python day2-爬虫实现github登录
GitHub登录
分析登录页面
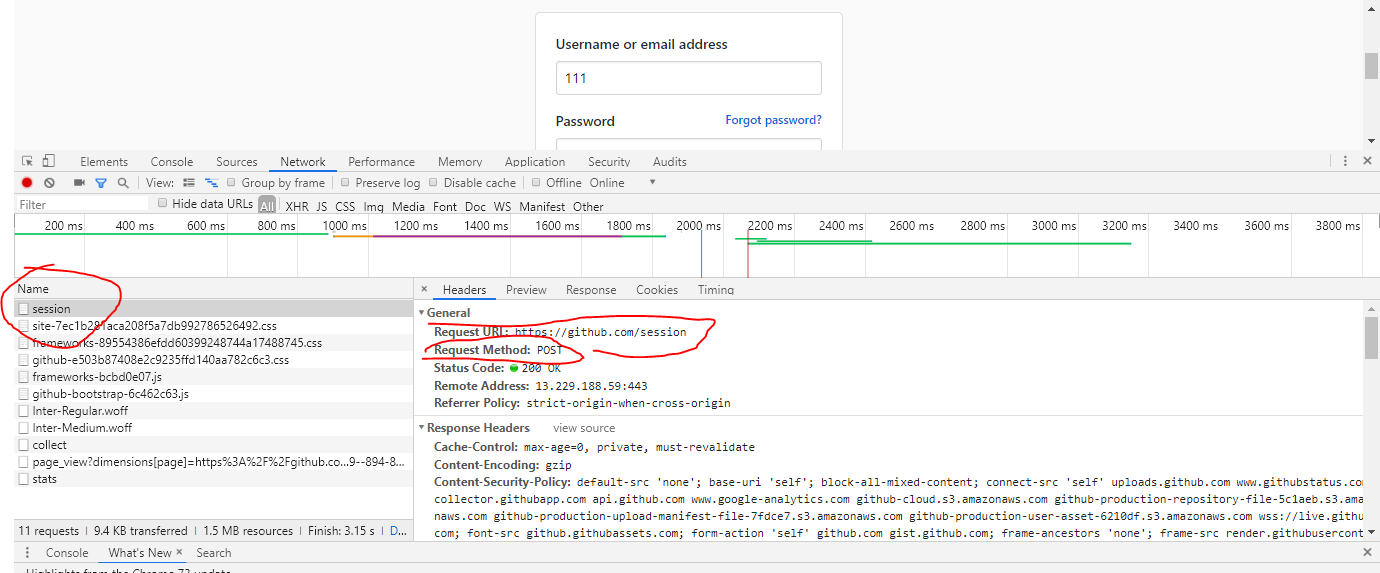
开发者工具分析请求
从session请求分析得知:
1.请求的URL为:https://github.com/session
2.该请求为post请求,即需要上传data表单,所以我们需要分析form-data
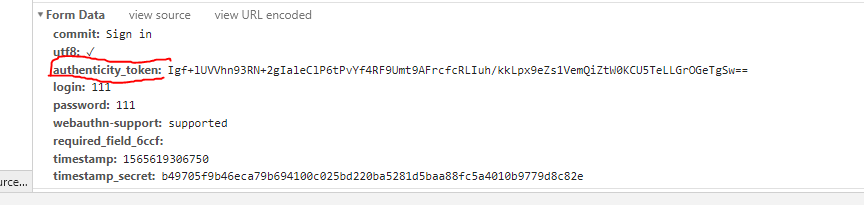
由form-data分析得知:
1.login:GitHub的账号
2.password:GitHub的密码
3.authenticity_token:每次请求时都发生变动
4.其余参数没有特殊的变动
因此需要分析authenticity_token的规律,经过分析源代码得知:

在login页面中存在该参数,且每次请求该页面时该参数都发生变动
因此我们需要使用维持会话的方式抓取该参数
import requests session = requests.Session() #实例化,维持会话
url_login = 'https://github.com/login'
response = session.get(url_login)
#通过正则获取token值
authenticity_token = re.findall('name="authenticity_token" value="(.*?)" />',response.text)[0]
print(authenticity_token)
当我们获取该参数后,即可以代入form-data中完成登录
附上全部代码
import requests
import re session = requests.Session() #实例化,维持会话 def token():
url_login = 'https://github.com/login'
response = session.get(url_login)
#通过正则获取token值
authenticity_token = re.findall('name="authenticity_token" value="(.*?)" />',response.text)[0]
return authenticity_token #返回token值 def url_session(token):
url = 'https://github.com/session'
data = {
'commit': 'Sign in',
'utf8': '✓',
'authenticity_token': token, #authenticity_token参数
'login': '输入账号', #你的账号
'password': '输入密码', #你的密码
'webauthn-support': 'supported',
'required_field_852e': '',
'timestamp': '',
'timestamp_secret': '850cb01230466a48f29899e2202265961cdcde8375c4ee69399cd9e9805e1ede',
}
response = session.post(url,data=data) #传入form-data表单
return response.text #返回源码 def save_github(response_text):
with open('github.html','w',encoding='utf-8') as fp:
fp.write(response_text) if __name__ == '__main__':
token = token() #获取authenticity_token参数
response_text = url_session(token) #获取网页源码
save_github(response_text) #把爬取到的源码保存为html格式
python day2-爬虫实现github登录的更多相关文章
- 利用Python模拟GitHub登录
最近学习了Fiddler抓包工具的简单使用,通过抓包,我们可以抓取到HTTP请求,并对其进行分析.现在我准备尝试着结合Python来模拟GitHub登录. Fiddler抓包分析 首先,我们想要模拟一 ...
- Python爬虫之模拟登录微信wechat
不知何时,微信已经成为我们不可缺少的一部分了,我们的社交圈.关注的新闻或是公众号.还有个人信息或是隐私都被绑定在了一起.既然它这么重要,如果我们可以利用爬虫模拟登录,是不是就意味着我们可以获取这些信息 ...
- Python爬虫-百度模拟登录(二)
上一篇-Python爬虫-百度模拟登录(一) 接上一篇的继续 参数 codestring codestring jxG9506c1811b44e2fd0220153643013f7e6b1898075 ...
- 第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别
第三百四十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy模拟登陆和知乎倒立文字验证码识别 第一步.首先下载,大神者也的倒立文字验证码识别程序 下载地址:https://gith ...
- Python分布式爬虫抓取知乎用户信息并进行数据分析
在以前的文章中,我写过一篇使用selenium来模拟登录知乎的文章,然后在很长一段时间里都没有然后了... 不过在最近,我突然觉得,既然已经模拟登录到了知乎了,为什么不继续玩玩呢?所以就创了一个项目, ...
- Python 网络爬虫干货总结
Python 网络爬虫干货总结 爬取 对于爬取来说,我们需要学会使用不同的方法来应对不同情景下的数据抓取任务. 爬取的目标绝大多数情况下要么是网页,要么是 App,所以这里就分为这两个大类别来进行了介 ...
- Python分布式爬虫打造搜索引擎完整版-基于Scrapy、Redis、elasticsearch和django打造一个完整的搜索引擎网站
Python分布式爬虫打造搜索引擎 基于Scrapy.Redis.elasticsearch和django打造一个完整的搜索引擎网站 https://github.com/mtianyan/Artic ...
- Python基础+爬虫基础
Python基础+爬虫基础 一.python的安装: 1.建议安装Anaconda,会自己安装一些Python的类库以及自动的配置环境变量,比较方便. 二.基础介绍 1.什么是命名空间:x=1,1存在 ...
- python网络爬虫实战PDF高清完整版免费下载|百度云盘|Python基础教程免费电子书
点击获取提取码:vg1y python网络爬虫实战帮助读者学习Python并开发出符合自己要求的网络爬虫.网络爬虫,又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚 ...
随机推荐
- js支持中文的hex编码 bin2hex (utf-8)
背景: 最近对接接口的时候需要将请求参数转为16进制,因此研究了下这个bin2hex.在js中转16进制 使用的是: str.charCodeAt(i).toString(16); 在遇到中文的时候编 ...
- vue-router中$route 和 $router
1.1 $route 表示(当前路由信息对象) 表示当前激活的路由的状态信息,包含了当前 URL 解析得到的信息,还有 URL 匹配到的 route records(路由记录).路由信息对象:即$ro ...
- 实战build-react(三)
安装 redux-thunk yarn add redux-thunk 或 npm install redux-thunk --save https://github.com/zalmoxisus/r ...
- BZOJ 2157: 旅游 (结构体存变量)
用结构体存变量好像确实能提高运行速度,以后就这么写数据结构了 Code: #include <cstdio> #include <algorithm> #include < ...
- csp-s2019 AFO记
DAY 0 上午出发前大家都很颓废的样子. 我因为还没有实现刷完NOIP专题的所有题的目标而去憨比的学DDP. 最后还是不会,保卫王国是写不成了…… 该走了,学校领导来开了个欢送会,祝福我们从里WA到 ...
- [CSP-S模拟测试]:Smooth(数学)
题目传送门(内部题84) 输入格式 两个整数$B,K$ 输出格式 一个整数表示答案 样例 样例输入: 5 100 样例输出: 数据范围与提示 对于$40\%$的数据,保证答案小于$10^7$对于另$2 ...
- linux 简单命令说明
1.df -h 查看磁盘占用及挂载情况 挂载磁盘 如下: mount /dev/sda1 /boot 取消挂载的磁盘 umount /boot 2.dh -sh 查看当前目录占用文件大小 dh -sh ...
- 《Using Python to Access Web Data》Week4 Programs that Surf the Web 课堂笔记
Coursera课程<Using Python to Access Web Data> 密歇根大学 Week4 Programs that Surf the Web 12.3 Unicod ...
- 设置了responseType:Blob之后,如果返回json错误信息,如果获取?
最近做了一个文件下载功能,于是设置了responseType: Blob的方式, 什么是Blob呢,MDN官方解释:Blob 对象表示一个不可变.原始数据的类文件对象.Blob 表示的不一定是Java ...
- 项目测试完成后,总结典型性bug,以测试的角度,应该怎么筛选bug
一个wap端改版项目完结了,总结下测试过程中的典型性bug:应该从哪个角度去总结? 有点疑问?不知道是以bug的影响度去总结,还是以优先级去总结(好像优先级和影响度是成正比的,优先级比较高的bug,影 ...