一、使用 BeautifulSoup抓取网页信息信息
一、解析网页信息
from bs4 import BeautifulSoup
with open('C:/Users/michael/Desktop/Plan-for-combating-master/week1/1_2/1_2code_of_video/web/new_index.html','r') as web_data:
Soup = BeautifulSoup(web_data,'lxml')
print(Soup)

二、获取要爬取元素的位置
浏览器右键-》审查元素-》copy-》seletor
"""
body > div.main-content > ul > li:nth-child(1) > div.article-info > h3 > a
body > div.main-content > ul > li:nth-child(1) > div.article-info > p.meta-info > span:nth-child(2)
body > div.main-content > ul > li:nth-child(1) > div.article-info > p.description
body > div.main-content > ul > li:nth-child(1) > div.rate > span
body > div.main-content > ul > li:nth-child(1) > img
"""
images = Soup.select('body > div.main-content > ul > li:nth-child(1) > img')
print(images)

修改成:
images = Soup.select('body > div.main-content > ul > li:nth-of-type(1) > img')
print(images)

这时候能获取到一个
images = Soup.select('body > div.main-content > ul > li > img')
print(images)

获取到了所有图片
titles = Soup.select('body > div.main-content > ul > li > div.article-info > h3 > a')
descs = Soup.select('body > div.main-content > ul > li > div.article-info > p.description')
rates = Soup.select(' body > div.main-content > ul > li > div.rate > span')
cates = Soup.select(' body > div.main-content > ul > li > div.article-info > p.meta-info > span')
print(images,titles,descs,rates,cates,sep='\n-----------\n')

获取到了其他信息
三、获取标签中的文本信息(get_text())及属性(get())
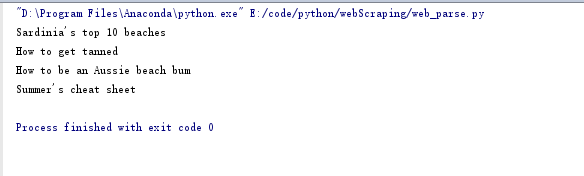
for title in titles:
print(title.get_text())
封装成字典:
for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates):
data = {
'title':title.get_text(),
'rate':rate.get_text(),
'desc':desc.get_text(),
'cate':cate.get_text(),
'image':image.get('src')
}
print(data)

因为cates有多个属性,需要上升到父节点
cates = Soup.select(' body > div.main-content > ul > li > div.article-info > p.meta-info')
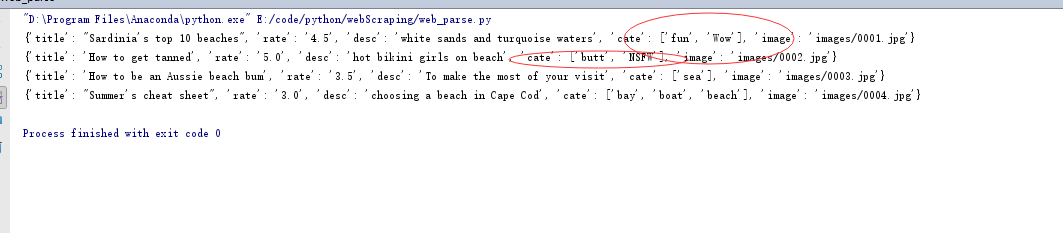
for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates):
data = {
'title':title.get_text(),
'rate':rate.get_text(),
'desc':desc.get_text(),
'cate':list(cate.stripped_strings),
'image':image.get('src')
}
print(data)
#找到评分大于3的文章
for i in info:
if float(i['rate'])>3:
print(i['title'],i['cate'])

四、完整代码
from bs4 import BeautifulSoup
info =[]
with open('C:/Users/michael/Desktop/Plan-for-combating-master/week1/1_2/1_2code_of_video/web/new_index.html','r') as web_data:
Soup = BeautifulSoup(web_data,'lxml')
# print(Soup)
"""
body > div.main-content > ul > li:nth-child(1) > div.article-info > h3 > a
body > div.main-content > ul > li:nth-child(1) > div.article-info > p.meta-info > span:nth-child(2)
body > div.main-content > ul > li:nth-child(1) > div.article-info > p.description
body > div.main-content > ul > li:nth-child(1) > div.rate > span
body > div.main-content > ul > li:nth-child(1) > img
"""
images = Soup.select('body > div.main-content > ul > li > img') titles = Soup.select('body > div.main-content > ul > li > div.article-info > h3 > a')
descs = Soup.select('body > div.main-content > ul > li > div.article-info > p.description')
rates = Soup.select(' body > div.main-content > ul > li > div.rate > span')
cates = Soup.select(' body > div.main-content > ul > li > div.article-info > p.meta-info')
# print(images,titles,descs,rates,cates,sep='\n-----------\n') for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates):
data = {
'title':title.get_text(),
'rate':rate.get_text(),
'desc':desc.get_text(),
'cate':list(cate.stripped_strings),
'image':image.get('src')
}
#添加到列表中
info.append(data)
#找到评分大于3的文章
for i in info:
if float(i['rate'])>3:
print(i['title'],i['cate'])
一、使用 BeautifulSoup抓取网页信息信息的更多相关文章
- Python 抓取网页并提取信息(程序详解)
最近因项目需要用到python处理网页,因此学习相关知识.下面程序使用python抓取网页并提取信息,具体内容如下: #---------------------------------------- ...
- HttpClient+Jsoup 抓取网页信息(网易贵金属为例)
废话不多说直接讲讲今天要做的事. 利用HttpClient和Jsoup技术抓取网页信息.HttpClient是支持HTTP协议的客户端编程工具包,并且它支持HTTP协议. jsoup 是一款基于 Ja ...
- python爬虫抓取哈尔滨天气信息(静态爬虫)
python 爬虫 爬取哈尔滨天气信息 - http://www.weather.com.cn/weather/101050101.shtml 环境: windows7 python3.4(pip i ...
- python写的爬虫工具,抓取行政村的信息并写入到hbase里
python的版本是2.7.10,使用了两个第三方模块bs4和happybase,可以通过pip直接安装. 1.logger利用python自带的logging模块配置了一个简单的日志输出 2.get ...
- Java广度优先爬虫示例(抓取复旦新闻信息)
一.使用的技术 这个爬虫是近半个月前学习爬虫技术的一个小例子,比较简单,怕时间久了会忘,这里简单总结一下.主要用到的外部Jar包有HttpClient4.3.4,HtmlParser2.1,使用的开发 ...
- Python爬虫实战---抓取图书馆借阅信息
Python爬虫实战---抓取图书馆借阅信息 原创作品,引用请表明出处:Python爬虫实战---抓取图书馆借阅信息 前段时间在图书馆借了很多书,借得多了就容易忘记每本书的应还日期,老是担心自己会违约 ...
- 教您使用java爬虫gecco抓取JD全部商品信息
gecco爬虫 如果对gecco还没有了解可以参看一下gecco的github首页.gecco爬虫十分的简单易用,JD全部商品信息的抓取9个类就能搞定. JD网站的分析 要抓取JD网站的全部商品信息, ...
- 使用python抓取美团商家信息
抓取美团商家信息 import requests from bs4 import BeautifulSoup import json url = 'http://bj.meituan.com/' ur ...
- 使用selenium webdriver+beautifulsoup+跳转frame,实现模拟点击网页下一页按钮,抓取网页数据
记录一次快速实现的python爬虫,想要抓取中财网数据引擎的新三板板块下面所有股票的公司档案,网址为http://data.cfi.cn/data_ndkA0A1934A1935A1986A1995. ...
随机推荐
- BUAAOO P13-P14 UML Interaction
- 【BZOJ2795】[Poi2012]A Horrible Poem hash
[BZOJ2795][Poi2012]A Horrible Poem Description 给出一个由小写英文字母组成的字符串S,再给出q个询问,要求回答S某个子串的最短循环节.如果字符串B是字符串 ...
- ffmpeg强制使用TCP方式推流到EasyDarwin开源流媒体服务器进行直播
我们的EasyDarwin目前部署在阿里云的服务器上面,运行的效果是非常好的,而且无论是以TCP方式.还是UDP的方式推送,都可以非常好地进行直播转发: 但并不是所有的用户服务器都是阿里云的形式,有很 ...
- 九度OJ 1134:密码翻译 (翻译)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:1988 解决:810 题目描述: 在情报传递过程中,为了防止情报被截获,往往需要对情报用一定的方式加密,简单的加密算法虽然不足以完全避免情报 ...
- Transforming Auto-encoders
http://www.cs.toronto.edu/~hinton/absps/transauto6.pdf The artificial neural networks that are used ...
- Debug 和 Release 的区别
Debug 和 Release 的区别 Debug 通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序.Release 称为发布版本,它往往是进行了各种优化,使得程 ...
- sample code java pom.xml
pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="htt ...
- Could not find com.android.tools.lint:lint-gradle:26.1.2.
allprojects { repositories { flatDir { dirs 'libs' } jcenter() google() }}
- alsa 编程
ALSA(Advanced Linux Sound Architecture)是由内核驱动,标准的API库和一系列实用程序组成.因为涉及到版权和BUG的问题Linux 2.6内核抛弃了旧的OSS,AL ...
- 2016 Al-Baath University Training Camp Contest-1 I. March Rain —— 二分
题目链接:http://codeforces.com/problemset/gymProblem/101028/I I. March Rain time limit per test 2 second ...