重要 | Spark和MapReduce的对比,不仅仅是计算模型?
【前言:笔者将分上下篇文章进行阐述Spark和MapReduce的对比,首篇侧重于"宏观"上的对比,更多的是笔者总结的针对"相对于MapReduce我们为什么选择Spark"之类的问题的几个核心归纳点;次篇则从任务处理级别运用的并行机制/计算模型方面上对比,更多的是让大家对Spark为什么比MapReduce快有一个更深、更全面的认识。通过两篇文章的解读,希望帮助大家对Spark和MapReduce有一个更深入的了解,并且能够在遇到诸如"MapReduce相对于Spark的局限性?"等类似的面试题时能够得到较好地表现,顺利拿下offer】
>> 上篇
首先纠正一个误区:在浏览Spark官网时,经常能看到如下这张图:
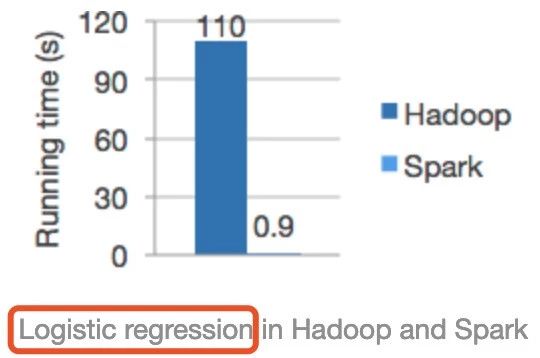
从上图可以看出Spark的运行速度明显比Hadoop(其实是跟MapReduce计算引擎对比)快上百倍!相信很多人在初学Spark时,认为Spark比MapReduce快的第一直观概念都是由此而来,甚至笔者发现网上有些资料更是直接照搬这个对比,给初学者造成一个很严重的误区。
这张图是分别使用Spark和Hadoop运行逻辑回归机器学习算法的运行时间比较,那么能代表Spark运行任何类型的任务在相同的条件下都能得到这个对比结果吗?很显然是不对的,对于这个对比我们要知其然更要知其所以然。
首先,大多数机器学习算法的核心是什么?就是对同一份数据在训练模型时,进行不断的迭代、调参然后形成一个相对优的模型。而Spark作为一个基于内存迭代式大数据计算引擎很适合这样的场景,之前的文章《Spark RDD详解》也有介绍,对于相同的数据集,我们是可以在第一次访问它之后,将数据集加载到内存,后续的访问直接从内存中取即可。但是MapReduce由于运行时中间结果必然刷磁盘等因素,导致不适合机器学习等的迭代场景应用,还有就是HDFS本身也有缓存功能,官方的对比极有可能在运行逻辑回归时没有很好配置该缓存功能,否则性能差距也不至于这么大。
相对于MapReduce,我们为什么选择Spark,笔者做了如下总结:
>> Spark
1.集流批处理、交互式查询、机器学习及图计算等于一体
2.基于内存迭代式计算,适合低延迟、迭代运算类型作业
3.可以通过缓存共享rdd、DataFrame,提升效率【尤其是SparkSQL可以将数据以列式的形式存储于内存中】
4.中间结果支持checkpoint,遇错可快速恢复
5.支持DAG、map之间以pipeline方式运行,无需刷磁盘
6.多线程模型,每个worker节点运行一个或多个executor服务,每个task作为线程运行在executor中,task间可共享资源
7.Spark编程模型更灵活,支持多种语言如java、scala、python、R,并支持丰富的transformation和action的算子
>> MapReduce
1.适合离线数据处理,不适合迭代计算、交互式处理、流式处理
2.中间结果需要落地,需要大量的磁盘IO和网络IO影响性能
3.虽然MapReduce中间结果可以存储于HDFS,利用HDFS缓存功能,但相对Spark缓存功能较低效
4.多进程模型,任务调度(频繁申请、释放资源)和启动开销大,不适合低延迟类型作业
5.MR编程不够灵活,仅支持map和reduce两种操作。当一个计算逻辑复杂的时候,需要写多个MR任务运行【并且这些MR任务生成的结果在下一个MR任务使用时需要将数据持久化到磁盘才行,这就不可避免的进行遭遇大量磁盘IO影响效率】
但是,虽然Spark相对于MapReduce有很多优势,但并不代表Spark目前可以完全取代MapReduce。
笔者之前负责的一个任务,数据存储格式是parquet,压缩比比较高,解压后数据量剧增,又加上存在一些大字段问题,任务比较复杂仅sql语句就几千行,导致Spark处理时总是报OOM,在有限的资源试了各种调优方法都不能使任务正常稳定的运行。最后改用Hive的原生引擎MapReduce执行,在资源配置相同的情况下,任务能够稳定运行,而且速度并没有想象中的那么慢。所以,对于技术之间的对比以及应用,还是建议首先要对技术本身有深入的理解比如设计思想、编程模型、源码分析等,并且要结合实际的业务场景需求等,不能空谈技术。
>> 下篇
【前言:本文主要从任务处理的运行模式为角度,分析Spark计算模型,希望帮助大家对Spark有一个更深入的了解。同时拿MapReduce和Spark计算模型做对比,强化对Spark和MapReduce理解】
从整体上看,无论是Spark还是MapReduce都是多进程模型。如,MapReduce是由很多MapTask、ReduceTask等进程级别的实例组成的;Spark是由多个worker、executor等进程级别实例组成。但是当细分到具体的处理任务,MapReduce仍然是多进程级别,这一点在文章《详解MapReduce》已有说明。而Spark处理任务的单位task是运行在executor中的线程,是多线程级别的。
对于多进程,我们可以很容易控制它们能够使用的资源,并且一个进程的失败一般不会影响其他进程的正常运行,但是进程的启动和销毁会占用很多时间,同时该进程申请的资源在进程销毁时也会释放,这就造成了对资源的频繁申请和释放也是很影响性能的,这也是MapReduce广为诟病的原因之一。
对于MapReduce处理任务模型,有如下特点:
1.每个MapTask、ReduceTask都各自运行在一个独立的JVM进程中,因此便于细粒度控制每个task占用的资源(资源可控性好)
2.每个MapTask/ReduceTask都要经历申请资源 -> 运行task -> 释放资源的过程。强调一点:每个MapTask/ReduceTask运行完毕所占用的资源必须释放,并且这些释放的资源不能够为该任务中其他task所使用
3.可以通过JVM重用在一定程度上缓解MapReduce让每个task动态申请资源且运行完后马上释放资源带来的性能开销
但是JVM重用并不是多个task可以并行运行在一个JVM进程中,而是对于同一个job,一个JVM上最多可以顺序执行的task数目,这个需要配置参数mapred.job.reuse.jvm.num.tasks,默认1。
对于多线程模型的Spark正好与MapReduce相反,这也决定了Spark比较适合运行低延迟的任务。在Spark中处于同一节点上的task以多线程的方式运行在一个executor进程中,构建了一个可重用的资源池,有如下特点:
1.每个executor单独运行在一个JVM进程中,每个task则是运行在executor中的一个线程。很显然线程线程级别的task启动速度更快
2.同一节点上所有task运行在一个executor中,有利于共享内存。比如通过Spark的广播变量,将某个文件广播到executor端,那么在这个executor中的task不用每个都拷贝一份处理,而只需处理这个executor持有的共有文件即可
3.executor所占资源不会在一些task运行结束后立即释放掉,可连续被多批任务使用,这避免了每个任务重复申请资源带来的开销
但是多线程模型有一个缺陷:同一节点的一个executor中多个task很容易出现资源征用。毕竟资源分配最细粒度是按照executor级别的,无法对运行在executor中的task做细粒度控制。这也导致在运行一些超大数据量的任务并且资源比较有限时,运行不太稳定。相比较而言,MapReduce更有利于这种大任务的平稳运行。
关注微信公众号:大数据学习与分享,获取更对技术干货
重要 | Spark和MapReduce的对比,不仅仅是计算模型?的更多相关文章
- 详解MapReduce(Spark和MapReduce对比铺垫篇)
本来笔者是不打算写MapReduce的,但是考虑到目前很多公司还都在用这个计算引擎,以及后续要讲的Hive原生支持的计算引擎也是MapReduce,并且为Spark和MapReduce的对比做铺垫,笔 ...
- hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析 Spark是一种快速.通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(一)
本文由 网易云发布. 1.Flink架构及特性分析 Flink是个相当早的项目,开始于2008年,但只在最近才得到注意.Flink是原生的流处理系统,提供high level的API.Flink也提 ...
- Apache 流框架 Flink,Spark Streaming,Storm对比分析(二)
本文由 网易云发布. 本文内容接上一篇Apache 流框架 Flink,Spark Streaming,Storm对比分析(一) 2.Spark Streaming架构及特性分析 2.1 基本架构 ...
- spark与storm的对比
对比点 Storm Spark Streaming 实时计算模型 纯实时,来一条数据,处理一条数据 准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 实时计算延迟度 毫秒级 秒级 吞吐量 ...
- Alluxio增强Spark和MapReduce存储能力
Alluxio的前身为Tachyon.Alluxio是一个基于内存的分布式文件系统:Alluxio以内存为中心设计,他处在诸如Amazon S3. Apache HDFS 或 OpenStack Sw ...
- Spark 颠覆 MapReduce 保持的排序记录
在过去几年,Apache Spark的採用以惊人的速度添加着,通常被作为MapReduce后继,能够支撑数千节点规模的集群部署. 在内存中数 据处理上,Apache Spark比MapReduce更加 ...
- 【CDN+】 Spark入门---Handoop 中的MapReduce计算模型
前言 项目中运用了Spark进行Kafka集群下面的数据消费,本文作为一个Spark入门文章/笔记,介绍下Spark基本概念以及MapReduce模型 Spark的基本概念: 官网: http://s ...
- Spark与Hadoop计算模型的比较分析
http://tech.it168.com/a2012/0401/1333/000001333287.shtml 最近很多人都在讨论Spark这个貌似通用的分布式计算模型,国内很多机器学习相关工作者都 ...
随机推荐
- JQuery实现tab页
用ul 和 div 配合实现tab 页 1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="U ...
- 【题解】 [EZEC-4]求和
对于百分之十的数据:随便过. 下面推式子: \[\sum_{i=1}^n\sum_{j=1}^n\gcd(i,j)^{i+j} \] \[=\sum_{d=1}^n\sum_{i=1}^n\sum_{ ...
- vue+elementUI实现 分页表格的单选或者多选、及禁止部分选择
一.vue+elementUI实现 分页表格前的多选 多选效果图: 代码如下: <el-table ref="multipleTable" :data="listD ...
- Python 导入模块的两种方法:import xxx 和from...import xxx
import 方式导入模块 import tool.getsum.add # 导入模块,优先会从启动文件的当前目录开始寻找 # 如果找到,就使用 # 如果找不到,会在系统模块存放目录去 tool.ge ...
- ubuntu20 使用命令安装 mongodb
安装 mongodb sudo apt-get install mongodb -y mongodb 服务管理 # 启动 mongodb 服务 service mongodb start # 关闭 m ...
- 常见的Mysql十款高可用方案
简介 我们在考虑MySQL数据库的高可用架构时,主要考虑如下几方面: 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中断. 用作 ...
- centos7 yum 安装nodejs、npm、cnpm、pm2、yarn
一.环境准备 1.1 查看系统环境 [root@localhost ~]# cat /etc/redhat-release CentOS Linux release 7.5.1804 (Core) [ ...
- 云原生 go-zero 微服务框架
0. go-zero介绍 go-zero是一个集成了各种工程实践的web和rpc框架.通过弹性设计保障了大并发服务端的稳定性,经受了充分的实战检验. go-zero包含极简的API定义和生成工具goc ...
- 使用AirtestProject+pytest做支付宝小程序UI自动化测试
一,前言 1,背景 因公司业务需要做支付宝小程序的UI自动化测试,于是在网上查找小程序的自动化资料,发现微信小程序是有自己的测试框架的,但几乎找不到支付宝小程序UI自动化测试相关的资料.白piao失败 ...
- CSGO 服务端扩展插件开发记录之"DropClientReason"(1)
最近开始接触到了CSGO这款游戏,还是老套路,就是想千方百计的从里面增添新的游戏功能,当然刚开始想做到游刃有余是有点困难, 跟之前做CS1.6的第三方开发一样,都得自己慢慢的摸索过来,纵然CSGO所使 ...