2020重新出发,MySql基础,MySql字符集
MySQL字符集和校对规则详解
先来简单了解一下字符、字符集和字符编码。
字符(Character):是计算机中字母、数字、符号的统称,一个字符可以是一个中文汉字、一个英文字母、一个阿拉伯数字、一个标点符号等。
- 计算机是以二进制的形式来存储数据的。平时我们在显示器上看到的数字、英文、标点符号、汉字等字符都是二进制数转换之后的结果。
字符集(Character set):定义了字符和二进制的对应关系,为字符分配了唯一的编号。常见的字符集有 ASCII、GBK、IOS-8859-1 等。
字符编码(Character encoding):也可以称为字集码,规定了如何将字符的编号存储到计算机中。大部分字符集都只对应一种字符编码。
- 例如:ASCII、IOS-8859-1、GB2312、GBK,都是既表示了字符集又表示了对应的字符编码。所以一般情况下,可以将两者视为同义词。Unicode 字符集除外,Unicode 有三种编码方案,即 UTF-8、UTF-16 和 UTF-32。最为常用的是 UTF-8 编码。
校对规则(Collation):也可以称为排序规则,是指在同一个字符集内字符之间的比较规则。字符集和校对规则是一对多的关系,每个字符集都有一个默认的校对规则。字符集和校对规则相辅相成,相互依赖关联。
简单来说,字符集用来定义 MySQL 存储字符串的方式,校对规则用来定义 MySQL 比较字符串的方式。
有些数据库并没有清晰的区分开字符集和校对规则。
- 例如,在 SQL Server 中创建数据库时,选择字符集就相当于选定了字符集和校对规则。
而在 MySQL 中,字符集和校对规则是区分开的,必须设置字符集和校对规则。一般情况下,没有特殊需求,只设置其一即可。只设置字符集时,MySQL 会将校对规则设置为字符集中对应的默认校对规则。
可以通过SHOW VARIABLES LIKE 'character%';命令查看当前 MySQL 使用的字符集,命令和运行结果如下:
mysql> SHOW VARIABLES LIKE 'character%';
+--------------------------+---------------------------------------------------------+
| Variable_name | Value |
+--------------------------+---------------------------------------------------------+
| character_set_client | gbk |
| character_set_connection | gbk |
| character_set_database | latin1 |
| character_set_filesystem | binary |
| character_set_results | gbk |
| character_set_server | latin1 |
| character_set_system | utf8 |
| character_sets_dir | C:\Program Files\MySQL\MySQL Server 5.7\share\charsets\ |
+--------------------------+---------------------------------------------------------+
8 rows in set, 1 warning (0.01 sec)
上述运行结果说明如下表所示:
- character_set_client :MySQL 客户端使用的字符集
- character_set_connection :连接数据库时使用的字符集
- character_set_database : 创建数据库使用的字符集
- character_set_filesystem :MySQL 服务器文件系统使用的字符集,默认值为 binary,不做任何转换
- character_set_results : 数据库给客户端返回数据时使用的字符集
- character_set_server : MySQL 服务器使用的字符集,建议由系统自己管理,不要人为定义
- character_set_system :数据库系统使用的字符集,默认值为 utf8,不需要设置 character_sets_dir 字符集的安装目录
注意:乱码时,不需要关心 character_set_filesystem、character_set_system 和 character_sets_dir 这 3 个系统变量,它们不会影响乱码 。
可以通过SHOW VARIABLES LIKE 'collation\_%';命令查看当前 MySQL 使用的校对规则,命令和运行结果如下:
mysql> SHOW VARIABLES LIKE 'collation\_%';
+----------------------+-------------------+
| Variable_name | Value |
+----------------------+-------------------+
| collation_connection | gbk_chinese_ci |
| collation_database | latin1_swedish_ci |
| collation_server | latin1_swedish_ci |
+----------------------+-------------------+
3 rows in set, 1 warning (0.01 sec)
对上述运行结果说明如下:
- collation_connection:连接数据库时使用的校对规则
- collation_database:创建数据库时使用的校对规则
- collation_server:MySQL 服务器使用的校对规则
校对规则命令约定如下:
- 以校对规则所对应的字符集名开头
- 以国家名居中(或以 general 居中)
- 以 ci、cs 或 bin 结尾,ci 表示大小写不敏感,cs 表示大小写敏感,bin 表示按二进制编码值比较。
MySQL字符集的转换过程
MySQL 中字符集的转换过程如下:
- 在命令提示符窗口(cmd 命令行)中执行 MySQL 命令或 sql 语句时,这些命令或语句从“命令提示符窗口字符集”转换为“character_set_client”定义的字符集。
- 使用命令提示符窗口成功连接 MySQL 服务器后,就建立了一条“数据通信链路”,MySQL 命令或 sql 语句沿着“数据链路”传向 MySQL 服务器,由 character_set_client 定义的字符集转换为 character_set_connection 定义的字符集。
- MySQL 服务实例收到数据通信链路中的 MySQL 命令或 sql 语句后,将 MySQL 命令或 sql 语句从 character_set_connection 定义的字符集转换为 character_set_server 定义的字符集。
- 若 MySQL 命令或 sql 语句针对于某个数据库进行操作,此时将 MySQL 命令或 sql 语句从 character_set_server 定义的字符集转换为 character_set_database 定义的字符集。
- MySQL 命令或 sql 语句执行结束后,将执行结果设置为 character_set_results 定义的字符集。
- 执行结果沿着打开的数据通信链路原路返回,将执行结果从 character_set_results 定义的字符集转换为 character_set_client 定义的字符集,最终转换为命令提示符窗口字符集,显示到命令提示符窗口中。
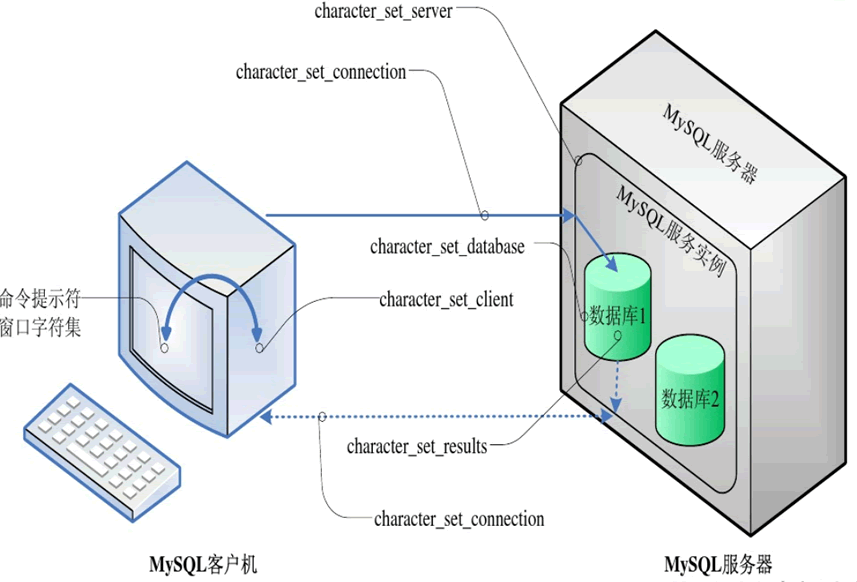
MySQL查看字符集和校对规则
在 MySQL 中,查看可用字符集的命令和执行过程如下:
SHOW CHARACTER set
mysql> SHOW CHARACTER set;
+----------+---------------------------------+---------------------+--------+
| Charset | Description | Default collation | Maxlen |
+----------+---------------------------------+---------------------+--------+
| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 |
| dec8 | DEC West European | dec8_swedish_ci | 1 |
| cp850 | DOS West European | cp850_general_ci | 1 |
| hp8 | HP West European | hp8_english_ci | 1 |
| koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 |
| latin1 | cp1252 West European | latin1_swedish_ci | 1 |
| latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 |
| swe7 | 7bit Swedish | swe7_swedish_ci | 1 |
| ascii | US ASCII | ascii_general_ci | 1 |
| ujis | EUC-JP Japanese | ujis_japanese_ci | 3 |
| sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 |
| hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 |
| tis620 | TIS620 Thai | tis620_thai_ci | 1 |
| euckr | EUC-KR Korean | euckr_korean_ci | 2 |
| koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 |
| gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 |
| greek | ISO 8859-7 Greek | greek_general_ci | 1 |
| cp1250 | Windows Central European | cp1250_general_ci | 1 |
| gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 |
| latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 |
| armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 |
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 |
| cp866 | DOS Russian | cp866_general_ci | 1 |
| keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 |
| macce | Mac Central European | macce_general_ci | 1 |
| macroman | Mac West European | macroman_general_ci | 1 |
| cp852 | DOS Central European | cp852_general_ci | 1 |
| latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_general_ci | 4 |
| cp1251 | Windows Cyrillic | cp1251_general_ci | 1 |
| utf16 | UTF-16 Unicode | utf16_general_ci | 4 |
| utf16le | UTF-16LE Unicode | utf16le_general_ci | 4 |
| cp1256 | Windows Arabic | cp1256_general_ci | 1 |
| cp1257 | Windows Baltic | cp1257_general_ci | 1 |
| utf32 | UTF-32 Unicode | utf32_general_ci | 4 |
| binary | Binary pseudo charset | binary | 1 |
| geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 |
| cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 |
| eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 |
| gb18030 | China National Standard GB18030 | gb18030_chinese_ci | 4 |
+----------+---------------------------------+---------------------+--------+
41 rows in set (0.02 sec)
其中:
- 第一列(Charset)为字符集名称;
- 第二列(Description)为字符集描述;
- 第三列(Default collation)为字符集的默认校对规则;
- 第四列(Maxlen)表示字符集中一个字符占用的最大字节数。
常用的字符集如下:
- latin1 支持西欧字符、希腊字符等。
- gbk 支持中文简体字符。
- big5 支持中文繁体字符。
- utf8 几乎支持所有国家的字符。
也可以通过查询 information_schema.character_set 表中的记录,来查看 MySQL 支持的字符集。SQL 语句和执行过程如下:
mysql> SELECT * FROM information_schema.character_sets;
+--------------------+----------------------+---------------------------------+--------+
| CHARACTER_SET_NAME | DEFAULT_COLLATE_NAME | DESCRIPTION | MAXLEN |
+--------------------+----------------------+---------------------------------+--------+
| big5 | big5_chinese_ci | Big5 Traditional Chinese | 2 |
| dec8 | dec8_swedish_ci | DEC West European | 1 |
| cp850 | cp850_general_ci | DOS West European | 1 |
| hp8 | hp8_english_ci | HP West European | 1 |
......
可以使用 SHOW COLLATION LIKE '***';命令来查看相关字符集的校对规则。
mysql> SHOW COLLATION LIKE 'gbk%';
+----------------+---------+----+---------+----------+---------+
| Collation | Charset | Id | Default | Compiled | Sortlen |
+----------------+---------+----+---------+----------+---------+
| gbk_chinese_ci | gbk | 28 | Yes | Yes | 1 |
| gbk_bin | gbk | 87 | | Yes | 1 |
+----------------+---------+----+---------+----------+---------+
2 rows in set (0.00 sec)
上面运行结果为 GBK 字符集所对应的校对规则,其中 gbk_chinese_ci 是默认的校对规则,对大小写不敏感。而 gbk_bin 按照二进制编码的值进行比较,对大小写敏感。
也可以通过查询 information_schema.COLLATIONS 表中的记录,来查看 MySQL 中可用的校对规则。SQL 语句和执行过程如下:
mysql> SELECT * FROM information_schema.COLLATIONS;
+--------------------------+--------------------+-----+------------+-------------+---------+
| COLLATION_NAME | CHARACTER_SET_NAME | ID | IS_DEFAULT | IS_COMPILED | SORTLEN |
+--------------------------+--------------------+-----+------------+-------------+---------+
| big5_chinese_ci | big5 | 1 | Yes | Yes | 1 |
| big5_bin | big5 | 84 | | Yes | 1 |
| dec8_swedish_ci | dec8 | 3 | Yes | Yes | 1 |
| dec8_bin | dec8 | 69 | | Yes | 1 |
| cp850_general_ci | cp850 | 4 | Yes | Yes | 1 |
| cp850_bin | cp850 | 80 | | Yes | 1 |
......
在实际应用中,我们应事先确认应用需要按照什么样方式排序,是否区分大小写,然后选择相应的校对规则。
MySQL设置默认字符集和校对规则
MySQL 服务器可以支持多种字符集,在同一台服务器、同一个数据库甚至同一个表的不同字段中,都可以使用不同的字符集。Oracle 等其它数据库管理系统都只能使用相同的字符集,相比之下,MySQL 明显存在更大的灵活性。
MySQL 的字符集和校对规则有 4 个级别的默认设置,即服务器级、数据库级、表级和字段级。它们分别在不同的地方设置,作用也不相同。
服务器字符集和校对规则
修改服务器默认字符集和校对规则的方法如下。
可以在 my.ini 配置文件中设置服务器字符集和校对规则,添加内容如下:
[mysqld]
character-set-server=字符集名称
连接 MySQL 服务器时指定字符集:
mysql --default-character-set=字符集名称 -h 主机IP地址 -u 用户名 -p 密码
如果没有指定服务器字符集,MySQL 会默认使用 latin1 作为服务器字符集。如果只指定了字符集,没有指定校对规则,MySQL 会使用该字符集对应的默认校对规则。如果要使用字符集的非默认校对规则,需要在指定字符集的同时指定校对规则。
可以用 SHOW VARIABLES LIKE 'character_set_server' 和 SHOW VARIABLES LIKE 'collation_server' 命令查询当前服务器的字符集和校对规则。
mysql> SHOW VARIABLES LIKE 'character_set_server';
+----------------------+--------+
| Variable_name | Value |
+----------------------+--------+
| character_set_server | gbk |
+----------------------+--------+
1 row in set, 1 warning (0.01 sec)
mysql> SHOW VARIABLES LIKE 'collation_server';
+------------------+-------------------+
| Variable_name | Value |
+------------------+-------------------+
| collation_server | gbk_chinese_ci |
+------------------+-------------------+
1 row in set, 1 warning (0.01 sec)
数据库字符集和校对规则
数据库的字符集和校对规则在创建数据库时指定,也可以在创建完数据库后通过 ALTER DATABASE 命令进行修改
需要注意的是,如果数据库里已经存在数据,修改字符集后,已有的数据不会按照新的字符集重新存放,所以不能通过修改数据库的字符集来修改数据的内容。
设置数据库字符集的规则如下:
- 如果指定了字符集和校对规则,则使用指定的字符集和校对规则;
- 如果指定了字符集没有指定校对规则,则使用指定字符集的默认校对规则;
- 如果指定了校对规则但未指定字符集,则字符集使用与该校对规则关联的字符集;
- 如果没有指定字符集和校对规则,则使用服务器字符集和校对规则作为数据库的字符集和校对规则。
为了避免受到默认值的影响,推荐在创建数据库时指定字符集和校对规则。
可以使用 SHOW VARIABLES LIKE 'character_set_database' 和 SHOW VARIABLES LIKE 'collation_database' 命令查看当前数据库的字符集和校对规则。
mysql> SHOW VARIABLES LIKE 'character_set_database';
+------------------------+--------+
| Variable_name | Value |
+------------------------+--------+
| character_set_database | latin1 |
+------------------------+--------+
1 row in set, 1 warning (0.00 sec)
mysql> SHOW VARIABLES LIKE 'collation_database';
+--------------------+-------------------+
| Variable_name | Value |
+--------------------+-------------------+
| collation_database | latin1_swedish_ci |
+--------------------+-------------------+
1 row in set, 1 warning (0.00 sec)
表字符集和校对规则
表的字符集和校对规则在创建表的时候指定,也可以在创建完表后通过 ALTER TABLE 命令进行修改。
同样,如果表中已有记录,修改字符集后,原有的记录不会按照新的字符集重新存放。表的字段仍然使用原来的字符集。
设置表的字符集规则和设置数据库字符集的规则基本类似:
- 如果指定了字符集和校对规则,使用指定的字符集和校对规则;
- 如果指定了字符集没有指定校对规则,使用指定字符集的默认校对规则;
- 如果指定了校对规则但未指定字符集,则字符集使用与该校对规则关联的字符集;
- 如果没有指定字符集和校对规则,使用数据库字符集和校对规则作为表的字符集和校对规则。
为了避免受到默认值的影响,推荐在创建表的时候指定字符集和校对规则。
可以使用 SHOW CREATE TABLE 命令查看当前表的字符集和校对规则,SQL 语句和运行结果如下:
mysql> SHOW CREATE TABLE tb_students_info \G
*************************** 1. row ***************************
Table: tb_students_info
Create Table: CREATE TABLE `tb_students_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`sex` char(1) DEFAULT NULL,
`height` float DEFAULT NULL,
`course_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
列字符集和校对规则
MySQL 可以定义列级别的字符集和校对规则,主要是针对相同表的不同字段需要使用不同字符集的情况。一般遇到这种情况的几率比较小,这只是 MySQL 提供给我们一个灵活设置的手段。
列字符集和校对规则的定义可以在创建表时指定,或者在修改表时调整。语法格式如下:
ALTER TABLE 表名 MODIFY 列名 数据类型 CHARACTER SET 字符集名;
如果在创建列的时候没有特别指定字符集和校对规则,默认使用表的字符集和校对规则。
连接字符集和校对规则
上面所讲的 4 种设置方式,确定的都是数据保存的字符集和校对规则。实际应用中,还需要设置客户端和服务器之间交互的字符集和校对规则。
对于客户端和服务器的交互操作,MySQL 提供了 3 个不同的参数:character_set_client、character_set_connection 和 character_set_results,分别代表客户端、连接和返回结果的字符集。通常情况下,这 3 个字符集是相同的,这样可以确保正确读出用户写入的数据,尤其是中文字符。字符集不同时,容易导致写入的记录不能正确读出。
设置客户端和服务器连接的字符集和校对规则有以下几种方法:
- 在 my.ini 配置文件中,设置以下语句:
[mysql]
default-character-set=gbk
这样服务器启动后,所有连接默认使用 GBK 字符集进行连接。
- 可以通过以下命令来设置连接的字符集和校对规则,这个命令可以同时修改以上 3 个参数(character_set_client、character_set_connection 和 character_set_results)的值。
SET NAMES gbk;
使用这个方法可以“临时一次性地”修改客户端和服务器连接时的字符集为 gbk。
- MySQL 还提供了下列 MySQL 命令“临时地”修改 MySQL“当前会话的”字符集和校对规则。
set character_set_client = gbk;
set character_set_connection = gbk;
set character_set_database = gbk;
set character_set_results = gbk;
set character_set_server = gbk;
set collation_connection = gbk_chinese_ci;
set collation_database = gbk_chinese_ci;
set collation_server = gbk_chinese_ci;
MySQL字符集的选择
由于数据库中存储的数据大部分都是各种文字,所以字符集对数据库的存储、处理性能,以及日后系统的移植、推广都会有影响。对数据库来说,字符集非常重要。不论是在 MySQL 数据库还是其它数据库,都存在字符集的选择问题。
如果在创建数据库时没有正确选择字符集,在后期就可能需要更换字符集,而更换字符集是代价比较高的操作,也存在一定的风险。所以推荐在应用开始阶段,就按照实际需求,正确的选择合适的字符集,避免后期不必要的调整。
目前 MySQL 5.7 支持几十种字符集,包括 UCS-2、UTF-16、UTF-16LE、UTF-32、 UTF-8 和 utf8mb4 等 Unicode 字符集。
那么面对众多的字符集,我们该如何选择呢?
在选择数据库字符集时,可以根据应用的需求,结合字符集的特点来权衡,主要考虑以下几方面的因素。
- 满足应用支持语言的需求。如果应用要处理各种各样的文字,或者将发布到使用不同语言的国家或地区,就应该选择 Unicode 字符集。对 MySQL 来说,目前就是 UTF-8。
- 如果应用中涉及已有数据的导入,就要充分考虑数据库字符集对已有数据的兼容性。假如已有数据的字符集是 GBK,如果选择 GB 2312-80 为数据库字符集,就很可能出现某些文字无法正确导入。
- 如果数据库只需要支持一般中文,数据量很大,性能要求也很高,那就应该选择双字节定长编码的中文字符集,比如 GBK。
- 因为,相对于 UTF-8 而言,GBK 比较“小”,每个汉字只占 2 个字节,而 UTF-8 汉字编码需要 3 个字节,这样可以减少磁盘 I/O、数据库 Cache 以及网络传输的时间,从而提高性能。相反,如果应用主要处理英文字符,仅有少量汉字数据,那么选择 UTF-8 更好,因为 GBK、UCS-2、UTF-16 的西文字符编码都是 2 个字节,会造成很多不必要的开销。
- 如果数据库需要做大量的字符运算,如比较、排序等,那么选择定长字符集可能更好,因为定长字符集的处理速度要比变长字符集的处理速度快。
- 如果所有客户端程序都支持相同的字符集,则应该优先选择该字符集作为数据库字符集。这样可以避免因字符集转换带来的性能开销和数据损失。
- 在多种字符集都能够满足应用的前提下,应尽量使用小的字符集。因为更小的字符集意味着能够节省空间、减少网络传输字节数,同时由于存储空间的较小间接的提高了系统的性能。
注意:有很多字符集都可以保存汉字,比如 UTF-8、GB2312、GBK、Latin1 等等。但是常用的是 GB2312 和 GBK。因为 GB2312 字库比 GBK 字库小,有些偏僻字(例如:洺)不能保存,因此在选择字符集的时候一定要权衡这些偏僻字出现的几率,一般情况下,最好选用 GBK。
2020重新出发,MySql基础,MySql字符集的更多相关文章
- Mysql基础之字符集与乱码
原文:Mysql基础之字符集与乱码 Mysql的字符集设置非常灵活 可以设置服务器默认字符集 数据库默认字符集 表默认字符集 列字符集 如果某一个级别没有指定字符集,则继承上一级. 以表声明utf8为 ...
- MySQL基础 - mysql命令行客户端
在Linux系统当中,mysql作为一个客户端命令程序,在很大程度上连接数据库都是使用mysql,因此很有必要熟悉mysql命令行的使用. 这里假设数据库用户为icebug,密码为icebug_pas ...
- MySQL基础、索引、查询优化等考察点
MySQL基础 MySQL数据类型 整数类型 TINYINT. SMALLINT. MEDIUMINT. INT. BIGINT 属性:UNSIGNED 长度:可以为整数类型指定宽度,例如:INT(1 ...
- 2020重新出发,MySql基础,MySql视图&索引&存储过程&触发器
@ 目录 视图是什么 视图的优点 1) 定制用户数据,聚焦特定的数据 2) 简化数据操作 3) 提高数据的安全性 4) 共享所需数据 5) 更改数据格式 6) 重用 SQL 语句 MySQL创建视图 ...
- 2020重新出发,MySql基础,性能优化
@ 目录 MySQL性能优化 MySQL性能优化简述 使用 SHOW STATUS 命令 使用慢查询日志 MySQL 查询分析器 EXPLAIN DESCRIBE 索引对查询速度的影响 MySQL优化 ...
- (3.16)mysql基础深入——mysql字符集
(3.16)mysql基础深入——mysql字符集 关键字:mysql字符集,mysql编码 目录 1.概念 2.常用的字符编码 3.查看mysql字符集 [3.1]查看服务器支持的字符集 [3.2] ...
- 2020年数据库概念与MySQL的安装与配置-从零基础入门MySQL-mysql8版本
作者 | Jeskson 来源 | 达达前端小酒馆 从零基础入门MySQL数据库基础课 数据的概念,简介,安装与配置,Windows平台下MySQL的安装与配置. 数据库的概念:数据库是一个用来存放数 ...
- Mysql基础代码(不断完善中)
Mysql基础代码,不断完善中~ /* 启动MySQL */ net start mysql /* 连接与断开服务器 */ mysql -h 地址 -P 端口 -u 用户名 -p 密码 /* 跳过权限 ...
- MYSQL基础操作
MYSQL基础操作 [TOC] 1.基本定义 1.1.关系型数据库系统 关系型数据库系统是建立在关系模型上的数据库系统 什么是关系模型呢? 1.数据结构可以规定,同类数据结构一致,就是一个二维的表格 ...
随机推荐
- loj #6039 「雅礼集训 2017 Day5」珠宝 分组背包 决策单调性优化
LINK:珠宝 去年在某个oj上写过这道题 当时懵懂无知wa的不省人事 终于发现这个东西原来是有决策单调性的. 可以发现是一个01背包 但是过不了 冷静分析 01背包的复杂度有下界 如果过不了说明必然 ...
- Vuex详细教程
1.认识Vuex 1.1Vuex是做什么的 官方解释:Vuex 是一个专为 Vue.js 应用程序开发的状态管理模式.它采用 集中式存储管理 应用的所有组件的状态,并以相应的规则保证状态以一种可预测的 ...
- Core下简易WebApi
代码很粗糙~ 粘贴github地址 https://github.com/htrlq/MiniAspNetCoreMini demo public class Startup { public Sta ...
- Linux本地套接字(Unix域套接字)----SOCK_DGRAM方式
目录 简述 创建服务端代码: 创建客户端代码 接收函数封装 发送封装 服务端测试main函数 客户端测试main函数 编译运行结果 简述 这里介绍一下Linux进程间通信的socket方式---Loc ...
- GPS坐标显示在百度地图上(Qt+百度地图)
Qt在5.6以后的版本就不支持webview控件了,这里我用的是Qt5.4的版本,里面还有这个控件: 下面简单介绍下Qt与html中的javascript调用交互过程: 一.整体实现介绍 在html中 ...
- .net+uniapp 前后端数据交互相关问题记录
uniapp 提交form表单 @submit EventHandle 携带 form 中的数据触发 submit 事件,event.detail = {value : {'name': 'value ...
- JVM与Java体系结构
参考笔记:https://blog.csdn.net/weixin_45759791/article/details/107322503 前言 作为Java工程师的你曾被伤害过吗?你是否也遇到过这些问 ...
- 常哥带你认识NoSQL和Redis的强大
各位朋友,这篇文章是针对Redis快速了解的内容,为了学好Redis在这里首先跟大家聊聊NoSQL相关内容,有了概念和方向后,我们再学习Redis大家会感觉得心应手. [公众号dotNet工控上位机: ...
- windows系统下python setup.py install ---出现cl问题,cpp_extension.py:237: UserWarning: Error checking compiler version for cl: 'utf-8' codec can't decode byte 0xd3 in position 0: invalid continuation byte
将cpp_extension.py文件中的 原始的是 compiler_info.decode() try: if sys.platform.startswith('linux'): minimu ...
- 洛谷P1149.火柴棒等式(暴力搜索)
题目描述 给你n根火柴棍,你可以拼出多少个形如"A+B=C"的等式?等式中的A.B.C是用火柴棍拼出的整数(若该数非零,则最高位不能是0).用火柴棍拼数字0-9的拼法如图所示: 注 ...