爬虫简介与request模块
一 爬虫简介
概述
近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的利益,而网络爬虫是其中最为常用的一种从网上爬取数据的手段。
网络爬虫,即Web Spider,是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。

爬虫的价值
互联网中最有价值的便是数据,比如天猫商城的商品信息,链家网的租房信息,雪球网的证券投资信息等等,这些数据都代表了各个行业的真金白银,可以说,谁掌握了行业内的第一手数据,谁就成了整个行业的主宰,如果把整个互联网的数据比喻为一座宝藏,那我们的爬虫课程就是来教大家如何来高效地挖掘这些宝藏,掌握了爬虫技能, 你就成了所有互联网信息公司幕后的老板,换言之,它们都在免费为你提供有价值的数据。
robots.txt协议
如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。robots协议的编写格式可以观察淘宝网的robots(访问www.taobao.com/robots.txt即可)。但是需要注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,所以该协议是防君子不防小人。但是我们在学习爬虫阶段编写的爬虫程序可以先忽略robots协议。
爬虫的基本流程
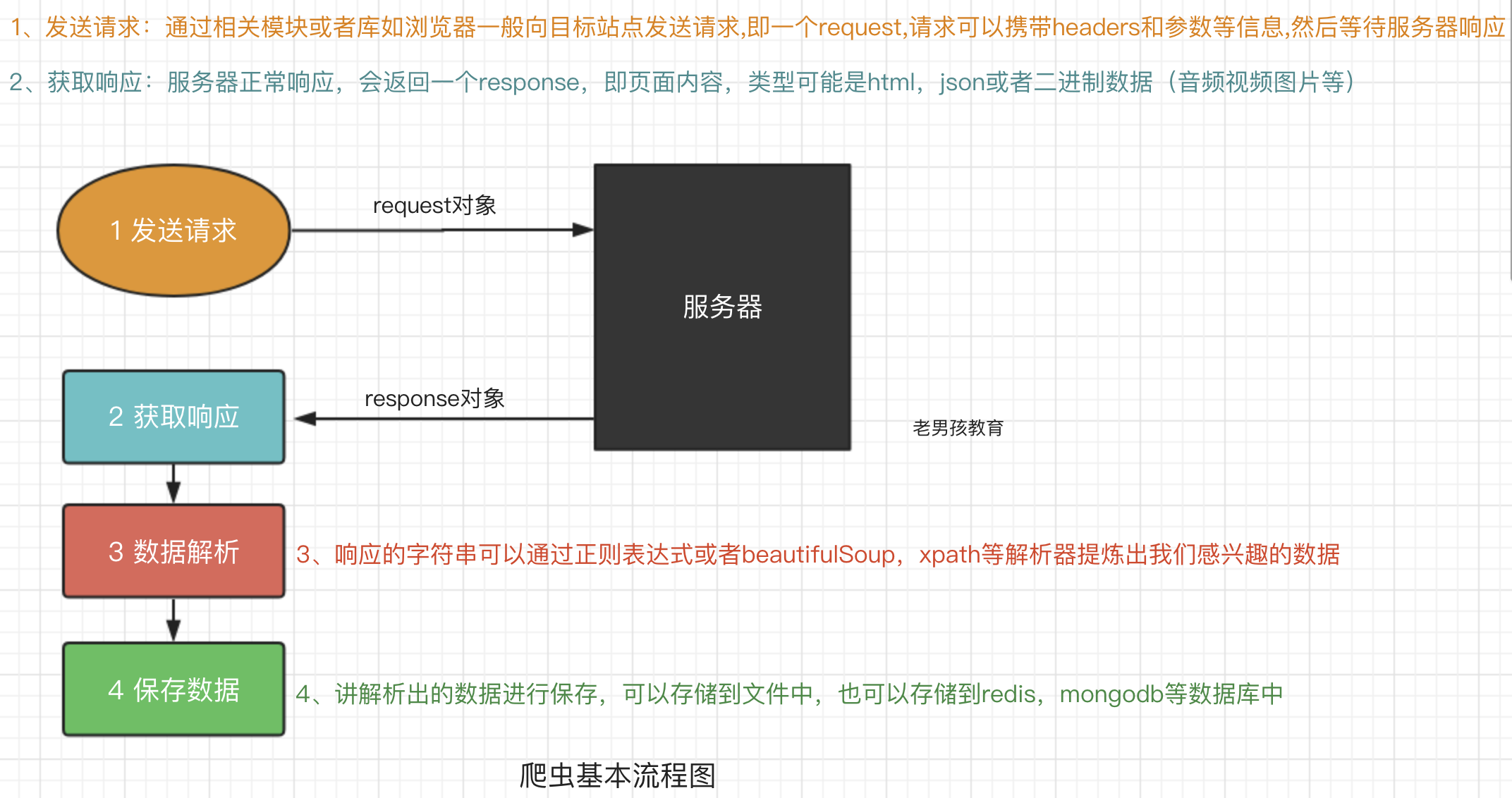
预备知识
http协议
https://www.cnblogs.com/pyedu/p/10287967.html
二 requests模块
requests模块支持的请求
import requests
requests.get("http://httpbin.org/get")
requests.post("http://httpbin.org/post")
requests.put("http://httpbin.org/put")
requests.delete("http://httpbin.org/delete")
requests.head("http://httpbin.org/get")
requests.options("http://httpbin.org/get")
get请求
1 基本请求
import requests
response=requests.get('https://www.jd.com/',)
with open("jd.html","wb") as f:
f.write(response.content)
2 含参数请求
import requests
response=requests.get('https://s.taobao.com/search?q=手机')
response=requests.get('https://s.taobao.com/search',params={"q":"美女"})
3 含请求头请求
import requests
response=requests.get('https://dig.chouti.com/',
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36',
}
)
4 含cookies请求
import uuid
import requests
url = 'http://httpbin.org/cookies'
cookies = dict(sbid=str(uuid.uuid4()))
res = requests.get(url, cookies=cookies)
print(res.text)
post请求
1 data参数
requests.post()用法与requests.get()完全一致,特殊的是requests.post()多了一个data参数,用来存放请求体数据
response=requests.post("http://httpbin.org/post",params={"a":"10"}, data={"name":"yuan"})
2 发送json数据
import requests
res1=requests.post(url='http://httpbin.org/post', data={'name':'yuan'}) #没有指定请求头,#默认的请求头:application/x-www-form-urlencoed
print(res1.json())
res2=requests.post(url='http://httpbin.org/post',json={'age':"22",}) #默认的请求头:application/json
print(res2.json())
response对象
(1) 常见属性
import requests
respone=requests.get('https://sh.lianjia.com/ershoufang/')
# respone属性
print(respone.text)
print(respone.content)
print(respone.status_code)
print(respone.headers)
print(respone.cookies)
print(respone.cookies.get_dict())
print(respone.cookies.items())
print(respone.url)
print(respone.history)
print(respone.encoding)
(2) 编码问题
import requests
response=requests.get('http://www.autohome.com/news')
#response.encoding='gbk' #汽车之家网站返回的页面内容为gb2312编码的,而requests的默认编码为ISO-8859-1,如果不设置成gbk则中文乱码
with open("res.html","w") as f:
f.write(response.text)
(3) 下载二进制文件(图片,视频,音频)
import requests
response=requests.get('http://bangimg1.dahe.cn/forum/201612/10/200447p36yk96im76vatyk.jpg')
with open("res.png","wb") as f:
# f.write(response.content) # 比如下载视频时,如果视频100G,用response.content然后一下子写到文件中是不合理的
for line in response.iter_content():
f.write(line)
(4) 解析json数据
import requests
import json
response=requests.get('http://httpbin.org/get')
res1=json.loads(response.text) #太麻烦
res2=response.json() #直接获取json数据
print(res1==res2)
(5) Redirection and History
默认情况下,除了 HEAD, Requests 会自动处理所有重定向。可以使用响应对象的 history 方法来追踪重定向。Response.history 是一个 Response 对象的列表,为了完成请求而创建了这些对象。这个对象列表按照从最老到最近的请求进行排序。
>>> r = requests.get('http://github.com')
>>> r.url
'https://github.com/'
>>> r.status_code
200
>>> r.history
[<Response [301]>]
另外,还可以通过 allow_redirects 参数禁用重定向处理:
>>> r = requests.get('http://github.com', allow_redirects=False)
>>> r.status_code
301
>>> r.history
[]
requests进阶用法
res=requests.get('http://httpbin.org/ip', proxies={'http':'110.83.40.27:9999'}).json()
print(res)
免费代理:https://www.kuaidaili.com/free/
爬虫简介与request模块的更多相关文章
- 1、爬虫简介与request模块
一 爬虫简介 概述 近年来,随着网络应用的逐渐扩展和深入,如何高效的获取网上数据成为了无数公司和个人的追求,在大数据时代,谁掌握了更多的数据,谁就可以获得更高的利益,而网络爬虫是其中最为常用的一种从网 ...
- 爬虫简介与requests模块
爬虫简介与requests模块 一 爬虫简介 概述 网络爬虫是一种按照一定规则,通过网页的链接地址来寻找网页的,从网站某一个页面(通常是首页)开始,读取网页的内容,找到网页中的其他链接地址,然后通过这 ...
- 爬虫基础(一)-----request模块的使用
---------------------------------------------------摆脱穷人思维 <一> : 建立时间价值的概念,减少做那些"时间花的多收 ...
- 爬虫简介和requests模块
目录 爬虫介绍 requests模块 requests模块 1.requests模块的基本使用 2.get 请求携带参数,调用params参数,其本质上还是调用urlencode 3.携带header ...
- 爬虫之urllib包以及request模块和parse模块
urllib简介 简介 Python3中将python2.7的urllib和urllib2两个包合并成了一个urllib库 Python3中,urllib库包含有四个模块: urllib.reques ...
- nodejs爬虫笔记(一)---request与cheerio等模块的应用
目标:爬取慕课网里面一个教程的视频信息,并将其存入mysql数据库.以http://www.imooc.com/learn/857为例. 一.工具 1.安装nodejs:(操作系统环境:WiN 7 6 ...
- 爬虫与request模块
一.爬虫简介 1.介绍 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁. ...
- 【nodejs】理想论坛帖子下载爬虫1.07 使用request模块后稳定多了
在1.06版本时,访问网页采用的时http.request,但调用次数多以后就问题来了. 寻找别的方案时看到了https://cnodejs.org/topic/53142ef833dbcb076d0 ...
- 爬虫基础之requests模块
1. 爬虫简介 1.1 概述 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本. 1.2 爬虫的价值 在互 ...
随机推荐
- MatrixTree速成
前言 MatrixTree定理是用来解决生成树计数问题的有利工具 比如说这道题 MatrixTree定理的算法流程也非常简单 我们记矩阵\(A\)为无向图的度数矩阵 记矩阵\(D\)为无向图的邻接矩阵 ...
- mysql特殊查询----分组后排序
使用的示例表 学生表----student 表结构 数据 查询方法 一.第一种方法 我认为这是比较传统,比较容易理解的一种方式,使用自连接,并在连接条件中作比较,之后再对查询条件分组统计,排序. se ...
- Dynamics 365 Customer Engagement安装FAQ
微软动态CRM专家罗勇 ,回复310或者20190308可方便获取本文,同时可以在第一间得到我发布的最新博文信息,follow me!我的网站是 www.luoyong.me . 本文参考了包括但不限 ...
- Redis环境搭建和代码测试及与GIS结合的GEO数据类型预研
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1.背景 1.1传统MySQL+ Memcached架构遇到的问题 My ...
- ArcGIS JavaScriptAPI----- 缓冲区操作
描述 使用ArcGIS Server 几何服务(geometry service)来对绘制在地图上的图形生成缓冲区.几何服务能够在基于浏览器的应用程序中执行缓冲操作(buffering),投影要素(p ...
- Thinkphp5整合微信扫码支付开发实例
ThinkPHP框架是比较多人用的,曾经做过的一个Thinkphp5整合微信扫码支付开发实例,分享出来大家一起学习 打开首页生成订单,并显示支付二维码 public function index() ...
- FormData 对象上传二进制文件
使用jQuery 利用 FormData 上传文件:http://harttle.com/2016/07/04/jquery-file-upload.html 通过FormData对象可以组装 ...
- JHipster技术栈定制 - JHipster Registry配置信息加密
本文说明了如何开启和使用JHipster-Registry的加解密功能. 1 整体规划 1.1 名词说明 名词 说明 备注 对称加密 最快速.最简单的一种加密方式,加密(encryption)与解密( ...
- Golang 学习权威网站
Golang 是一个开源的编程语言,它能让构造简单.可靠且高效的软件变得容易. Golang 是从2007年末由Robert Griesemer, Rob Pike, Ken Thompson主持开发 ...
- 取消导航栏navigationBar的半透明/毛玻璃效果
iOS 7.0以上的系统,导航栏默认有毛玻璃效果,遮住了颜色 原因是7.0以上的系统,导航栏默认有毛玻璃效果,遮住了颜色,取消掉这个效果就行了. if( ([[[UIDevice currentDev ...