Databricks 第7篇:管理Secret
有时,访问数据要求您通过JDBC对外部数据源进行身份验证,可以使用Azure Databricks Secret来存储凭据,并在notebook和job中引用它们,而不是直接在notebook中输入凭据。
要配置一个Secret,需要分三步:
- 创建secret scope,scope name是大小写敏感的。
- 把secret添加到secret scope中,secret name是大小写敏感的。
- 把权限授予secret scope。
一,Secret Scope简介
Secret Scope是Secret的集合,每一个Secret是由name唯一确定的。每一个Databricks 的workspace最多创建100个Secret Scope。Azure 支持两种类型的Secret Scope:Azure Key Vault-backed 和 Databricks-backed。
1,基于Azure Key Vault的Secret Scope
要引用存储在Azure Key Vault中的Secret,可以创建基于Azure Key Vault的Secret Scope,基于Azure Key Valut的Secret Scope对于Key Valut来说是只读的。 本文重点介绍基于Azure Key Valut的Secret Scope。
2,基于Databricks的Secret Scope
基于Databricks的Secret Scope存储在由Azure Databricks拥有和管理的加密数据库中,Secret Scope的name在工作空间中必须唯一,必须包含字母数字字符,破折号,下划线和句点,并且不得超过128个字符。名称被认为是不敏感的,并且工作空间中的所有用户都可以读取。
二,创建基于Azure Key Vault的Secret Scope
使用 Azure Portal UI创建Azure Key Vault-backed 的 secret scope。首先,在创建该类型的Secret Scope之前,确保对Azure Key Valut实例具有Contributor权限。
打开网页“https://<databricks-instance>#secrets/createScope”,这个URL是大小写敏感的,注意URL中的“createScope”,其中的“Scope”首字母必须是大写的。
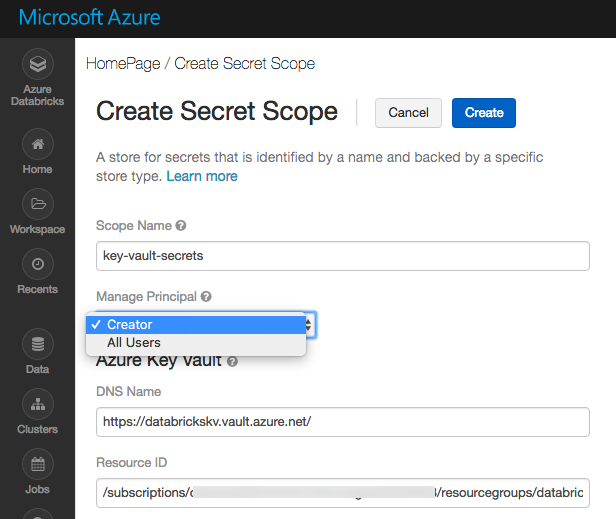
主要的配置选项:
- Scope Name:指定Secret Scope的name,该名称是大小写敏感的。
- Manage Principal:用于定义该Secret Scope的Manage Principal(拥有管理权限的安全主体),选项All Users表示所有的用户都有MANAGE权限,选项Creator表示只有Secret Scope的创建者拥有MANAGE权限。MANAGE权限拥有对Secret Scope的读写权限,推荐选项是Creator,把MANAGE权限只授权给Creator。但是,用户的账户必须具有Azure Databricks Premium Plan ,才可以选择Creator。
- DNS Name:是Valut URI,从Key Valut的Properties面板中可以查看到。
- Resource ID:从Azure Key Valut的属性面板中可以查看到Resource ID。
三,个人访问Token
如果要访问Databricks REST API,可以使用Databricks personal access tokens来进行权限验证。
点击Databricks 工作区右上角的user profile icon

点击“User Settings”,进入到“User Settings”页面,在该页面中点击“Generage New Token”生成新的Token。

注意:要把Token保存起来,再次进入该页面,Token不再可见。
四:配置Databricks CLI
使用Databricks CLI 命令来验证Secret Scope是否创建成功。
Step1:安装Databricks CLI
pip install databricks-cli
Step2:配置验证信息
输入Databricks Host,并输入生成的个人访问Token
databricks configure --token
Step3:查看Secret Scope列表
databricks secrets list-scopes
参考稳定:
Authentication using Azure Databricks personal access tokens
Databricks 第7篇:管理Secret的更多相关文章
- Databricks 第8篇:把Azure Data Lake Storage Gen2 (ADLS Gen 2)挂载到DBFS
DBFS使用dbutils实现存储服务的装载(mount.挂载),用户可以把Azure Data Lake Storage Gen2和Azure Blob Storage 账户装载到DBFS中.mou ...
- WPF 精修篇 管理资源字典
原文:WPF 精修篇 管理资源字典 样式太多 每个界面可能需要全局的样式 有没有肯能 WPF 中的样式 像Asp.net中 的CSS一样管理那 有的 有资源字典 BurshDictionary &l ...
- Databricks 第10篇:Job
Job是立即运行或按计划运行notebook或JAR的一种方法,运行notebook的另一种方法是在Notebook UI中以交互方式运行. 一,使用UI来创建Job 点击"Jobs&quo ...
- Databricks 第5篇:Databricks文件系统(DBFS)
Databricks 文件系统 (DBFS,Databricks File System) 是一个装载到 Azure Databricks 工作区的分布式文件系统,可以在 Azure Databric ...
- Databricks 第6篇:Spark SQL 维护数据库和表
Spark SQL 表的命名方式是db_name.table_name,只有数据库名称和数据表名称.如果没有指定db_name而直接引用table_name,实际上是引用default 数据库下的表. ...
- Databricks 第9篇:Spark SQL 基础(数据类型、NULL语义)
Spark SQL 支持多种数据类型,并兼容Python.Scala等语言的数据类型. 一,Spark SQL支持的数据类型 整数系列: BYTE, TINYINT:表示1B的有符号整数 SHORT, ...
- Databricks 第11篇:Spark SQL 查询(行转列、列转行、Lateral View、排序)
本文分享在Azure Databricks中如何实现行转列和列转行. 一,行转列 在分组中,把每个分组中的某一列的数据连接在一起: collect_list:把一个分组中的列合成为数组,数据不去重,格 ...
- MySQL-第十二篇管理结果集
1.ResultSet 2.可更新的结果集,使用ResultSet的updateRow()方法.
- Databricks 第四篇:分组统计和窗口
对数据分析时,通常需要对数据进行分组,并对每个分组进行聚合运算.在一定意义上,窗口也是一种分组统计的方法. 分组数据 DataFrame.groupBy()返回的是GroupedData类,可以对分组 ...
随机推荐
- 【涂鸦物联网足迹】用煲仔饭来说明IaaS/PaaS/SaaS的区别
最近在准备一些科普性的知识内容,发现大家对于一些基础性的知识概念还是有点模糊.今天先来简单介绍一下IaaS/PaaS/SaaS的区别~ 其实还有一个On-Premises(本地部署)的概念,也可以一并 ...
- css 10-CSS3选择器详解
10-CSS3选择器详解 #CSS3介绍 CSS3在CSS2基础上,增强或新增了许多特性, 弥补了CSS2的众多不足之处,使得Web开发变得更为高效和便捷. #CSS3的现状 浏览器支持程度不够好,有 ...
- global和nonlocal之间的区别
在局部修全局的:global 在局部修改嵌套的:nonlocal nonlocal代码示范 # 在局部作用域内去修改嵌套作用域内的变量# 当我们在局部作用域内要修改嵌套作用域内的变量时,需要使用non ...
- angular8 大地老师学习笔记
第一课: angular 创建项目命令: ng new 项目名称 创建组件: ng g 可查看所有创建的对象 ,ng g component components/home 创建组件,后面跟的是 ...
- (五)vimscript打印信息
1.打印信息 使用vimscript时,打印信息的命令是echo和echom,可以通过help echo及help echom命令查看帮助文档,而echo与echom有些许的区别, :echom &q ...
- CentOS7服务器JDK8安装实战
简介:演练JDK8环境的安装 下载jdk官网: https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133 ...
- 一步步教你:如何用Qemu来模拟ARM系统
这是道哥的第011篇原创 目录 前言 为什么需要ARM模拟系统 应用程序的开发 系统开发(BSP) Qemu是什么? Qemu的两种模式 Qemu 能做什么?或者说适合做什么? 在 Ubuntu16. ...
- postgresql 创建分表
划分指的是将逻辑上的一个大表分成一些小的物理上的片.划分有很多益处: 1.在某些情况下查询性能能够显著提升,特别是当那些访问压力大的行在一个分区或者少数几个分区时.划分可以取代索引的主导列.减小索引尺 ...
- 常用的linux指令
a.cd /home 进入 '/ home' 目录' b.cd .. 返回上一级目录 c.cd ../.. 返回上两级目录 d.mkdir dir1 创建一个叫做 'dir1' 的目录' e.mkdi ...
- Spring Boot 自动配置之@Conditional的使用
Spring Boot自动配置的"魔法"是如何实现的? 转自-https://sylvanassun.github.io/2018/01/08/2018-01-08-spring_ ...