Apache Spark1.1.0部署与开发环境搭建
Spark是Apache公司推出的一种基于Hadoop Distributed File System(HDFS)的并行计算架构。与MapReduce不同,Spark并不局限于编写map和reduce两个方法,其提供了更为强大的内存计算(in-memory computing)模型,使得用户可以通过编程将数据读取到集群的内存当中,并且可以方便用户快速地重复查询,非常适合用于实现机器学习算法。本文将介绍Apache Spark1.1.0部署与开发环境搭建。
0. 准备
出于学习目的,本文将Spark部署在虚拟机中,虚拟机选择VMware WorkStation。在虚拟机中,需要安装以下软件:
- Ubuntu 14.04.1 LTS 64位桌面版
- hadoop-2.4.0.tar.gz
- jdk-7u67-linux-x64.tar.gz
- scala-2.10.4.tgz
- spark-1.1.0-bin-hadoop2.4.tgz
Spark的开发环境,本文选择Windows7平台,IDE选择IntelliJ IDEA。在Windows中,需要安装以下软件:
- IntelliJ IDEA 13.1.4 Community Edition
- apache-maven-3.2.3-bin.zip(安装过程比较简单,请读者自行安装)
1. 安装JDK
解压jdk安装包到/usr/lib目录:
sudo cp jdk-7u67-linux-x64.gz /usr/lib
cd /usr/lib
sudo tar -xvzf jdk-7u67-linux-x64.gz
sudo gedit /etc/profile
在/etc/profile文件的末尾添加环境变量:
export JAVA_HOME=/usr/lib/jdk1..0_67
export JRE_HOME=/usr/lib/jdk1..0_67/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
保存并更新/etc/profile:
source /etc/profile
测试jdk是否安装成功:
java -version

2. 安装及配置SSH
sudo apt-get update
sudo apt-get install openssh-server
sudo /etc/init.d/ssh start
生成并添加密钥:
ssh-keygen -t rsa -P ""
cd /home/hduser/.ssh
cat id_rsa.pub >> authorized_keys
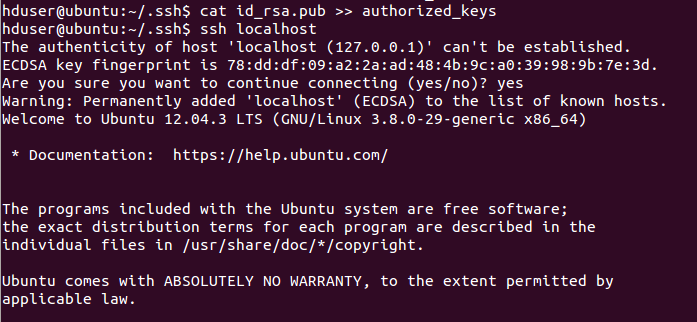
ssh登录:
ssh localhost
3. 安装hadoop2.4.0
采用伪分布模式安装hadoop2.4.0。解压hadoop2.4.0到/usr/local目录:
sudo cp hadoop-2.4..tar.gz /usr/local/
sudo tar -xzvf hadoop-2.4..tar.gz
在/etc/profile文件的末尾添加环境变量:
export HADOOP_HOME=/usr/local/hadoop-2.4.
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
保存并更新/etc/profile:
source /etc/profile
在位于/usr/local/hadoop-2.4.0/etc/hadoop的hadoop-env.sh和yarn-env.sh文件中修改jdk路径:
cd /usr/local/hadoop-2.4./etc/hadoop
sudo gedit hadoop-env.sh
sudo gedit yarn-evn.sh
hadoop-env.sh:

yarn-env.sh:

修改core-site.xml:
sudo gedit core-site.xml
在<configuration></configuration>之间添加:
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
</property>
修改hdfs-site.xml:
sudo gedit hdfs-site.xml
在<configuration></configuration>之间添加:
<property>
<name>dfs.namenode.name.dir</name>
<value>/app/hadoop/dfs/nn</value>
</property> <property>
<name>dfs.namenode.data.dir</name>
<value>/app/hadoop/dfs/dn</value>
</property> <property>
<name>dfs.replication</name>
<value></value>
</property>
修改yarn-site.xml:
sudo gedit yarn-site.xml
在<configuration></configuration>之间添加:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
复制并重命名mapred-site.xml.template为mapred-site.xml:
sudo cp mapred-site.xml.template mapred-site.xml
sudo gedit mapred-site.xml
在<configuration></configuration>之间添加:
<property>
<name>mapreduce.jobtracker.address </name>
<value>hdfs://localhost:9001</value>
</property>
在启动hadoop之前,为防止可能出现无法写入log的问题,记得为/app目录设置权限:
sudo mkdir /app
sudo chmod -R hduser:hduser /app
格式化hadoop:
hadoop namenode -format
启动hdfs和yarn。在开发Spark时,仅需要启动hdfs:
sbin/start-dfs.sh
sbin/start-yarn.sh
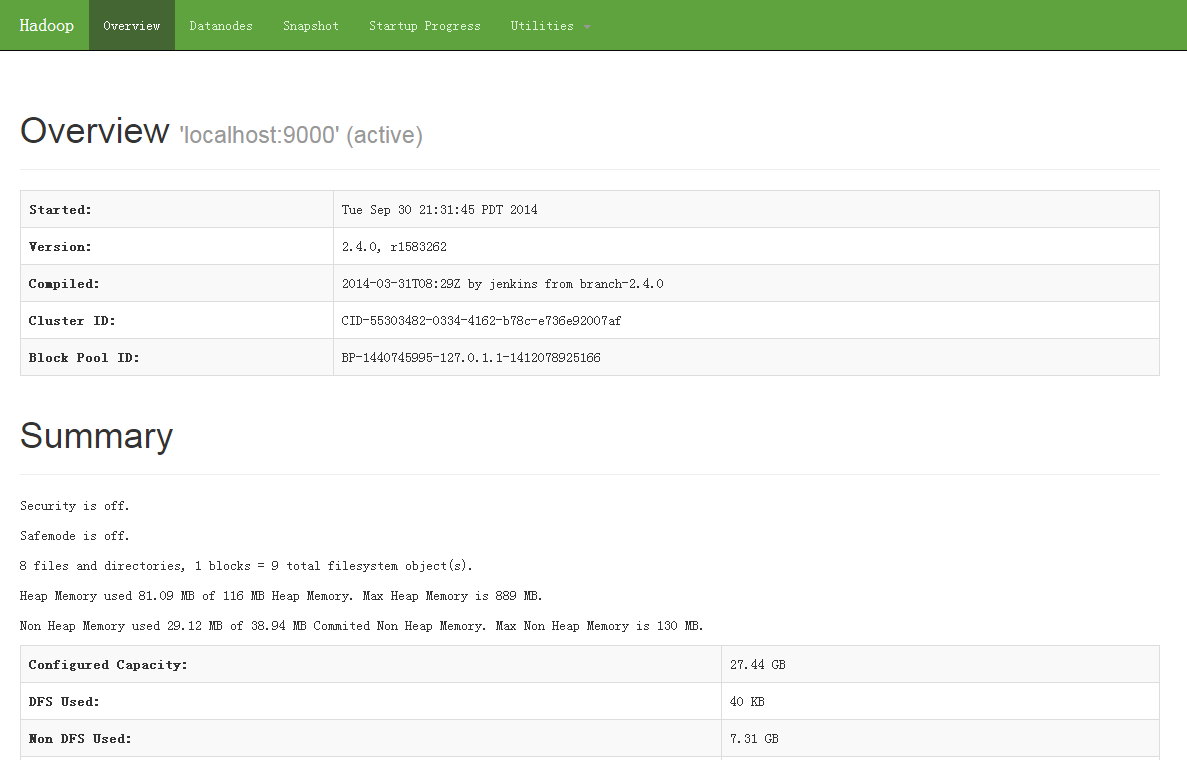
在浏览器中打开地址http://localhost:50070/可以查看hdfs状态信息:
4. 安装scala
sudo cp /home/hduser/Download/scala-2.9..tgz /usr/local
sudo tar -xvzf scala-2.9..tgz
在/etc/profile文件的末尾添加环境变量:
export SCALA_HOME=/usr/local/scala-2.9.
export PATH=$SCALA_HOME/bin:$PATH
保存并更新/etc/profile:
1 source /etc/profile
测试scala是否安装成功:
1 scala -version
5. 安装Spark
sudo cp spark-1.1.-bin-hadoop2..tgz /usr/local
sudo tar -xvzf spark-1.1.-bin-hadoop2..tgz
在/etc/profile文件的末尾添加环境变量:
1 export SPARK_HOME=/usr/local/spark-1.1.0-bin-hadoop2.4
2 export PATH=$SPARK_HOME/bin:$PATH
保存并更新/etc/profile:
1 source /etc/profile
复制并重命名spark-env.sh.template为spark-env.sh:
sudo cp spark-env.sh.template spark-env.sh
sudo gedit spark-env.sh
在spark-env.sh中添加:
export SCALA_HOME=/usr/local/scala-2.9.
export JAVA_HOME=/usr/lib/jdk1..0_67
export SPARK_MASTER_IP=localhost
export SPARK_WORKER_MEMORY=1000m
启动Spark:
cd /usr/local/spark-1.1.-bin-hadoop2.
sbin/start-all.sh
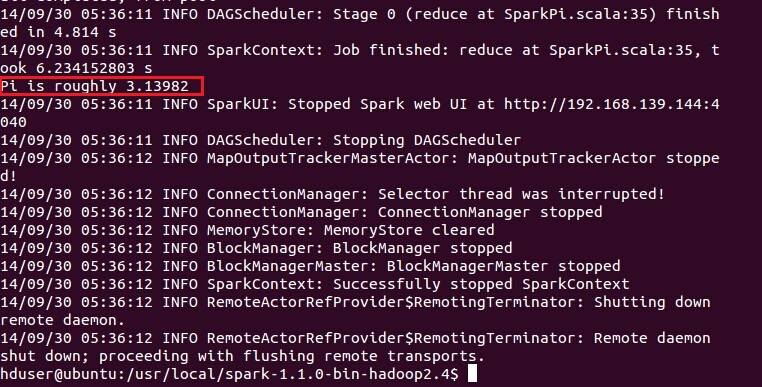
测试Spark是否安装成功:
cd /usr/local/spark-1.1.-bin-hadoop2.
bin/run-example SparkPi
6. 搭建Spark开发环境
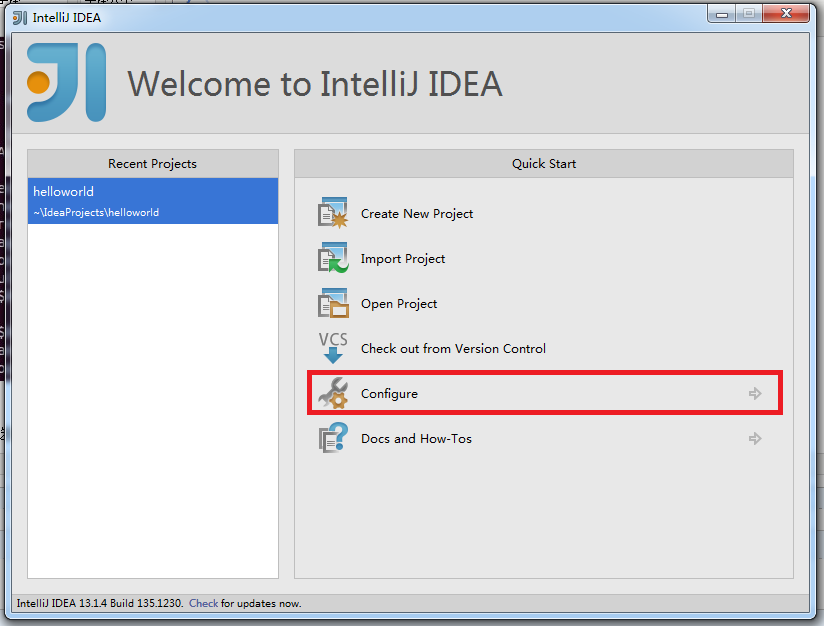
本文开发Spark的IDE推荐IntelliJ IDEA,当然也可以选择Eclipse。在使用IntelliJ IDEA之前,需要安装scala的插件。点击Configure:
点击Plugins:

点击Browse repositories...:
在搜索框内输入scala,选择Scala插件进行安装。由于已经安装了这个插件,下图没有显示安装选项:
安装完成后,IntelliJ IDEA会要求重启。重启后,点击Create New Project:

Project SDK选择jdk安装目录,建议开发环境中的jdk版本与Spark集群上的jdk版本保持一致。点击左侧的Maven,勾选Create from archetype,选择org.scala-tools.archetypes:scala-archetype-simple:
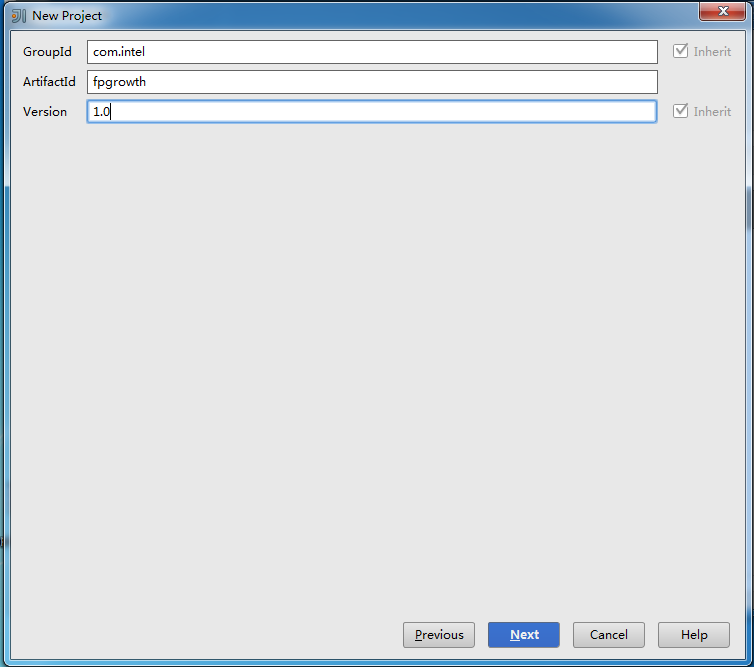
点击Next后,可根据需求自行填写GroupId,ArtifactId和Version:
点击Next后,如果本机没有安装maven会报错,请保证之前已经安装maven:
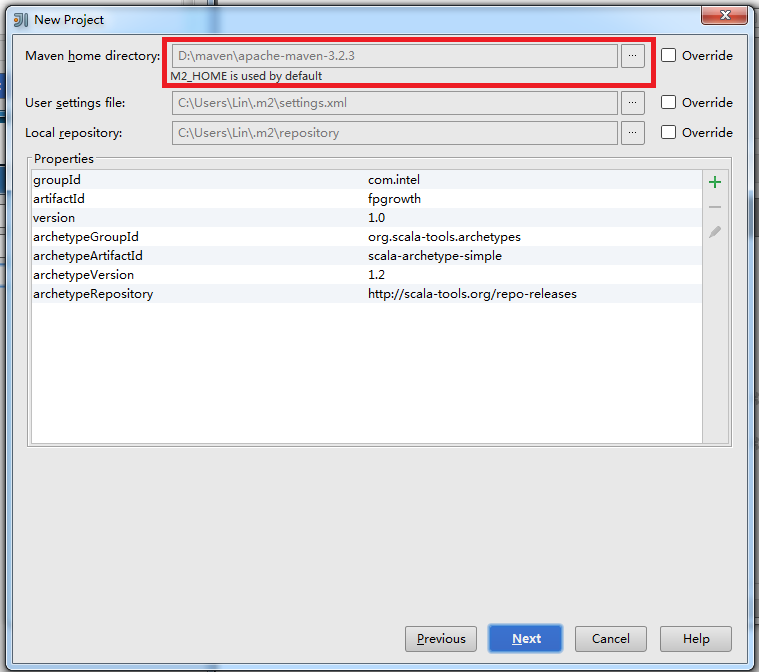
点击Next后,输入文件名,完成New Project的最后一步:
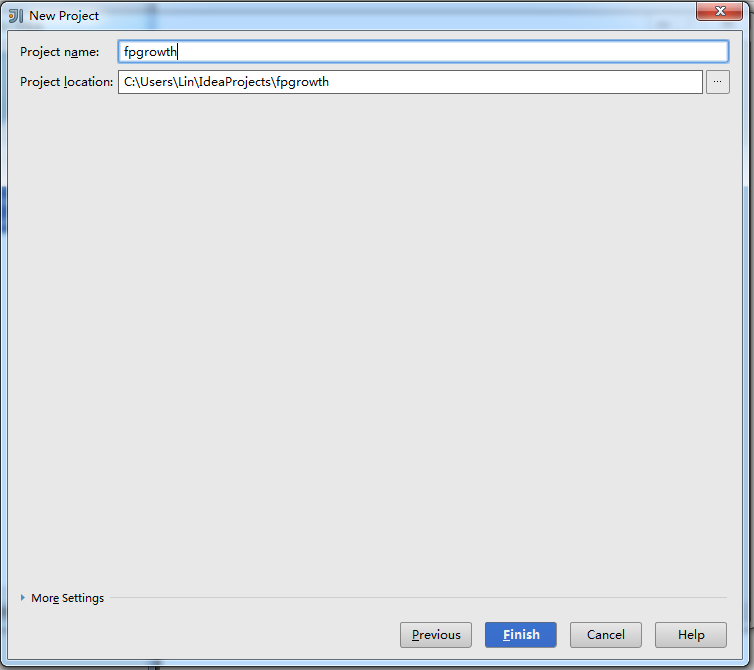
点击Finish后,maven会自动生成pom.xml和下载依赖包。我们需要修改pom.xml中scala的版本:
<properties>
<scala.version>2.10.</scala.version>
</properties>
在<dependencies></dependencies>之间添加配置:
<!-- Spark -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.</artifactId>
<version>1.1.</version>
</dependency> <!-- HDFS -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.4.</version>
</dependency>
在<build><plugins></plugins></build>之间添加配置:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>mark.lin.App</mainClass> // 记得修改成你的mainClass
</transformer>
<transformer
implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
</transformers>
<shadedArtifactAttached>true</shadedArtifactAttached>
<shadedClassifierName>executable</shadedClassifierName>
</configuration>
</execution>
</executions>
</plugin>
Spark的开发环境至此搭建完成。One more thing,wordcount的示例代码:
package mark.lin //别忘了修改package
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
import scala.collection.mutable.ListBuffer
/**
* Hello world!
*
*/
object App{
def main(args: Array[String]) {
if (args.length != ) {
println("Usage: java -jar code.jar dependencies.jar")
System.exit()
}
val jars = ListBuffer[String]()
args().split(",").map(jars += _)
val conf = new SparkConf()
conf.setMaster("spark://localhost:7077").setAppName("wordcount").set("spark.executor.memory", "128m").setJars(jars)
val sc = new SparkContext(conf)
val file = sc.textFile("hdfs://localhost:9000/hduser/wordcount/input/input.csv")
val count = file.flatMap(line => line.split(" ")).map(word => (word, )).reduceByKey(_+_)
println(count)
count.saveAsTextFile("hdfs://localhost:9000/hduser/wordcount/output/")
sc.stop()
}
}
7. 编译&运行
使用maven编译源代码。点击左下角,点击右侧package,点击绿色三角形,开始编译。

在target目录下,可以看到maven生成的jar包。其中,hellworld-1.0-SNAPSHOT-executable.jar是我们需要放到Spark集群上运行的。
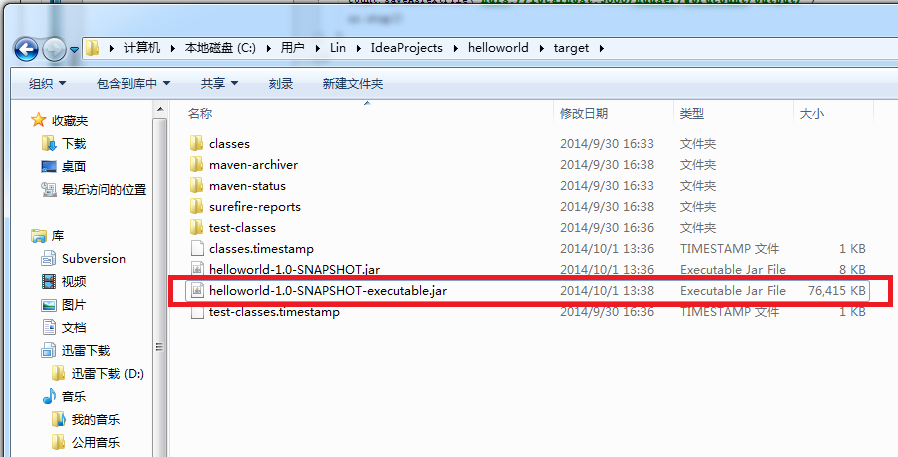
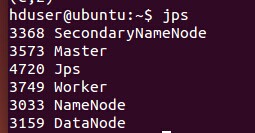
在运行jar包之前,保证hadoop和Spark处于运行状态:
$LA71]}S5Q7I3.jpg)
将jar包拷贝到Ubuntu的本地文件系统上,输入以下命令运行jar包:
java -jar helloworld-1.0-SNAPSHOT-executable.jar helloworld-1.0-SNAPSHOT-executable.jar
在浏览器中输入地址http://localhost:8080/可以查看任务运行情况:

8. Q&A
Q:在Spark集群上运行jar包,抛出异常“No FileSystem for scheme: hdfs”:

A:这是由于hadoop-common-2.4.0.jar中的core-default.xml缺少hfds的相关配置属性引起的异常。在maven仓库目录下找到hadoop-common-2.4.0.jar,以rar的打开方式打开:
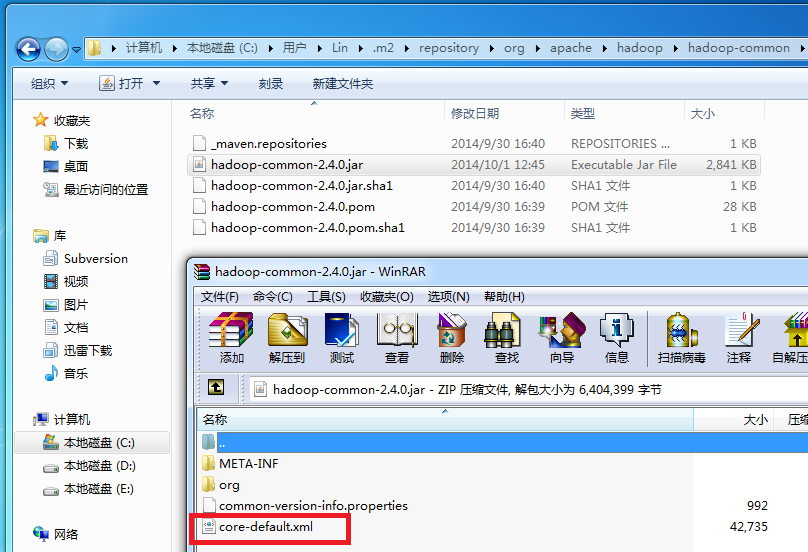
将core-default.xml拖出,并添加配置:
<property>
<name>fs.hdfs.impl</name>
<value>org.apache.hadoop.hdfs.DistributedFileSystem</value>
<description>The FileSystem for hdfs: uris.</description>
</property>
再将修改后的core-default.xml替换hadoop-common-2.4.0.jar中的core-default.xml,重新编译生成jar包。
Q:在Spark集群上运行jar包,抛出异常“Failed on local exception”:

A:检查你的代码,一般是由于hdfs路径错误引起。
Q:在Spark集群上运行jar包,重复提示“Connecting to master spark”:

A:检查你的代码,一般是由于setMaster路径错误引起。
Q:在Spark集群上运行jar包,重复提示“Initial job has not accepted any resource; check your cluster UI to ensure that workers are registered and have sufficient memory”:

A:检查你的代码,一般是由于内存设置不合理引起。此外,还需要检查Spark安装目录下的conf/spark-env.sh对worker内存的设置。
Q:maven报错:error: org.specs.Specification does not have a constructor
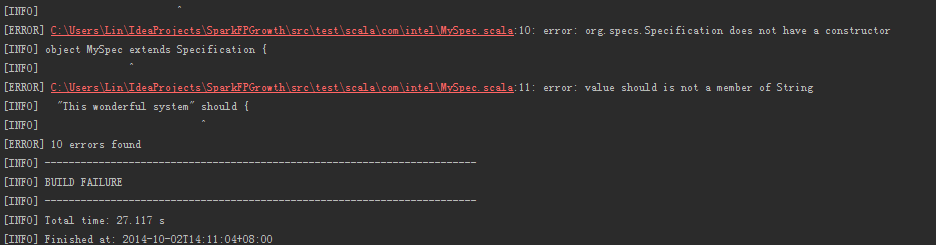
A: 删除test目录下的文件,重新编译。
9. 参考资料
[1] Spark Documentation from Apache. [Link]
Apache Spark1.1.0部署与开发环境搭建的更多相关文章
- Cocos2dx-3.0版本 从开发环境搭建(Win32)到项目移植Android平台过程详解
作为重量级的跨平台开发的游戏引擎,Cocos2d-x在现今的手游开发领域占有重要地位.那么问题来了,作为Cocos2dx的学习者,它的可移植特性我们就需要掌握,要不然总觉得少一门技能.然而这个时候各种 ...
- SDL2.0的VS开发环境搭建
SDL2.0的VS开发环境搭建 [前言] 我是用的是VS2012,VS的版本应该大致一样. [开发环境搭建] >>>SDL2.0开发环境配置:1.从www.libsdl.org 下载 ...
- 一步一步了解Cocos2dx 3.0 正式版本开发环境搭建(Win32/Android)
cocos2d-x 3.0发布有一段时间了,作为一个初学者,我一直觉得cocos2d-x很坑.每个比较大的版本变动,都会有不一样的项目创建方式,每次的跨度都挺大…… 但是凭心而论,3.0RC版本开始 ...
- React Native (0.57)开发环境搭建(注意:Node不要随便更新到最新版,更新完后莫名其妙的问题一大堆)
搭建开发环境 一.安装依赖 必须安装的依赖有:Node.Watchman 和 React Native 命令行工具以及 Xcode. 1.首先安装 Homebrew 2.安装 Node, Watchm ...
- cocos2dx 3.0 windows8下开发环境搭建搭建 不须要cygwin
已经接触cocos2dx有一段时间,但一直也仅仅是看看Demo,没有真正的去写代码.由于本人仅仅是java的coder.还是半路出家的coder,编程基础太浅. 对于c++.lua也不懂.近期coco ...
- MyEclipse2014+JDK1.7+Tomcat8.0+Maven3.2 开发环境搭建
1.JDK的安装 首先下载JDK,这个从sun公司官网可以下载,根据自己的系统选择64位还是32位,安装过程就是next一路到底.安装完成之后当然要配置环境变量了. ————————————————— ...
- quartus2 13.0+modelsim联合开发环境搭建(win10)
quartus2用于硬件设计代码的综合,检查是否有语法错误:modelsim用于对硬件设计代码进行仿真,观察波形是否与需求一致,需要编写xxx_tb.v才能仿真 一.quartus2安装见这篇文章ht ...
- Flask框架的学习与实战(一):开发环境搭建
Flask是一个使用 Python 编写的轻量级 Web 应用框架.其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2.很多功能的实现都参考了django框架.由于项目需要,在 ...
- Hadoop-2.8.0 开发环境搭建(Mac)
Hadoop是一个由Apache基金会开发的分布式系统架构,简称HDFS,具有高容错性.可伸缩性等特点,并且可以部署在低配置的硬件上:同时,提供了高吞吐量的数据访问性能,适用于超大数据集的应用程序,以 ...
随机推荐
- canvas的beginPath和closePath分析总结,包括多段弧的情况
参考博文: Html5 canvas画图教程17:论beginPath的重要性 先看两个例子 例1: <canvas id="myCanvas" width="30 ...
- burpsuite+sqlmap跨登录验证SQL注入
(我操作的系统是kali linux) 1.利用burpsuite代理设置拦截浏览器请求(具体操作步骤可参考:http://www.cnblogs.com/hito/p/4495432.html) 2 ...
- linux系统和Windows系统共存
最近接触了linux系统,因为对linux系统一直存在一种敬畏之心,所以决定研究研究 那么今天我在这里呢是要和大家分享一下在Windows存在的情况下安装双系统linux 那么第一步呢,就是斤BIOS ...
- 给angularJs grid列上添加自定义按钮
由于项目需要在angular 显示的表格中添加按钮,多次查询资料终于找到解决方法.就是给columnDefs 上的列增加 cellTemplate,同时绑定对应的触发事件,代码如下 columnDef ...
- nginx浏览目录
[root@localhost domains]# vi web.jd.com location / proxy_set_header X-Forwarded-For $proxy_add_x_for ...
- 数据库dbutils
common-dbutils.jarQueryRunnerupdate方法:* int update(String sql, Object... params) --> 可执行增.删.改语句* ...
- Android -- 自定义ViewGroup+贝塞尔+属性动画实现仿QQ点赞效果
1,昨天我们写了篇简单的贝塞尔曲线的应用,今天和大家一起写一个QQ名片上常用的给别人点赞的效果,实现效果图如下: 红心的图片比较丑,见谅见谅(哈哈哈哈哈哈).... 2,实现的思路和原理 从上面的效果 ...
- String 类的实现(3)引用计数实现String类
我们知道在C++中动态开辟空间时是用字符new和delete的.其中使用new test[N]方式开辟空间时实际上是开辟了(N*sizeof(test)+4)字节的空间.如图示其中保存N的值主要用于析 ...
- Python之路-计算机基础
一·计算机的组成 一套完整的计算机系统分为:计算机硬件,操作系统,软件. 硬件系统:运算器,控制器和存储器 ,输入设备,输出设备. 1.运算器:负责算数运算和逻辑运算,与控制器一起组成CPU. 2 ...
- POPTEST学员就业面试题目!!!!!
POPTEST学员就业面试题目!!!!! poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.(欢迎大家咨询软件测试工程师就业培训 ...