c语言之单向链表
0x00 什么是链表
链表可以说是一种最为基础的数据结构了,而单向链表更是基础中的基础。链表是由一组元素以特定的顺序组合或链接在一起的,不同元素之间在逻辑上相邻,但是在物理上并不一定相邻。在维护一组数据集合时,就可以使用链表,这一点和数组很相似。但是,链表有着数组所不具有的优势。一方面,链表在执行插入删除操作时拥有更高的效率;另一方面,链表是在堆区动态的开辟存储空间,而大多数的数据在编译时大小并不能确定,因此这种动态开辟空间的特性也可以说是链表的一个优点。
0x01 链表的应用
- 多项式计算
- 滚动列表
- 邮件列表
- 文件的链式分配
- 内存管理
……
0x02 单向链表初见

就像图像所示,单向链表各个元素之间通过一个指针先后链接起来。每个元素包含两个部分,分别是数据域和指针域。前一个元素通过next指针指向后一个元素,链表的开始的元素为链表头,即head指针所指,链表结束的元素为链表尾,尾部元素的next指针指向NULL。可见,单向链表为线性结构。
若想访问链表中的一个元素,我们只能从链表的头部开始,顺着指针指向逐查找。如果从链表头移动到指定的元素,而这时候我们又想访问当前元素之前的某个元素,这时候只能从头在次遍历链表。这相比数组能够通过下标直接访问要麻烦的多,不过我们应该根据不同的应用场景选择数组还是链表,它们只有在对的地方才能发挥出巨大的威力。
0x03 单向链表的操作
0x00 链表结构
typedef struct node//链表元素的结构
{
void *data;//节点中的数据域,设置为无类型指针,数据类型大小由使用者定义
struct node *next;//指向下一节点的指针
}Node;
typedef struct list//链表的结构
{
int size;//链表中节点个数
void (*destroy)(void *data);//由于链表节点中的数据是用户自定义的,故需要调用者提供释放空间的函数
void (*print_data)(const void *data);//同,由用户自定义打印数据的函数
int (*match)(const void *key1, const void *key2);//同,由用户自定义数据的比较方式
Node *head;//记录链表的头部位置
Node *tail;//记录链表的尾部位置
}List;
示意图如下:
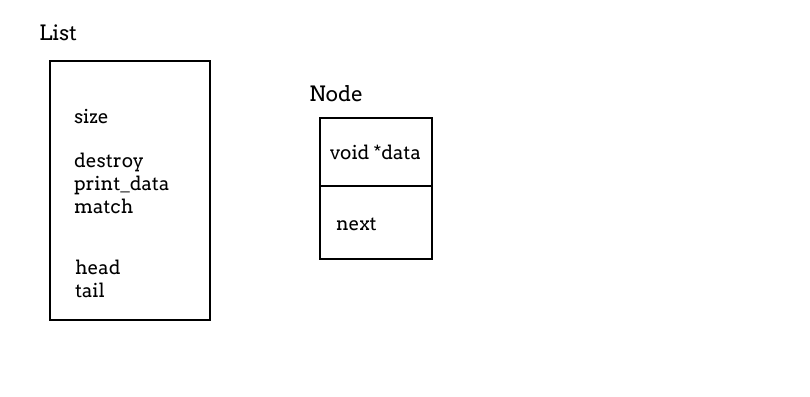
0x01 接口
下面是链表操作函数的接口,以及简单介绍:
extern void list_init(List *list, void (*destroy)(void *data), void (*print_data)(const void *data), \
int (*match)(const void *key1, const void *key2));//初始化一个链表
extern int list_ins_head(List *list, const void *data);//链表的插入,将节点从头部插入
extern int list_ins_tail(List *list, const void *data);//链表的插入,将节点从尾部插入
extern int list_ins_sort(List *list, const void *data);//链表的插入,插入后链表是一个有序的链表
extern void* list_search(List *list, const void *data);//在链表中查找指定数据,若找到返回数据的地址
extern void* list_remove(List *list, const void *data);//在链表中删除指定数据,若找到删除节点并将数据地址返回
extern void list_reverse(List *list);//将链表逆置
extern void list_sort(List *list);//将链表按照一定方式排序
extern void print_list(List *list);//打印链表
extern void list_destroy(List *list);//删除整个链表
#define list_size(list) (list->size) //返回链表节点个数
0x02 list_init
使用list_init函数初始化一个链表,以便链表的其他操作。
void list_init(List *list, void (*destroy)(void *data), void (*print_data)(const void *data), \
int (*match)(const void *key1, const void *key2))
{
list->size = 0;//初始时,链表没有节点,设置为0
list->head = NULL;//头和尾置空
list->tail = NULL;
list->match = match;//初始化链表的成员函数
list->destroy = destroy;
list->print_data = print_data;
return;
}
0x03 list_ins_head
使用list_ins_head函数,在链表的头部插入数据。示意图如下:

从示意图可以看出,单向链表的部插入逻辑非常简单。仔细观察,标绿的部分代码有重复,可以优化
/*在链表的头部插入数据*/
int list_ins_head(List *list, const void *data)
{
Node *new_node = (Node *)calloc(1, sizeof (Node)); //创建插入的节点
if(new_node == NULL)
return -1;
new_node->data = (void *)data;//关联节点与数据
/*
if(list_size(list) == 0)//链表为空时,插入节点
{
list->tail = new_node;
new_node->next = NULL;
list->head = new_node;
}
else //链表非空时将节点插入头部
{
new_node->next = list->head;
list->head = new_node;
}
*/
if(list_size(list) == 0)//链表为空时,插入节点
list->tail = new_node;
new_node->next = list->head;
list->head = new_node;
list->size ++;//维护链表size属性
return 0;
}
0x04 list_ins_tail
使用list_ins_tail函数,在链表的尾部插入数据,示意图如下:
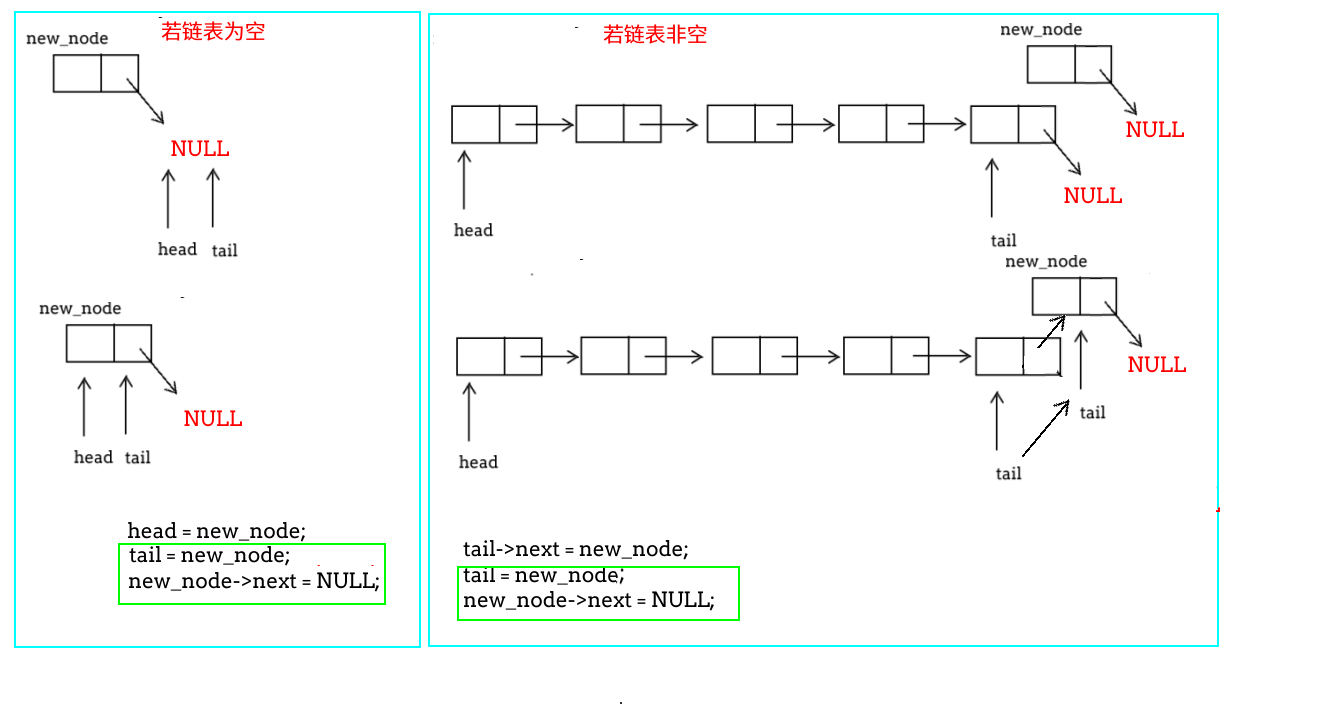
/*在链表的尾部插入数据*/
int list_ins_tail(List *list, const void *data)
{
Node *new_node = (Node *)calloc(1, sizeof (Node)); //创建插入的节点
if(new_node == NULL)
return -1;
new_node->data = (void *)data;//关联节点与数据
if(list_size(list) == 0)
list->head = new_node;
else
list->tail->next = new_node;
list->tail = new_node;
new_node->next = NULL;
list->size ++;
return 0;
}
0x05 list_ins_sort
使用list_ins_sort函数,进行链表的有序插入。
链表的有序插入大致可以分为两种情况:
其一,链表为空时直接插入;
其二,链表非空时,在此时又分为三种小情况;
- 在链表头部插入
- 在链表中部插入
- 在链表尾部插入
链表为空时,操作方法和头尾部插入类似。链表非空时,我们需要先寻找到插入位置,然后在将数据插入链表。
在此之前我们已经了解了如何在链表的头部和尾部插入元素,那么,现在唯一需要处理的便是 在链表中部插入节点 ,这是链表插入操作的核心。
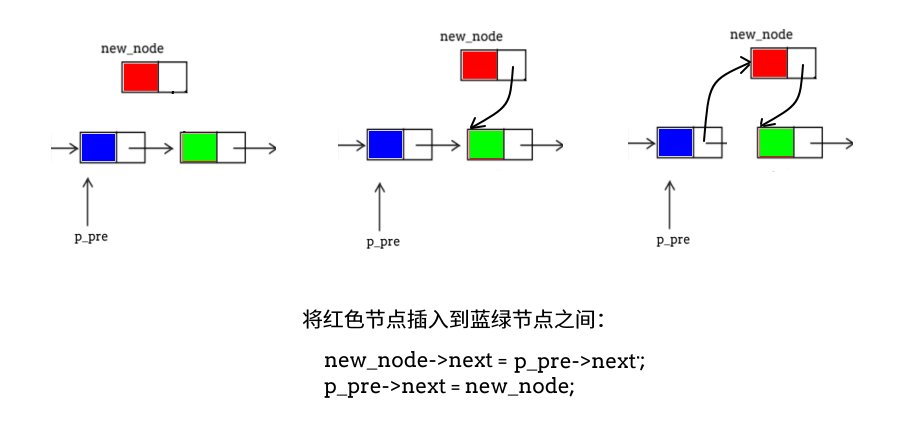
注意:在链表中部插入节点时,必须得到前一节点的位置,即图中指向蓝色节点的指针p_pre.
插入节点的逻辑了解后,处理在非空链表情况下插入节点就清晰多了。
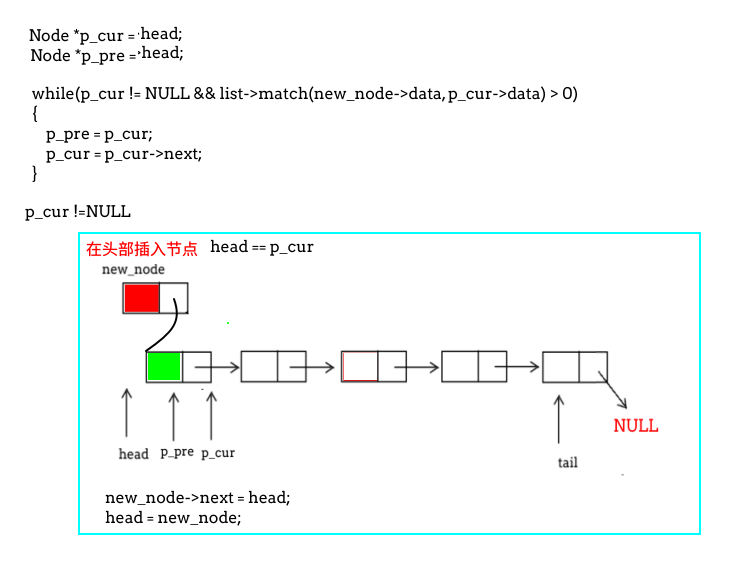
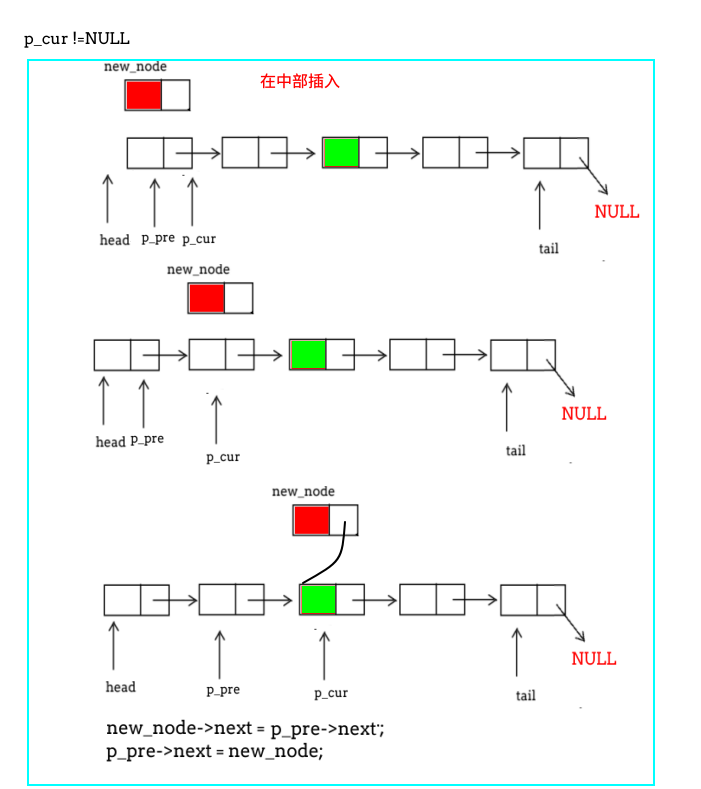

/*在链表的有序插入数据*/
int list_ins_sort(List *list, const void *data)
{
Node *new_node = (Node *)calloc(1, sizeof (Node)); //创建插入的节点
if(new_node == NULL)
return -1;
new_node->data = (void *)data;//关联节点与数据
if(list_size(list) == 0)//链表为空时,插入节点
{
list->tail = new_node;
new_node->next = NULL;
list->head = new_node;
}
else//链表非空
{
Node *p_cur = list->head;
Node *p_pre = list->head;
while(p_cur != NULL && list->match(new_node->data, p_cur->data) > 0)//查找链表的插入位置
{
p_pre = p_cur;
p_cur = p_cur->next;
}
if(p_cur != NULL)//插入位置在头部和中间时
{
if(p_cur == list->head)//插入位置在头部
{
new_node->next = list->head;
list->head = new_node;
}
else//位置在链表中间
{
new_node->next = p_pre->next;
p_pre->next = new_node;
}
}
else//插入位置在链表尾部
{
list->tail->next = new_node;
list->tail = new_node;
new_node = NULL;
}
}
list->size ++;
return 0;
}
0x06 list_search
使用list_search函数,查找链表中与数据匹配的节点,并返回节点指针。
此处查找逻辑与list_ins_sort中的查找逻辑基本类似,不做赘述。
/*查找链表中与数据匹配的节点,并返回节点指针*/
void* list_search(List *list, const void *data)
{
if(list_size(list) == 0)
{
printf("list is empty\n");
return NULL;
}
else
{
Node *p_cur = list->head;
while(p_cur != NULL && list->match(p_cur->data, data) != 0)//查找数据在链表中的位置
p_cur = p_cur->next;
if(p_cur != NULL)//找到返回数据地址,否则返回NULL
return p_cur->data;
else
return NULL;
}
}
0x07 list_remove
使用list_remove函数,删除节点,并将节点中的数据返回,交由用户处理。
此处查找逻辑与list_ins_sort中的查找逻辑基本类似,不做赘述。
和插入节点中分为头部、中部尾部类似,删除也分为头中尾部。
删除头部节点
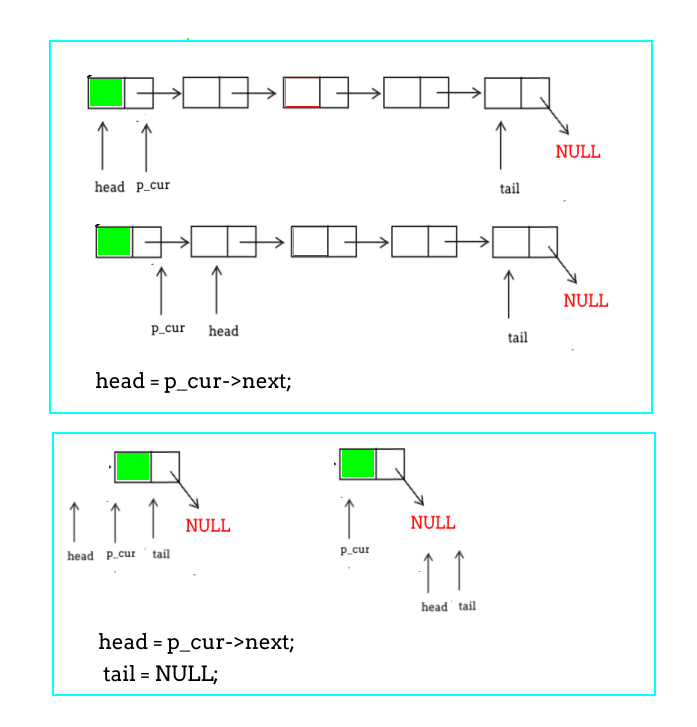
不过删除头部节点时需要注意一点,就是当链表仅有一个节点时,我们需要维护一下tail指针。
删除中部节点
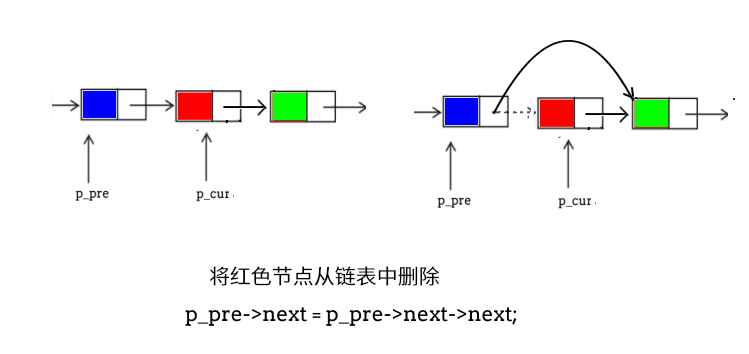
删除尾部节点
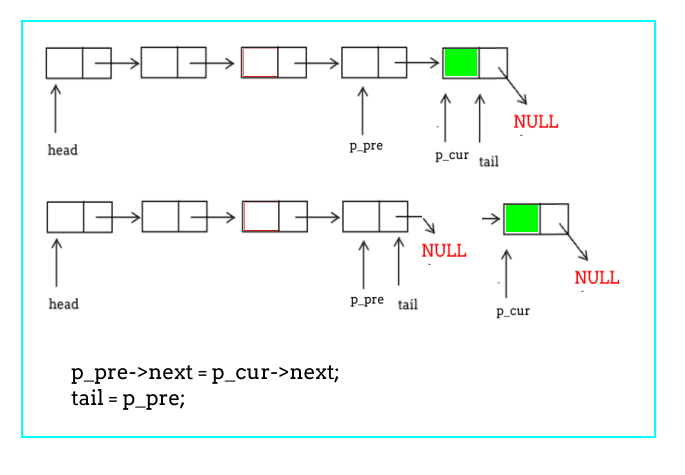
注意:代码中将中部与尾部的删除进行了合并。
/*删除指定数据的节点*/
void* list_remove(List *list, const void *data)
{
void *old_data = NULL;
Node *p_cur = list->head;
Node *p_pre = list->head;
while (p_cur != NULL && list->match(p_cur->data, data) !=0)
{
p_pre = p_cur;
p_cur = p_cur->next;
}
if(p_cur != NULL && list->match(p_cur->data, data) ==0)//删除位置在头部和中间时
{
if(p_cur == list->head)//删除位置在头部
{
list->head = p_cur->next;
if(p_cur->next == NULL)
list->tail = NULL;
}
else//中部时或尾部
{
p_pre->next = p_cur->next;
if(p_cur->next == NULL)//判断是否为尾部
list->tail = p_pre;
}
old_data = p_cur->data;
free(p_cur);
list->size --;
}
return old_data;
}
0x08 list_reverse
使用list_reverse函数将链表逆置。
逆置过程:
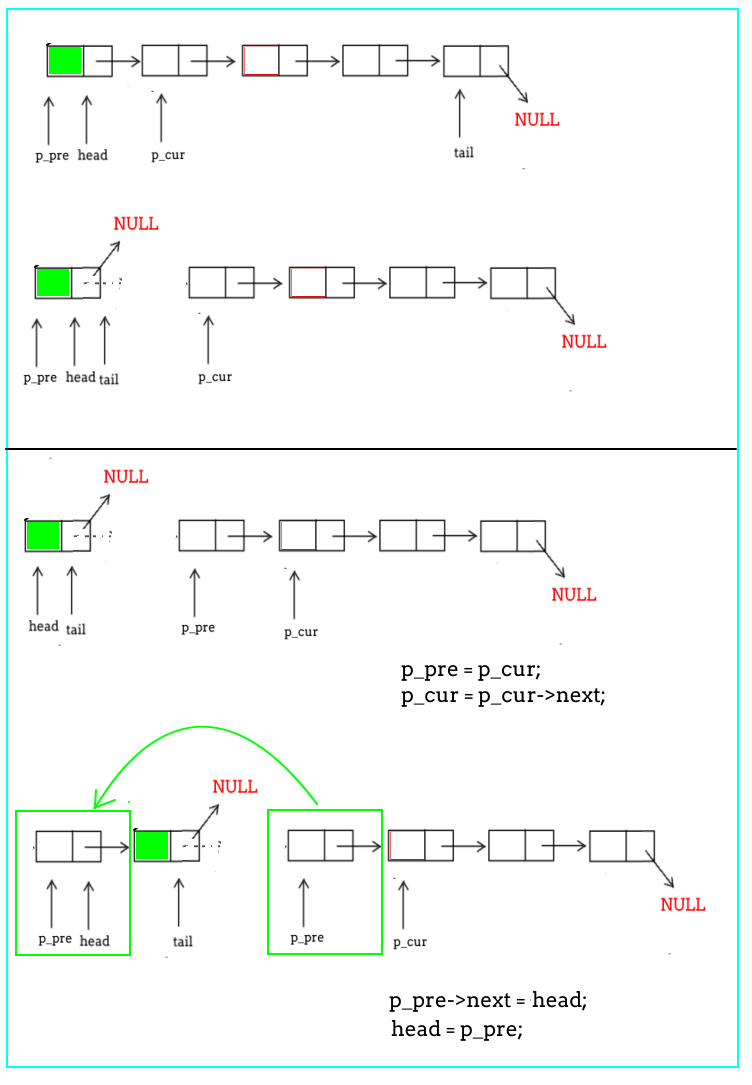
观察可以发现,逆置的过程本质上就是将原来的链表逐个摘下头节点,插入逆置后的链表的头部
void list_reverse(List *list)
{
if(list_size(list) != 0)
{
Node *p_pre = list->head;
Node *p_cur = list->head->next;
list->head->next = NULL;
list->tail = list->head;
while(p_cur!= NULL)
{
p_pre = p_cur;
p_cur = p_cur->next;
p_pre->next = list->head;
list->head = p_pre;
}
}
return;
}
0x09 list_sort
使用list_sort函数对链表进行排序,此处使用选择排序法。
void list_sort(List *list)
{
if(list_size(list) != 0)
{
Node *p_i = list->head;
while(p_i->next != NULL)
{
Node *p_min = p_i;
Node *p_j = p_min->next;
while (p_j != NULL)
{
if(list->match(p_min->data, p_j->data) > 0)
p_min = p_j;
p_j = p_j->next;
}
if(p_min != p_i)
{
void *data = p_i->data;
p_i->data = p_min->data;
p_min->data = data;
}
p_i = p_i->next;
}
}
return;
}
0x0a print_list和list_destroy
void print_list(List *list)
{
if(list->head == NULL)//链表为空
{
printf("list is empty\n");
}
else //链表非空
{
Node * p_cur = list->head;
while (p_cur)
{
list->print_data(p_cur->data);
p_cur = p_cur->next;
}
}
return;
}
void list_destroy(List *list)
{
Node *p_cur = list->head;
while (p_cur != NULL)
{
list->head = list->head->next;
list->destroy(p_cur->data);//释放节点中的数据
free(p_cur);//释放节点
p_cur = list->head;
}
memset(list, 0, sizeof (List));
return;
}
c语言之单向链表的更多相关文章
- C语言实现单向链表及其各种排序(含快排,选择,插入,冒泡)
#include<stdio.h> #include<malloc.h> #define LEN sizeof(struct Student) struct Student / ...
- ZT C语言链表操作(新增单向链表的逆序建立)
这个不好懂,不如看 转贴:C语言链表基本操作http://www.cnblogs.com/jeanschen/p/3542668.html ZT 链表逆序http://www.cnblogs.com/ ...
- C语言基础 - 实现单向链表
回归C基础 实现一个单向链表,并有逆序功能 (大学数据结构经常是这么入门的) //定义单链表结构体 typedef struct Node{ int value; struct Node *next; ...
- C语言单向链表
1,为什么要用到链表 数组作为存放同类数据的集合,给我们在程序设计时带来很多的方便,增加了灵活性.但数组也同样存在一些弊病.如数组的大小在定义时要事先规定,不能在程序中进行调整,这样一来,在程序设计中 ...
- C语言:创建动态单向链表,创建完成后,输出每一个节点的数据信息。
// // main.c // dynamic_link_list // // Created by ma c on 15/8/5. // Copyright (c) 2015. All ri ...
- C语言实现简单的单向链表(创建、插入、删除)及等效STL实现代码
实现个算法,懒得手写链表,于是用C++的forward_list,没有next()方法感觉很不好使,比如一个对单向链表的最简单功能要求: input: 1 2 5 3 4 output: 1-> ...
- C语言:将ss所指字符串中所有下标为奇数位上的字母转换成大写,若不是字母,则不转换。-删除指针p所指字符串中的所有空白字符(包括制表符,回车符,换行符)-在带头结点的单向链表中,查找数据域中值为ch的结点,找到后通过函数值返回该结点在链表中所处的顺序号,
//将ss所指字符串中所有下标为奇数位上的字母转换成大写,若不是字母,则不转换. #include <stdio.h> #include <string.h> void fun ...
- C语言:将带头节点的单向链表结点域中的数据从小到大排序。-求出单向链表结点(不包括头节点)数据域中的最大值。-将M*N的二维数组中的数据,按行依次放入一维数组,
//函数fun功能是将带头节点的单向链表结点域中的数据从小到大排序. //相当于数组的冒泡排序. #include <stdio.h> #include <stdlib.h> ...
- C语言:判断字符串是否为回文,-函数fun将单向链表结点数据域为偶数的值累加起来。-用函数指针指向要调用的函数,并进行调用。
//函数fun功能:用函数指针指向要调用的函数,并进行调用. #include <stdio.h> double f1(double x) { return x*x; } double f ...
随机推荐
- Linux集群软件安装实战
一.需求和思路 1. 需求描述 公司有N个节点的集群,需要统一安装一个软件(jdk)需要开发一个脚本程序,实现对集群中的N个节点批量自动下载.安装jdk 2. 思路 1)编写一个启动脚本,用来发送一个 ...
- 使script.bin文件配置生效的驱动
1.问题:在全志方案中如果需要设置上拉或者下拉模式,需要在script.bin(先转换为script.fex)中配置gpio口 如: 但是配置好后是不会生效的,需要写一个驱动来通过读取这个文件的gp ...
- python将当前时间加上7天
datetime.datetime.now() + datetime.timedelta(days = 7)).strftime("%Y-%m-%d"
- Okhttp教程 (1)
1. 在build.gradle里引入okhttp库 dependencies { compile fileTree(dir: 'libs', include: ['*.jar']) testComp ...
- 吴裕雄--天生自然C语言开发:函数
return_type function_name( parameter list ) { body of the function } /* 函数返回两个数中较大的那个数 */ int max(in ...
- 直击LG曲面OLED首发现场,高端品质更出众
简直是太棒了,我可以去看LG曲面OLED电视新品发布会了.这可是LG向中国首次推出的曲面OLED电视.在网上我就已经看到其实曲面OLED电视已经在韩国.美国还有欧洲都上市了,听说现在反响还挺不错.真没 ...
- java replaceall 用法:处理特殊字符
public class TryDotRegEx { public static void main(String[] args) { // TODO Auto-generated method st ...
- ddt-python测试数据驱动工具(转载)
背景 python 的unittest 没有自带数据驱动功能. 所以如果使用unittest,同时又想使用数据驱动,那么就可以使用DDT来完成. DDT是 “Data-Driven Tests”的缩写 ...
- Linux基础常用命令大全学习
1.ls命令 就是list的缩写,通过ls 命令不仅可以查看linux文件夹包含的文件,而且可以查看文件权限(包括目录.文件夹.文件权限)查看目录信息等等 常用参数搭配: ls -a 列出目录所有文 ...
- CF-558:部分题目总结
题目链接:http://codeforces.com/contest/1163 A .Eating Soup sol:在n / 2.n - m.m三个数中取最小值,结果受这三个值限制.但是m == 0 ...