PDM:Training Models of Shape from Sets of Examples
这篇论文介绍了一种创建柔性形状模型(Flexible Shape Models)的方法——点分布模型(Point Distribution Model)。该方法使用一系列标记点来表示形状,重要的是根据所有训练样本计算出平均形状(Average Shape)和平均形状主要的变化模式(Modes of Variation)。其中变化模式描述了形状从平均形状变化到样本形状的主要变化方式,比如长度拉伸、面积变大等。模型只有少量的线性独立的参数,这句话的意思后面会解释。
与柔性形状模型相对应的是刚性模型(Rigid Models),但是刚性模型在很多实际场景中并不合适,因为即使是同一类的目标其形状也不是完全一致的。为此,作者提出了基于训练样本标记点的统计信息建模的点分布模型。为了得到平均形状和主要的变化模式,我们需要将训练样本中的标记点自动对齐。整个模型由平均形状和一些描述变化模式的向量组成。作者以一个例子向大家详细地说明了整个模型的建立过程,如下:
1> 标记训练集(Labelling the Training Set)
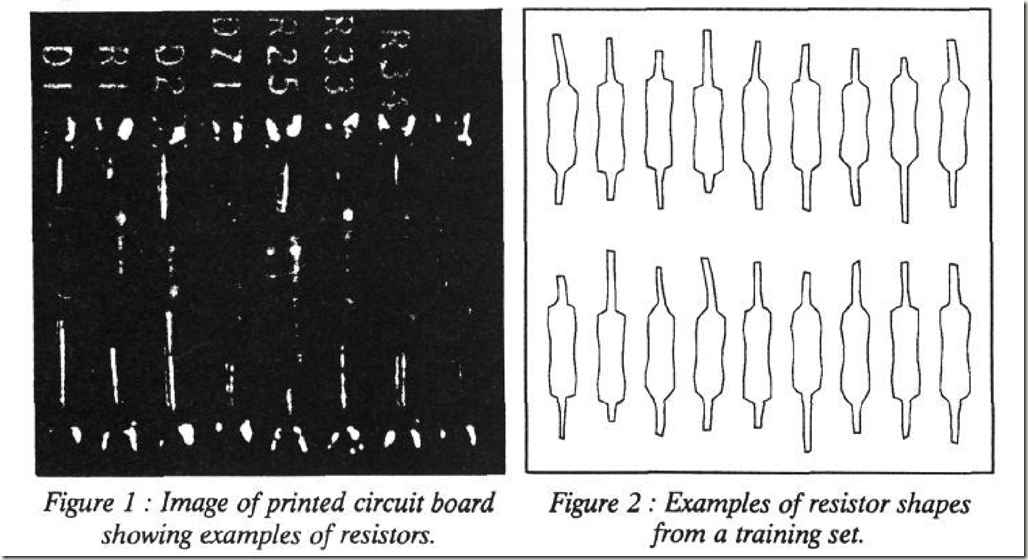
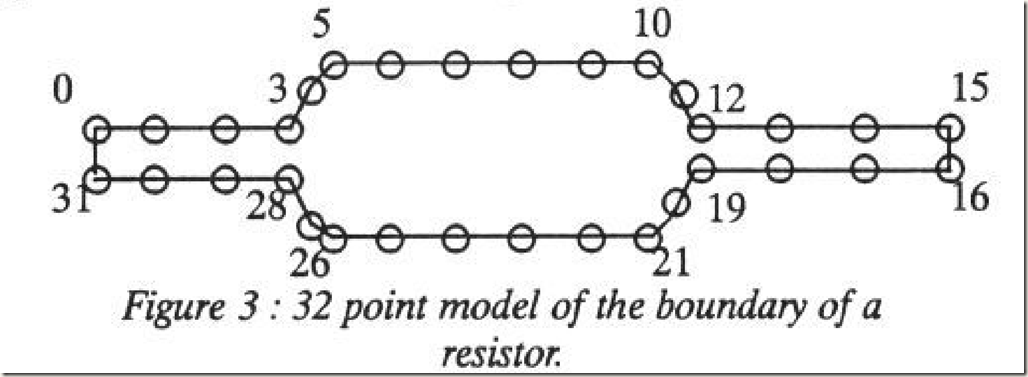
因为模型是用固定数目的标记点表示的,所以必须先对训练集中每一个样本的形状进行标记。这些点的标记非常重要,它们表示了对象的特定部分或边界,如果标记的不准确会导致无法获取形状的变化模式。这些标记点并不是随便选取的,在操作时最好选择那些在不同样本中均能确定的点。作者在论文中以电阻为例展示了形状的标记,如下图:
2> 对齐训练集(Aligning the Training Set)
对齐是很重要的一步,如果不进行对齐操作的话就不能进行比较,后面的统计量也将毫无意义。对齐操作就是对每一个样本进行相似变换,以便让样本之间尽可能的接近,其优化目标是最小化加权距离平方和,这实际上就是广义Procrustes分析(Generalised Procrustes Analysis)。
下面以两个shapes为例说明变换的过程:
将训练集中的第i个样本记为向量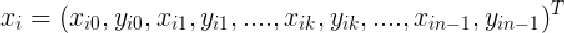 ,该样本经过旋转、尺度缩放以及平移后得到
,该样本经过旋转、尺度缩放以及平移后得到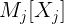 。给定两个相似的形状
。给定两个相似的形状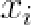 、
、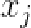 ,旋转参数
,旋转参数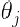 ,尺度缩放参数
,尺度缩放参数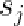 以及平移参数
以及平移参数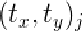 ,那么将
,那么将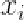 映射到
映射到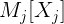 时对应的加权和为:
时对应的加权和为:
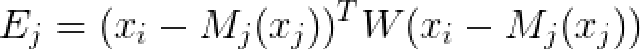 其中
其中
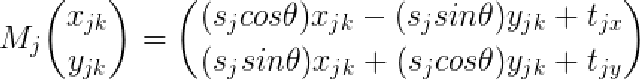
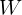 是对角阵,表示每个点的权重。那么如何求解使得
是对角阵,表示每个点的权重。那么如何求解使得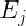 最小的参数呢?
最小的参数呢?
首先,点对应的权重越大表示该点在训练集中相对于其它点越稳定。权重矩阵的定义如下: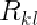 表示一个形状中点k和点l之间的距离;
表示一个形状中点k和点l之间的距离;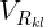 表示训练集中所有shapes中点k和点l之间距离的方差,那么权重矩阵中的第
表示训练集中所有shapes中点k和点l之间距离的方差,那么权重矩阵中的第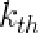 个元素为
个元素为
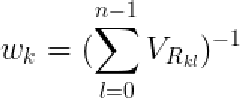
从上式中可以直观地看出如果一个点在训练集样本中相对其它点不稳定,那么其方差就会较大,相应的权重就会较小。反之,权重就会较大。
其次,对于剩下的参数可以使用最小二乘法的代数求解法求解,即目标函数先分别对模型参数求导,然后再置为0得到若干线性方程组,解该方程组就能得到参数的值。如果记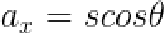 、
、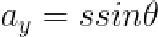 ,那么应用最小二乘法后得到的线性方程组可以表示成如下形式:
,那么应用最小二乘法后得到的线性方程组可以表示成如下形式:
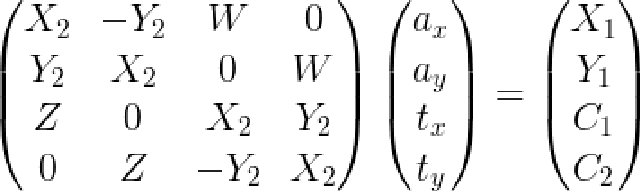 其中
其中
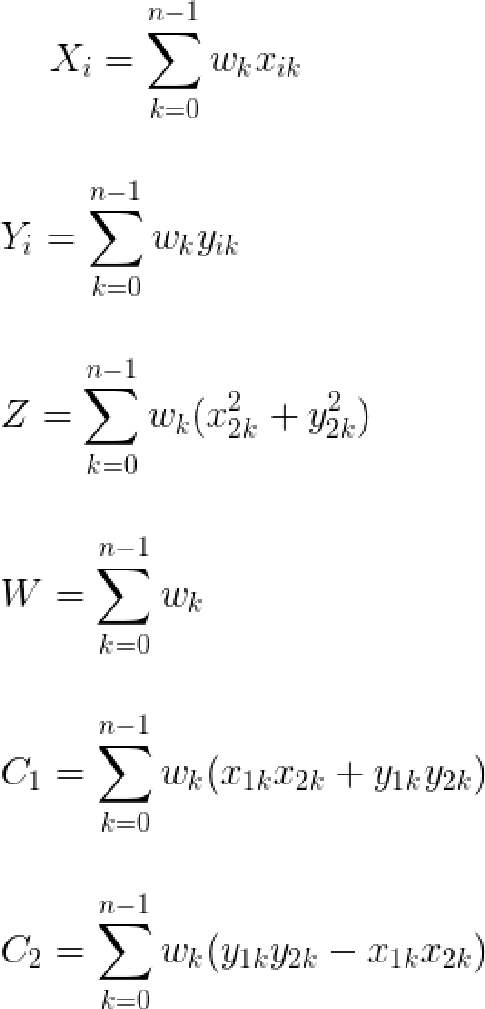 接下来使用标准的矩阵方法就能解出参数值。
接下来使用标准的矩阵方法就能解出参数值。
既然现在权重矩阵和对齐时求解参数的方法已知,那我们就可以在训练集上进行对齐操作了。对齐的算法如下:
1> 选取第一个shape作为参考形状(Refer Shape),将剩下的shape依次与之对齐(相似变换)
重复下列步骤直至收敛:
2> 计算对齐后的平均shape;
3> 二选一
a) 将得到的mean shape调整到预先设置好的尺寸、方向和原点;
b) 经过旋转、缩放、平移操作将mean shape对齐到第一个shape(相当于是指定好的尺寸、方向和原点)
4> 将训练集中的所有shapes与计算出的mean shape对齐;
收敛可以通过计算各shape与mean shape之间的平均距离来判断。实验证明,使用这种判断方式时会收敛到相同的结果,即使在对齐时第一阶段选择的Refer Shape不同。
3> 获取对齐形状的统计信息(Capturing the Statistics of a Set of Aligned Shapes)
通过对齐后的shapes可以获得mean shape和形状变化的模式。平均形状计算如下:
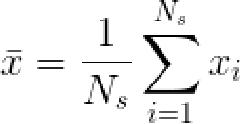
通过对各shape与mean shape之间的偏差应用PCA,我们可以得到形状变化的模式(Models of Variation)。对于每一个形状,可以求得其与平均形状的偏差
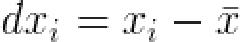
然后我们可以计算出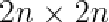 (n是每个shape中的点数)的方差矩阵S,如下
(n是每个shape中的点数)的方差矩阵S,如下
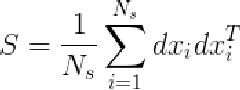 modes of variation就是矩阵S的特征向量
modes of variation就是矩阵S的特征向量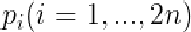
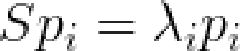
且特征向量经过了归一化
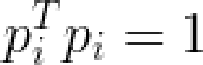
可以发现,特征值越大其所对应的特征向量表示的变化越重要。实际上,绝大多数变化可以通过少数变化模式来解释,也就是说很多变化都是部分变化模式综合作用的结果。那么如何确定这些变化模式的数量呢?通常的做法是选择t个特征值,使得其和占所有特征值之和的比例足够大,这和PCA中确定主成分的方法一致。
至此,训练集中的任何shape均可以通过mean shape和该shape与t个模式的偏差的加权和得到:
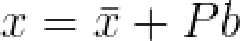
其中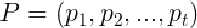 ,是方差矩阵的前t个特征向量;
,是方差矩阵的前t个特征向量;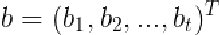 ,是t个特征向量的权重构成的向量。
,是t个特征向量的权重构成的向量。
这些特征向量是正交的,所以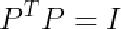 ,那么
,那么
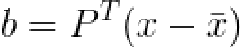
在限定范围内改变向量b中元素的值我们可以得到新的shape。此外b中的元素是线性独立的,也就说彼此对shape的影响相互独立。在论文中作者提到了参数改变的限定范围如何确定:记参数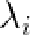 为
为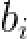 在训练集上的方差,那么合适的限定范围很有可能是
在训练集上的方差,那么合适的限定范围很有可能是
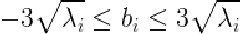
因为绝大多数样本都分布在3倍于均值标准差的范围内。
论文的后面部分作者以实例说明了该方法的有效性,具体内容见论文原文。
4> 总结
在标记Points的时候一定要准确且有代表性,后面会根据与平均形状的偏差计算代表模式变化特征向量;
直观上理解,特征向量对应的是shape中那些变化程度比较大的points,这些变化是柔性形状模型的主要变化模式。
模型的参数向量b用来设置各个主要变化模式添加到平均形状上的量。
PDM:Training Models of Shape from Sets of Examples的更多相关文章
- WPF学习04:2D绘图 使用Shape绘基本图形
我们将使用Shape进行基本图形绘制. 例子 一个可移动的矩形方框: XAML代码: <Window x:Class="Shape.MainWindow" xmlns=&qu ...
- 笔试算法题(38):并查集(Union-Find Sets)
议题:并查集(Union-Find Sets) 分析: 一种树型数据结构,用于处理不相交集合(Disjoint Sets)的合并以及查询:一开始让所有元素独立成树,也就是只有根节点的树:然后根据需要将 ...
- Android项目实战(四十):在线生成按钮Shape的网站
原文:Android项目实战(四十):在线生成按钮Shape的网站 AndroidButton Make 右侧设置按钮的属性,可以即时看到效果,并即时生成对应的.xml 代码,非常高效(当然熟练的话 ...
- 综合练习: PIVOT、UNPIVOT、GROUPING SETS、GROUPING_ID_1
综合练习: PIVOT.UNPIVOT.GROUPING SETS.GROUPING_ID 问题1:Desired output: empid cnt2007 cnt2008 cnt2009 ---- ...
- 壁虎书4 Training Models
Linear Regression The Normal Equation Computational Complexity 线性回归模型与MSE. the normal equation: a cl ...
- 论文笔记之: Recurrent Models of Visual Attention
Recurrent Models of Visual Attention Google DeepMind 模拟人类看东西的方式,我们并非将目光放在整张图像上,尽管有时候会从总体上对目标进行把握,但是也 ...
- 第四章——训练模型(Training Models)
前几章在不知道原理的情况下,已经学会使用了多个机器学习模型机器算法.Scikit-Learn很方便,以至于隐藏了太多的实现细节. 知其然知其所以然是必要的,这有利于快速选择合适的模型.正确的训练算法. ...
- 超越村后端开发(2:新建models.py+xadmin的引入)
1.新建Model 1.users数据 1.在apps/users/models.py中: from datetime import datetime from django.db import mo ...
- 二:Recovery models(恢复模式)
For each database that you create in SQL Server, with the exception of the system databases, you can ...
随机推荐
- 006_设置执行命令提示和unset shell function
一.unset不能unset只读变量 问题: [root@zb1-bdwaimai-inf-wfe-28 ~]# source ~/.bash_profile bash: PROMPT_COMMAND ...
- Linux centos系统安装后的基本配置,Linux命令
一.centos系统安装后的基本配置 .常用软件安装 yum install -y bash-completion vim lrzsz wget expect net-tools nc nmap tr ...
- 清北-Day6-regular
题目描述 给出一个只包含左括号和右括号的字符串,插入若干左右括号(可以插在任意位置)之后使得字符串长度为$ 2\times n $ 且是一个合法的括号序列.求最后能组成多少种不同的合法括号序列. [合 ...
- 用echarts写的multiple-trees demo
echarts-multiple-trees 预览https://zhangzn3.github.io/echarts-multiple-trees/demo.html //根据数据条数自适应区域大小
- 主席树入门——询问区间第k大pos2104,询问区间<=k的元素个数hdu4417
poj2104找了个板子..,但是各种IO还可以进行优化 /* 找区间[l,r]第k大的数 */ #include<iostream> #include<cstring> #i ...
- 简单几步让网站支持https,windows iis下https配置方式
1.https证书的分类 SSL证书没有所谓的"品质"和"等级"之分,只有三种不同的类型.SSL证书需要向国际公认的证书证书认证机构(简称CA,Certific ...
- js-事件以及window操作
属性 当以下情况发生时,出现此事件 onblur 元素失去焦点 onchange 用户改变域的内容 onclick 鼠标点击某个对象 ondblclick 鼠标双击某个对象 onfocus 元素获得焦 ...
- Shell 编程详解
部分引用自:https://blog.csdn.net/qq_22075977/article/details/75209149 一.概述 Shell是一种具备特殊功能的程序,它提供了用户与内核进行交 ...
- 咸鱼入门到放弃2--Servlet
Tomcat作为一款常用的servlet容器,其模型中包含了context容器对servlet行进管理. Servlet程序是由WEB服务器调用,web服务器收到客户端的Servlet访问请求后: ① ...
- 带URL的XML解析方式
XmlDocument xml = new XmlDocument(); xml.LoadXml(responseString); XmlNode root = xml.DocumentElement ...