掌握pandas cut函数,一键实现数据分类
pandas中的cut函数可将一维数据按照给定的区间进行分组,并为每个值分配对应的标签。
其主要功能是将连续的数值数据转化为离散的分组数据,方便进行分析和统计。
1. 数据准备
下面的示例中使用的数据采集自王者荣耀比赛的统计数据。
数据下载地址:https://databook.top/。
导入数据:
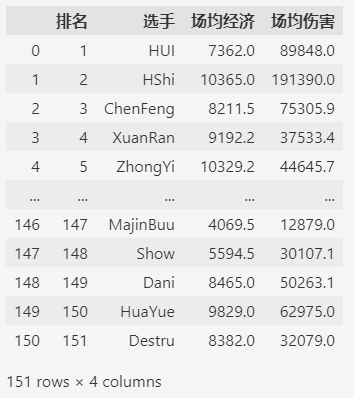
# 2023年世冠比赛选手的数据
fp = r"D:\data\player-2023世冠.csv"
df = pd.read_csv(fp)
# 这里只保留了下面示例中需要的列
df = df.loc[:, ["排名", "选手", "场均经济", "场均伤害"]]
df
2. 使用示例
每个选手的“场均经济”和“场均伤害”是连续分布的数据,为了整体了解所有选手的情况,
可以使用下面的方法将“场均经济”和“场均伤害”分类。
2.1. 查看数据分布
首先,可以使用直方图的方式看看数据连续分布的情况:
import matplotlib.pyplot as plt
df.loc[:, ["场均经济", "场均伤害"]].hist()
plt.show()
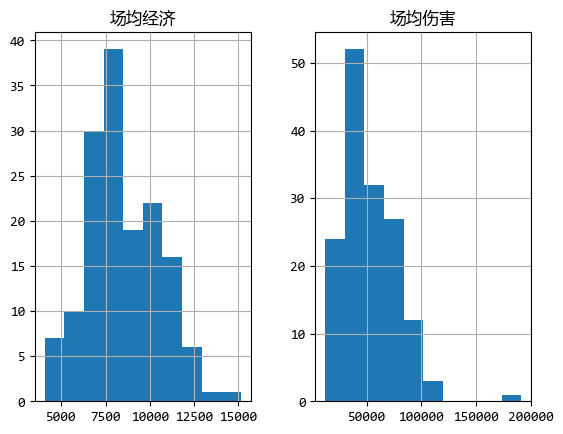
图中的横轴是“经济”和“伤害”的数值,纵轴是选手的数量。
2.2. 定制分布参数
从默认的直方图中可以看出大部分选手的“场均经济”和“场均伤害”大致在什么范围,
不过,为了更精细的分析,我们可以进一步定义自己的分类范围,看看各个分类范围内的选手数量情况。
比如,我们将“场均经济”分为3块,分别为低(0~5000),中(5000~10000),高(10000~20000)。
同样,对于“场均伤害”,也分为3块,分别为低(0~50000),中(50000~100000),高(100000~200000)。
bins1 = [0, 5000, 10000, 20000]
bins2 = [0, 50000, 100000, 200000]
labels = ["低", "中", "高"]
s1 = "场均经济"
s2 = "场均伤害"
df[f"{s1}-分类"] = pd.cut(df[s1], bins=bins1, labels=labels)
df[f"{s2}-分类"] = pd.cut(df[s2], bins=bins2, labels=labels)
df
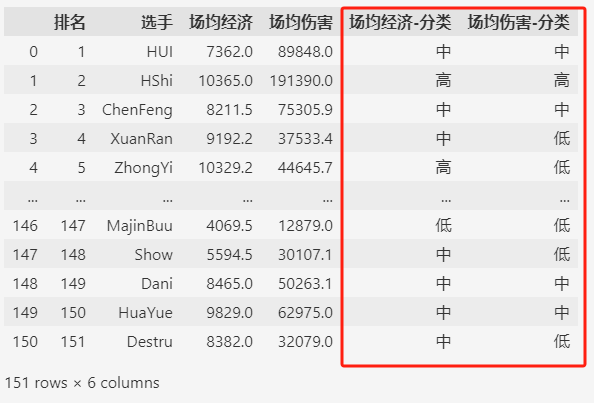
分类之后,选手被分到3个类别之中,然后再绘制直方图。
df.loc[:, f"{s1}-分类"].hist()
plt.title(f"{s1}-分类")
plt.show()
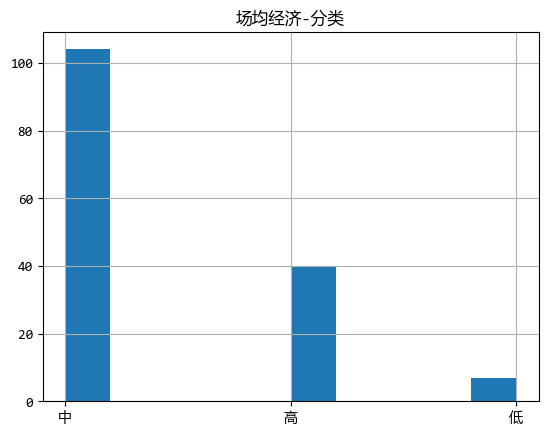
从这个图看出,大部分选手都是“中”,“高”的经济,说明职业选手很重视英雄发育。
df.loc[:, f"{s2}-分类"].hist()
plt.title(f"{s2}-分类")
plt.show()
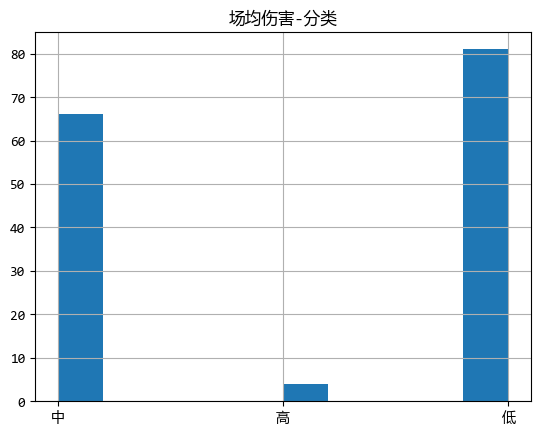
从图中可以看出,打出高伤害的选手比例并不高,可能职业比赛中,更多的是团队作战。
3. 总结
总的来说,cut函数的主要作用是将输入的数值数据(可以是一维数组、Series或DataFrame的列)按照指定的间隔或自定义的区间边界进行划分,并为每个划分后的区间分配一个标签。
这样,原始的连续数据就被转化为了离散的分组数据,每个数据点都被分配到了一个特定的组中,从而方便后续进行分析和统计。
掌握pandas cut函数,一键实现数据分类的更多相关文章
- pandas 常用函数整理
pandas常用函数整理,作为个人笔记. 仅标记函数大概用途做索引用,具体使用方式请参照pandas官方技术文档. 约定 from pandas import Series, DataFrame im ...
- 【转载】pandas常用函数
原文链接:https://www.cnblogs.com/rexyan/p/7975707.html 一.import语句 import pandas as pd import numpy as np ...
- Pandas的函数应用、层级索引、统计计算
1.Pandas的函数应用 1.apply 和 applymap 1. 可直接使用NumPy的函数 示例代码: # Numpy ufunc 函数 df = pd.DataFrame(np.random ...
- pandas常用函数之shift
shift函数是对数据进行移动的操作,假如现在有一个DataFrame数据df,如下所示: index value1 A 0 B 1 C 2 D 3 那么如果执行以下代码: df.shift() 就会 ...
- pandas常用函数之diff
diff函数是用来将数据进行某种移动之后与原数据进行比较得出的差异数据,举个例子,现在有一个DataFrame类型的数据df,如下: index value1 A 0 B 1 C 2 D 3 如果执行 ...
- pandas.cut使用总结
用途 pandas.cut用来把一组数据分割成离散的区间.比如有一组年龄数据,可以使用pandas.cut将年龄数据分割成不同的年龄段并打上标签. 原型 pandas.cut(x, bins, rig ...
- R quantile函数 | cut函数 | sample函数 | all函数 | scale函数 | do.call函数
取出一个数字序列中的百分位数 1. 求某一个百分比 x<-rnorm(200) quantile(x,0.9) 2. 求一系列的百分比 quantile(x,c(0.1,0.9)) quanti ...
- python pandas字符串函数详解(转)
pandas字符串函数详解(转)——原文连接见文章末尾 在使用pandas框架的DataFrame的过程中,如果需要处理一些字符串的特性,例如判断某列是否包含一些关键字,某列的字符长度是否小于3等等 ...
- Pandas常用函数入门
一.Pandas Python Data Analysis Library或Pandas是基于NumPy的一种工具,该工具是为了解决数据分析任务而创建的.Pandas纳入了大量库和一些标准的数据模型, ...
- pandas常用函数
1. df.head(n): 显示数据前n行,不指定n,df.head则会显示所有的行 2. df.columns.values获取所有列索引的名称 3. df.column_name: 直接获取列c ...
随机推荐
- kettle系统列文章01---安装与配置
1).到官网下载需要安装的kettle版本,目前最新版本4.2,官网地址:http://kettle.pentaho.org,我们是使用的版本是kettle3.2 2).本地安装jdk 1.4或以上版 ...
- 3D圆饼图,可修改颜色,图片等,具体见代码:
组件代码: <template> <!-- 饼图 --> <div :id="histogramId" v-bind:style="{hei ...
- 【三】AI Studio 项目详解——单机多机训练分布式训练--PARL
相关文章 [一]-环境配置+python入门教学 [二]-Parl基础命令 [三]-Notebook.&pdb.ipdb 调试 [四]-强化学习入门简介 [五]-Sarsa&Qlear ...
- ESXi6.5导入虚拟机提示缺少所需的磁盘镜像
环境 esxi6.7 错误提示 解决方案 原因:这是因为导出虚拟机的时候,没有把"CD/DVD驱动器"删掉,在导入的时候,找不到这个磁盘映像. 编辑.ovf文件,找到ovf:hre ...
- Windows开机自动同步时间
前言 有些Windows客户端因主板电池没电或其他原因,每次启动系统后,读取到BIOS的时间是初始时间(1970年)或错误的时间,这时需要系统启动后立即向时间服务器同步一次时间. 该方法是添加 ...
- PHP截取文章内容
<?php /** * 实现中文字串截取无乱码的方法. */ function getSubstr($string, $start, $length) { if (mb_strlen($stri ...
- Google_Book_20Things.前言以及前四项学习笔记
20 THINGS I LEARNED ABOUT BROWSERS AND THE WEB Illustrated by Christoph Niemann. Written by the Goog ...
- flash8.ocx或其附件之一不能正确注册
运行书中自带光盘中的程序,在该程序的readme说明中,提到这类错误,解决方式是: 因为是免安装程序,需要运行"setup"文件夹下的setup.exe文件,安装控件.在安装完成后 ...
- Series基础
目录 创建Series对象 1) 创建一个空Series对象 2) ndarray创建Series对象 3) dict创建Series对象 4) 标量创建Series对象 访问Series数据 1) ...
- Dubbo本地调试方法
方法一:用版本号来区分 比如,开发环境上跑的服务版本是1.0.0,那么为了在本地打断点调试某个服务,可以在本地启动,将version设置为2.0.0 服务提供者 @DubboService(versi ...