[Lucene]-Lucene基本概述以及简单实例
一、Lucene基本介绍:
- 基本信息:Lucene 是 Apache 软件基金会的一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
- 文件结构:自上而下树形展开,一对多。
- 索引Index:相当于库或者表。
- 段Segment:相当于分库或者分表。
- 文档Document:相当一条数据 ,如小说吞噬星空
- 域Field:一片文档可以分为多个域,相当于字段,如:小说作者,标题,内容。。。
- 词元Term:一个域又可以分为多个词元,词元是做引搜索的最小单位,标准分词下得词元是一个个单词和汉字。
- 正向信息:
- 索引->段->文档->域->词
- 反向信息:
- 词->文档。
二、Lucene全文检索:
1、数据分类:
- 结构化数据:数据库,固定长度和格式的数据。
- 半结构化数据:如xml,html,等..。
- 非结构化数据:长度和格式都不固定的数据,如文本...
2、检索过程:Luncene检索过程可以分为两个部分,一个部分是上图左侧结构化,半结构化,非结构化数据的索引建立过程,另一部分是右侧索引查询过程。
- 索引过程:
- 有一系列被索引文件
- 被索引文件经过语法分析和语言处理形成一系列词(Term)。
- 经过索引创建形成词典和反向索引表。
- 通过索引存储将索引写入硬盘/内存。
- 搜索过程:
- 用户输入查询关键字。
- 对查询语句经过语法分析和语言分析得到一系列词(Term)。
- 通过语法分析得到一个查询树。
- 通过索引存储将索引读入到内存。
- 利用查询树搜索索引,从而得到每个词(Term)的文档链表,对文档链表进行交,差,并得到结果文档。
- 将搜索到的结果文档对查询的相关性进行排序。
- 返回查询结果给用户。

3、反向索引:
luncene检索关键词,通过索引可以将关键词定位到一篇文档,这种与哦关键词到文档的映射是文档到字符串映射的方向过程,所以称之为方向索引。
4、创建索引:
- document:索引文档,
- 分词技术:各种分词技术,标准分词:中文分成单个汉字,英文单个单词。
- 索引创建:得到一张索引表。
5、索引检索:
- 四个步骤:关键词(keyword)->分词方法(analyzer)->检索索引(searchIndex)->返回结果(result)
- 详细步骤:输入一个关键词,使用分词方法进行分词得到词元,到索引表中去检索这些词元,找到包含所有词源的文档,并将其返回。
三、Lucene的数学模型:
1、关键名词:
- 文档:一篇文章是一篇文档。
- 域:文档有可以分错多个域:如文档名,文档作者,文档时间,文档内容。
- 词元:一个域可以分为多个词元,比如说文档名为中华古诗词简介,通过分词可以得到词元:中,华,古,诗,词,简,介。这个是用标准分词得到,词元是搜索的最小单位。
2、权重计算:
- TF:Term Frequency,词元在这个文档中出现的次数,tf值越大,词越重要。
- DF:Document Frequency,有多少文档包含这个词元,df越大,那么词就越不重要。
- 权重计算公式:Wt,d=TFt,d * log(n/DFt),TFt,d表示词元t在文档d出现的次数,n表示文档数,DFt表示包含词元t的文档数。
3、空间向量模型:
- 用一篇文档的每次词元的权重构成一个向量(每个词元的权重值作为向量的维度)来表示这篇文档,这样所有的文档都可以表示成一个N维的空间向量。N表示所有文档分词后的词元集合的词元总数。实例如下:
- 检索过程:m篇文档我们得到了m个N维的空间向量,搜索词我们分词得到x个词元,计算这x个词元的权重,得到一个N维的向量XV,通过计算XV和m个N维向量的相似度(余玄夹角)来表示相关性。Lucene通过这个相关性打分机制来得到返回的文档。
四、官方示例Demo:
- 下载源代码和jar:http://lucene.apache.org/core/
- 核心jar包如下:

运行源代码中的demo实例文件和LucenecoreAPI中示例,来看看luncene是如何创建Index和检索的。
- 用Idea构建了一个java项目:如下所示添加这6个核心包,和示例文件。
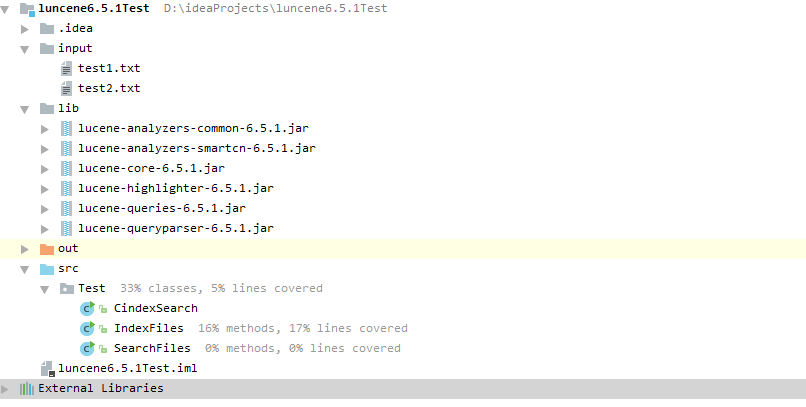
- IndexFiles,SearchFiles分别是遍历一个文件目录创建索引和手动输入关键词检索返回命中文件。CindexSrarch是实例一个内存索引创建并添加文档,最终检索的过程。
package Test; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.RAMDirectory; import java.io.IOException; /**
* Created by rzx on 2017/6/1.
*/
public class CindexSearch { public static void createIndexANDSearchIndex() throws Exception{
Analyzer analyzer = new StandardAnalyzer();//标准分词器
//RAMDirectory内存字典存储索引
Directory directory = new RAMDirectory();
//Directory directory = FSDirectory.open("/tmp/testindex");磁盘存储索引 IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(directory,config);
Document document = new Document();
String text = "hello world main test";
document.add(new Field("filetest",text, TextField.TYPE_STORED)); //将域field添加到document中
writer.addDocument(document);
writer.close(); DirectoryReader directoryReader = DirectoryReader.open(directory);
IndexSearcher isearch = new IndexSearcher(directoryReader);
QueryParser parser = new QueryParser("filetest",new StandardAnalyzer());
Query query = parser.parse("main");//查询main关键词
ScoreDoc [] hits = isearch.search(query,1000).scoreDocs;
for (int i = 0; i <hits.length ; i++) {
Document hitdoc =isearch.doc(hits[i].doc);
System.out.print("命中的文件内容:"+hitdoc.get("filetest"));
}
directoryReader.close();
directory.close();
}
public static void main(String[] args) {
try {
createIndexANDSearchIndex();
} catch (Exception e) {
e.printStackTrace();
}
}
}运行结果:

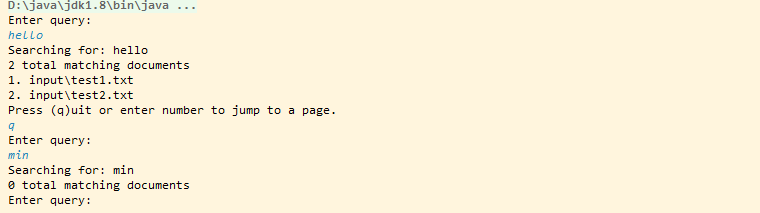
input目录中创建了两个文件test1.txt,test2.txt,内容分别是:hello world和hello main man test。运行IndexFiles读取input目录,并自动创建一个testindex索引目录,结果如下:


目录中创建了testindex文件,里面存储索引相关信息。运行SearchFiles如下:分别在控制台输入检索关键字:hello,min
五、核心类:
建立索引:Analyzer,Director(RAMDirectory,FSDirectory),IndexWriterConfig,IndexWriter,Document
* Analyzer analyzer = new StandardAnalyzer(); //实例化分词器
* Directory directory = new RAMDirectory(); //初始化内存索引目录
* Directory directory = FSDirectory.open("indexpath");//初始化磁盘存储索引
* IndexWriterConfig config = new IndexWriterConfig(analyzer); //索引器配置
* IndexWriter writer = new IndexWriter(directory,config); //索引器
* Document document = new Document(); //初始化Document,用来存数据。- 查询索引:DirectoryReader,IndexSearch,QueryParser,MutilFieldQueryParser,
* DirectoryReader directoryReader = DirectoryReader.open(directory); //索引目录读取器
* IndexSearcher isearch = new IndexSearcher(directoryReader); //索引查询器
*多种检索方式:
* QueryParser单字段<域>绑定:
QueryParser qparser = new QueryParser("filed",new StandardAnalyzer()); //查询解析器:参数Field域,分词器
Query query = qparser.parse("main") //查询关键词
* MultiFieldQueryParser多字段<域>绑定():
QueryParser qparser2 = new MultiFieldQueryParser(new String[]{"field1","field2"},new StandardAnalyzer());//多字段查询解析器
Query query = qparser2.parse("main") //查询关键词
* Term绑定字段<域>查询:new Term(field,keyword);
Term term =new Term("content","main");
Query query = new TermQuery(term);
*更多方法:参照http://blog.csdn.net/chenghui0317/article/details/10824789
* ScoreDoc [] hits = isearch.search(query,1000).scoreDocs; //查询你命中的文档以及评分和所在分片- 高亮显示:SimpleHTMLFormatter,Highlighter,SimpleFragmenter
SimpleHTMLFormatter formatter=new SimpleHTMLFormatter("<b><font color='red'>","</font></b>");
Highlighter highlighter=new Highlighter(formatter, new QueryScorer(query));
highlighter.setTextFragmenter(new SimpleFragmenter(400));
String conten = highlighter.getBestFragment(new StandardAnalyzer(),"contents","hello main man test");- 内置分词器:Lucene中实现了很多分词器,有针对性的应用各个场景和各种语言。
QueryParser qparser = new QueryParser("content",new SimpleAnalyzer());
QueryParser qparser = new QueryParser("content",new ClassicAnalyzer());
QueryParser qparser = new QueryParser("content",new KeywordAnalyzer());
QueryParser qparser = new QueryParser("content",new StopAnalyzer());
QueryParser qparser = new QueryParser("content",new UAX29URLEmailAnalyzer());
QueryParser qparser = new QueryParser("content",new UnicodeWhitespaceAnalyzer());
QueryParser qparser = new QueryParser("content",new WhitespaceAnalyzer());
QueryParser qparser = new QueryParser("content",new ArabicAnalyzer());
QueryParser qparser = new QueryParser("content",new ArmenianAnalyzer());
QueryParser qparser = new QueryParser("content",new BasqueAnalyzer());
QueryParser qparser = new QueryParser("content",new BrazilianAnalyzer());
QueryParser qparser = new QueryParser("content",new BulgarianAnalyzer());
QueryParser qparser = new QueryParser("content",new CatalanAnalyzer());
QueryParser qparser = new QueryParser("content",new CJKAnalyzer());
QueryParser qparser = new QueryParser("content",new CollationKeyAnalyzer());
QueryParser qparser = new QueryParser("content",new CustomAnalyzer(Version defaultMatchVersion, CharFilterFactory[] charFilters, TokenizerFactory
tokenizer, TokenFilterFactory[] tokenFilters, Integer posIncGap, Integer offsetGap));
QueryParser qparser = new QueryParser("content",new SmartChineseAnalyzer());//中文最长分词
六、高亮示例:
- 读取indexfile创建的索引testindex,并查询关键字main并高亮。出现异常:Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/lucene/index/memory/MemoryIndex需要导入:lucene-memory-6.5.1.jar,这个包用来处理存储位置的偏移量,可以让我们在文本中定位到关键词元.
public static void searchByIndex(String indexFilePath,String keyword) throws ParseException, InvalidTokenOffsetsException {
try {
String indexDataPath="testindex";
String keyWord = "main";
Directory dir= FSDirectory.open(new File(indexDataPath).toPath());
IndexReader reader= DirectoryReader.open(dir);
IndexSearcher searcher=new IndexSearcher(reader);
QueryParser queryParser = new QueryParser("contents",new StandardAnalyzer());
Query query = queryParser.parse("main"); TopDocs topdocs=searcher.search(query,10);
ScoreDoc[] scoredocs=topdocs.scoreDocs;
System.out.println("最大的评分:"+topdocs.getMaxScore());
for(int i=0;i<scoredocs.length;i++){
int doc=scoredocs[i].doc;
Document document=searcher.doc(doc);
System.out.println("=====================================");
System.out.println("关键词:"+keyWord);
System.out.println("文件路径:"+document.get("path"));
System.out.println("文件ID:"+scoredocs[i].doc);
//开始高亮
SimpleHTMLFormatter formatter=new SimpleHTMLFormatter("<b><font color='red'>","</font></b>");
Highlighter highlighter=new Highlighter(formatter, new QueryScorer(query));
highlighter.setTextFragmenter(new SimpleFragmenter(400));
String conten = highlighter.getBestFragment(new StandardAnalyzer(),"contents","hello main man test");
//String conten = highlighter.getBestFragment(new StandardAnalyzer(),"contents",document.get("content")); System.out.println("文件内容:"+conten);
System.out.println("相关度:"+scoredocs[i].score);
}
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}输出结果:

源代码:https://codeload.github.com/NextNight/luncene6.5.1Test/zip/master
[Lucene]-Lucene基本概述以及简单实例的更多相关文章
- Flume概述和简单实例
Flume概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方( ...
- JMeter学习-008-JMeter 后置处理器实例之 - 正则表达式提取器(一)概述及简单实例
上文我们讲述了如何对 HTTP请求 的响应数据进行断言,以判断响应是否符合我们的预期,敬请参阅:JMeter学习-007-JMeter 断言实例之一 - 响应断言 那么我们如何获取 HTTP请求 响应 ...
- lucene构建restful风格的简单搜索引擎服务
来自于本人博客: lucene构建restful风格的简单搜索引擎服务 本人的博客如今也要改成使用lucene进行全文检索的功能,因此在这里把代码贴出来与大家分享 一,文件夹结构: 二,配置文件: 总 ...
- ajax原理总结附简单实例及其优点
在工作中用了Ajax N多次了,也看过一些相关方面的书籍,也算是认识了它,但是一直没有认真总结和整理过相关的东东,失败! 近有闲情,将之总结如下: [名称] Ajax是Asynchronous Jav ...
- 1.搜索引擎的历史,搜索引擎起步,发展,繁荣,搜索引擎的原理,搜索技术用途,信息检索过程,倒排索引,什么是Lucene,Lucene快速入门
一: 1 搜索引擎的历史 萌芽:Archie.Gopher Archie:搜索FTP服务器上的文件 Gopher:索引网页 2 起步:Robot(网络机器人)的出现与spider(网络爬虫) ...
- Spring boot项目搭建及简单实例
Spring boot项目搭建 Spring Boot 概述 Build Anything with Spring Boot:Spring Boot is the starting point for ...
- Hibernate(二)__简单实例入门
首先我们进一步理解什么是对象关系映射模型? 它将对数据库中数据的处理转化为对对象的处理.如下图所示: 入门简单实例: hiberante 可以用在 j2se 项目,也可以用在 j2ee (web项目中 ...
- 最新 Eclipse IDE下的Spring框架配置及简单实例
前段时间开始着手学习Spring框架,又是买书又是看视频找教程的,可是鲜有介绍如何配置Spring+Eclipse的方法,现在将我的成功经验分享给大家. 本文的一些源代码来源于码农教程:http:// ...
- 修改js confirm alert 提示框文字的简单实例
修改js confirm alert 提示框文字的简单实例: <!DOCTYPE html> <html> <head lang="en"> & ...
随机推荐
- CF #365 703D. Mishka and Interesting sum
题目描述 D. Mishka and Interesting sum的意思就是给出一个数组,以及若干询问,每次询问某个区间[L, R]之间所有出现过偶数次的数字的异或和. 这个东西乍看很像是经典问题, ...
- vim 字符串替换整理
公司项目测试,要在vi编辑其中进行多路径修改,这时候用到了字符串替换的知识,在这里我自己整理了一下. 一.基本内容替换,无特殊符号 :s/old/new/ 替换当前行第一个 old 为 new ...
- hadoop+hive+spark搭建(三)
一.spark安装 因为之前安装过hadoop,所以,在“Choose a package type”后面需要选择“Pre-build with user-provided Hadoop [can ...
- 构建你人生里的第一个 Laravel 项目
安装 Laravel 安装器 composer global require "laravel/installer" 创建项目 laravel new links 检查是否安装成功 ...
- SpringMVC 国际化-中英文切换
项目结构 1.pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http: ...
- 一句话告诉你JQuery $(this)到底指的是什么,怎么用
看了网上好多关于jquery $(this)的解释,感觉都说的很模糊. 下面说出我自己的理解. this表示的是当前对象,下面以例子来说明 <!DOCTYPE html> <html ...
- Docker - 在Windows7中安装Docker
安装docker 1 - Virtualization Support Check whether virtualization support is enabled at BIOS via HAV ...
- Scrapy 爬虫框架入门案例详解
欢迎大家关注腾讯云技术社区-博客园官方主页,我们将持续在博客园为大家推荐技术精品文章哦~ 作者:崔庆才 Scrapy入门 本篇会通过介绍一个简单的项目,走一遍Scrapy抓取流程,通过这个过程,可以对 ...
- 使用gnuplot对tpcc-mysql压测结果生成图表
tpcc-mysql的安装:http://www.cnblogs.com/lizhi221/p/6814003.html tpcc-mysql的使用:http://www.cnblogs.com/li ...
- 玩一玩nodejs--一个简单的在线实时填表应用
学习nodejs三天,入了个门,感觉他和jsp.php还是存在较大的差别.本文首先复习这些天学的一些知识点,然后谈一下如何一步一步到做一个在线实时填表的小应用,进一步巩固一下这些个知识点.这里先简单介 ...