Your data vis “Spidey-sense” & the need for a robust “utility belt”
@theboysmithy did a great piece on coming up with an alternate view for a timeline for an FT piece.
Here’s an excerpt (read the whole piece, though, it’s worth it):
Here is an example from a story recently featured in the FT: emerging- market populations are expected to age more rapidly than those in developed countries. The figures alone are compelling: France is expected to take 157 years (from 1865 to 2022) to triple the proportion of its population aged over 65, from 7 per cent to 21 per cent; for China, the equivalent period is likely to be just 34 years (from 2001 to 2035).
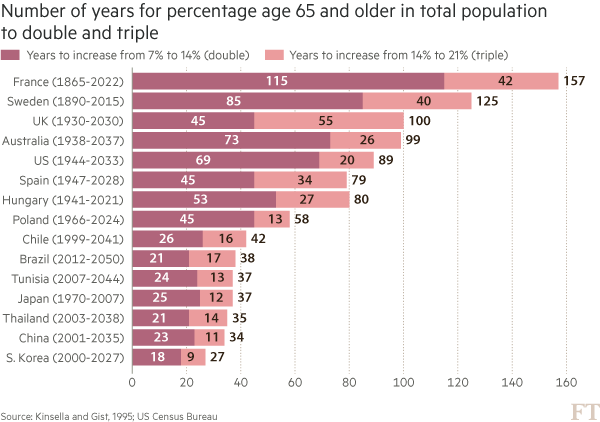
You may think that visualising this story is as simple as creating a bar chart of the durations ordered by length. In fact, we came across just such a chart from a research agency.
But, to me, this approach generates “the feeling” — and further scrutiny reveals specific problems. A reader must work hard to memorise the date information next to the country labels to work out if there is a relationship between the start date and the length of time taken for the population to age. The chart is clearly not ideal, but how do we improve it?
Alan went on to talk about the process of improving the vis, eventually turning to Joseph Priestly for inspiration. Here’s their makeover:
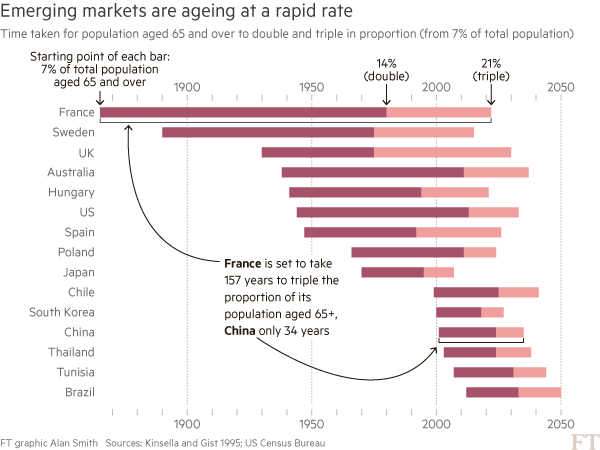
Alan used D3 to make this, which had me head scratching for a bit. Bostock is genius & I :heart: D3 immensely, but I never really thought of it as a “canvas” for doing general data visualization creation for something like a print publication (it’s geared towards making incredibly data-rich interactive visualizations). It’s 100% cool to do so, though. It has fine-grained control over every aspect of a visualization and you can easily turn SVGs into PDFs or use them in programs like Illustrator to make the final enhancements. However, D3 is not the only tool that can make a chart like this.
I made the following in R (of course):
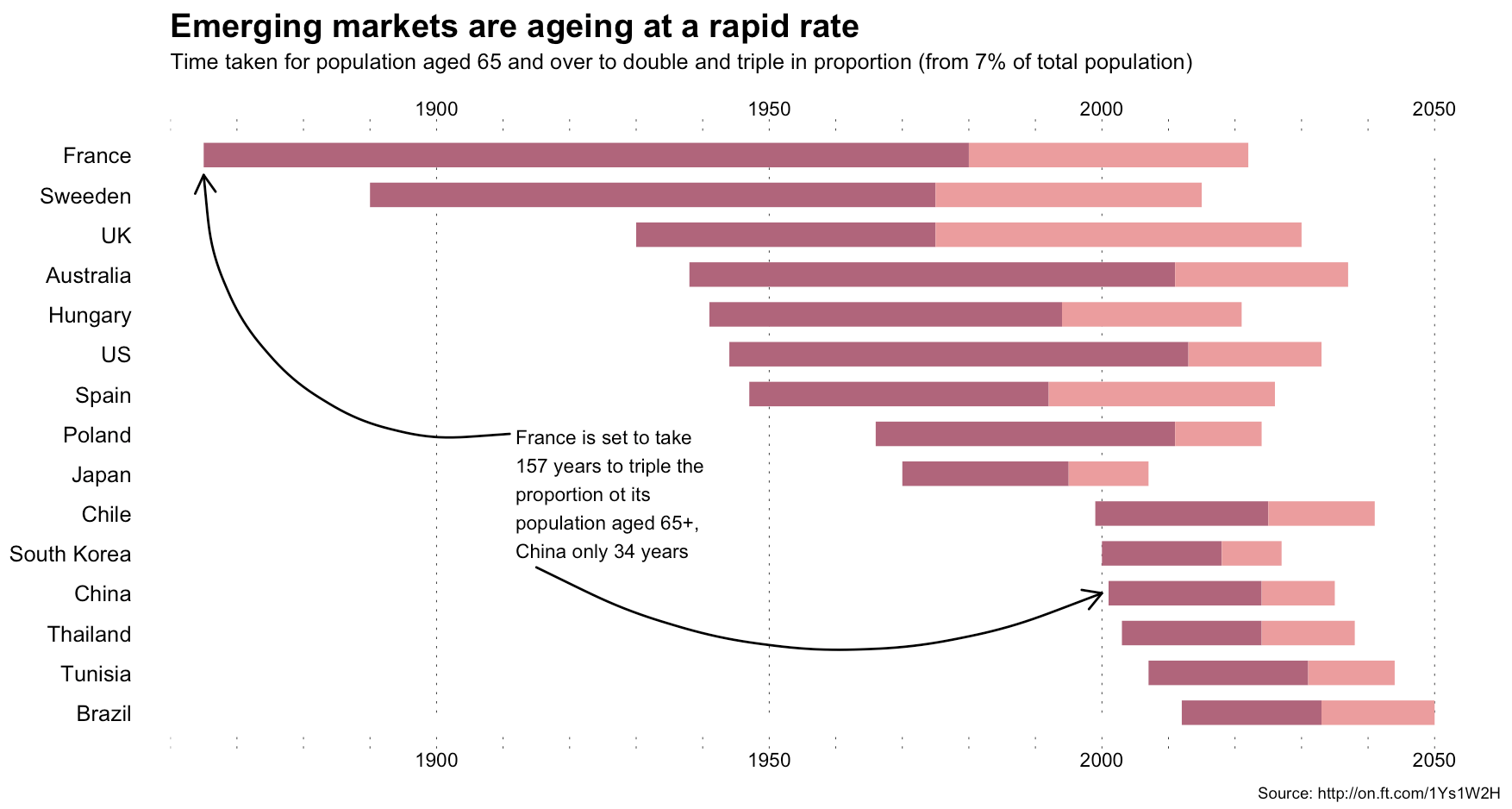
The annotations in Alan’s image were (99% most likely) made with something like Illustrator. I stopped short of fully reproducing the image (life is super-crazy, still), but could have done so (the entire image is one ggplot2 object).
This isn’t an “R > D3” post, though, since I use both. It’s about (a) reinforcing Alan’s posits that we should absolutely take inspiration from historical vis pioneers (so read more!) + need a diverse visualization “utility belt” (ref: Batman) to ensure you have the necessary tools to make a given visualization; (b) trusting your “Spidey-sense” when it comes to evaluating your creations/decisions; and, (c) showing that R is a great alternative to D3 for something like this :-)
Spider-man (you expected headier references from a dude with a shield avatar?) has this ability to sense danger right before it happens and if you’re making an effort to develop and share great visualizations, you definitely have this same sense in your DNA (though I would not recommend tossing pie charts at super-villains to stop them). When you’ve made something and it just doesn’t “feel right”, look to other sources of inspiration or reach out to your colleagues or the community for ideas or guidance. You can and do make awesome things, and you do have a “Spidey-sense”. You just need to listen to it more, add depth and breadth to your “utility belt” and keep improving with each creation you release into the wild.
R code for the ggplot vis reproduction is below, and it + the CSV file referenced are in this gist.
library(ggplot2)
library(dplyr)
ft <- read.csv("ftpop.csv", stringsAsFactors=FALSE)
arrange(ft, start_year) %>%
mutate(country=factor(country, levels=c(" ", rev(country), " "))) -> ft
ft_labs <- data_frame(
x=c(1900, 1950, 2000, 2050, 1900, 1950, 2000, 2050),
y=c(rep(" ", 4), rep(" ", 4)),
hj=c(0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5, 0.5),
vj=c(1, 1, 1, 1, 0, 0, 0, 0)
)
ft_lines <- data_frame(x=c(1900, 1950, 2000, 2050))
ft_ticks <- data_frame(x=seq(1860, 2050, 10))
gg <- ggplot()
# tick marks & gridlines
gg <- gg + geom_segment(data=ft_lines, aes(x=x, xend=x, y=2, yend=16),
linetype="dotted", size=0.15)
gg <- gg + geom_segment(data=ft_ticks, aes(x=x, xend=x, y=16.9, yend=16.6),
linetype="dotted", size=0.15)
gg <- gg + geom_segment(data=ft_ticks, aes(x=x, xend=x, y=1.1, yend=1.4),
linetype="dotted", size=0.15)
# double & triple bars
gg <- gg + geom_segment(data=ft, size=5, color="#b0657b",
aes(x=start_year, xend=start_year+double, y=country, yend=country))
gg <- gg + geom_segment(data=ft, size=5, color="#eb9c9d",
aes(x=start_year+double, xend=start_year+double+triple, y=country, yend=country))
# tick labels
gg <- gg + geom_text(data=ft_labs, aes(x, y, label=x, hjust=hj, vjust=vj), size=3)
# annotations
gg <- gg + geom_label(data=data.frame(), hjust=0, label.size=0, size=3,
aes(x=1911, y=7.5, label="France is set to take\n157 years to triple the\nproportion ot its\npopulation aged 65+,\nChina only 34 years"))
gg <- gg + geom_curve(data=data.frame(), aes(x=1911, xend=1865, y=9, yend=15.5),
curvature=-0.5, arrow=arrow(length=unit(0.03, "npc")))
gg <- gg + geom_curve(data=data.frame(), aes(x=1915, xend=2000, y=5.65, yend=5),
curvature=0.25, arrow=arrow(length=unit(0.03, "npc")))
# pretty standard stuff here
gg <- gg + scale_x_continuous(expand=c(0,0), limits=c(1860, 2060))
gg <- gg + scale_y_discrete(drop=FALSE)
gg <- gg + labs(x=NULL, y=NULL, title="Emerging markets are ageing at a rapid rate",
subtitle="Time taken for population aged 65 and over to double and triple in proportion (from 7% of total population)",
caption="Source: http://on.ft.com/1Ys1W2H")
gg <- gg + theme_minimal()
gg <- gg + theme(axis.text.x=element_blank())
gg <- gg + theme(panel.grid=element_blank())
gg <- gg + theme(plot.margin=margin(10,10,10,10))
gg <- gg + theme(plot.title=element_text(face="bold"))
gg <- gg + theme(plot.subtitle=element_text(size=9.5, margin=margin(b=10)))
gg <- gg + theme(plot.caption=element_text(size=7, margin=margin(t=-10)))
ggYour data vis “Spidey-sense” & the need for a robust “utility belt”的更多相关文章
- Fitting Bayesian Linear Mixed Models for continuous and binary data using Stan: A quick tutorial
I want to give a quick tutorial on fitting Linear Mixed Models (hierarchical models) with a full var ...
- Machine Learning and Data Mining(机器学习与数据挖掘)
Problems[show] Classification Clustering Regression Anomaly detection Association rules Reinforcemen ...
- JavaScript资源大全中文版(Awesome最新版)
Awesome系列的JavaScript资源整理.awesome-javascript是sorrycc发起维护的 JS 资源列表,内容包括:包管理器.加载器.测试框架.运行器.QA.MVC框架和库.模 ...
- PCI Express(四) - The transaction layer
原文出处:http://www.fpga4fun.com/PCI-Express4.html 感觉没什么好翻译的,都比较简单,主要讲了TLP的帧结构 In the transaction layer, ...
- Task schedule 分类: 比赛 HDU 查找 2015-08-08 16:00 2人阅读 评论(0) 收藏
Task schedule Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total ...
- Doubles 分类: POJ 2015-06-12 18:24 11人阅读 评论(0) 收藏
Doubles Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 19954 Accepted: 11536 Descrip ...
- codevs 3732 解方程
神题不可言会. f(x+p)=f(x)(mod p) #include<iostream> #include<cstdio> #include<cstring> # ...
- notes: the architecture of GDB
1. gdb structure at the largest scale,GDB can be said to have two sides to it:1. The "symbol si ...
- poj 2531 Network Saboteur(经典dfs)
题目大意:有n个点,把这些点分别放到两个集合里,在两个集合的每个点之间都会有权值,求可能形成的最大权值. 思路:1.把这两个集合标记为0和1,先默认所有点都在集合0里. 2 ...
随机推荐
- Python 安装虚拟环境
写在前面: 安装指南是在 Ubuntu 下面操作的.不同的 Linux 版本,安装指令不同.所以,该指南的某些指令对于像 CentOS 等非 Ubuntu 系统不适用. 为什么需要使用虚拟环境? 虚拟 ...
- js和android及ios交互
Android中Java和JavaScript交互 这种交互,Hybrid App 会用的比较多一点, 本文将介绍如何实现Java代码和Javascript代码的相互调用. Android提供了一个很 ...
- IO流输入 输出流 字符字节流
一.流 1.流的概念 流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象.即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作. ...
- SIP DB33标准笔记 注册/目录发送/心跳
SIP协议扩展中: 在 RFC 3261 基础上定义了一个新方法 DO.方法 DO 的功能包括:控制对方动作.更新对方信息.查询对方状态.历史监控资料查询和回放等.发送方法 DO 的请求报文时,不会创 ...
- CSS清除float浮动
一.浮动产生原因 - TOP 一般浮动是什么情况呢?一般是一个盒子里使用了CSS float浮动属性,导致父级对象盒子不能被撑开,这样CSS float浮动就产生了. 本来两个黑色对象盒子是在 ...
- stm32中的延时函数
//粗延时函数,微秒 void delay_nus(u16 time) { u16 i=0; while(time--) { i=10; //自己定义 while(i--) ; } } //毫秒级的 ...
- JS+html--实现图片轮播
大家肯定见过某些网站一个炫酷的页面,就是图片轮播,也就是我们常说的幻灯片播放.对于初学者来说,可能会有点头疼,没关系,小李在这给大家献上自己刚刚写好的关于图片轮播的代码. 以下功能的实现用了jQuer ...
- 2017年4月 TIOBE 编程语言排名
2017年4月 TIOBE 编程语言排名 Hack是Facebook 在三年推出的PHP方言,在2017年4月首次进入TIOBE编程语言排行榜前50位. Hack原是Facebook的内部项目,与20 ...
- AJAX做增删改查详细!
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- [ext4]磁盘布局 - group分析
ext4文件系统的磁盘布局是先把磁盘分成一个个相同大小的block块(每个block块的大小默认是4K),然后把这些block块合成一个个group. group大小最大为256M(默认为256M), ...