的集合,但键的范围不局限在于字符串.各种类型的值(包含对象)都可以作为键. 如果同一个键被多次赋值,后面的值将会覆盖其那面的值.如果读取一个未知的键,返回的是und ...
- (数据科学学习手札76)基于Python的拐点检测——以新冠肺炎疫情数据为例
本文对应代码.数据及文献资料已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes,对代码不感兴趣的朋友可以直接跳至2.2 探 ...
- 知识图谱项目实战(一):瑞金医院MMC人工智能辅助构建知识图谱--初赛实体识别【1】
1.技术背景&赛题介绍: A Labeled Chinese Dataset for Diabetes中文糖尿病标注数据集详情请见. 数据集链接:瑞金医院MMC人工智能辅助构建知识数据源:知识 ...
- Libevent [补档-2023-08-29]
libevent的使用 8-1 安装 自己百度一下,安装它不是特别难,加油!!! 8-2 libevent介绍 它是一个开源库,用于处理网络和定时器等等事件.它提供了跨平台的API,能够在不同 ...
- c#树结构转npoi复杂表头
Vue 前端框架框架中采用树结构打印表头,为了前后端适配NPOI导出. 这里重点做树结构转换 NPOI 复杂表头的结构数据( 跨行.跨列),其它具体导出功能请参考 https://www.cnblo ...
- 蓝鲸:主机频繁提示“You have new mail in /var/spool/mail/root” 定位解决
前些天安装蓝鲸的测试环境频繁出现You have new mail in /var/spool/mail/root,查看发现是/usr/local/gse/agent/bin/gsectl: line ...
- ABC 326
E 题意: 给定一个 \(n\) 面骰,长度 \(n\) 的数组 \(a\) 和一个初始为 \(0\) 的变量 \(x\). 每次投掷骰子,等概率获得 \(1 \sim n\) 中的一个数 \(p\) ...
- 吉特日化MES & 某配料自动化项目业务架构图
作者:情缘 出处:http://www.cnblogs.com/qingyuan/ 关于作者:从事仓库,生产软件方面的开发,在项目管理以及企业经营方面寻求发展之路 版权声明:本文版权归作者和博客园 ...
- Power BI 6 DAY
Power BI 数据建模与数据汇总分析 层级关系 跨表取字段时类型二可用 父子级关系条件 一个父级下对应多个子级值 一个子级值只属于一个父级 跨表取字段的条件:维度连接用关键字段间是父子级关系时,可 ...