Python 每日一练(5)
引言
Python每日一练又开始啦,今天的专题和Excel有关,主要是实现将txt文本中数据写入到Excel中,说来也巧,今天刚好学校要更新各团支部的人员信息,就借此直接把事情做了- 主要对于三种数据类型处理,字典型,字符串,列表
- 使用的库有
xlwt,json,主要做的操作有文件读取,数据读取以及生成xls文件(保存xlsx,会打不开)
字典型数据
- 实现分析:将文本文件读取,然后用
json读取为标准形式数据,即易于人阅读和编写的数据,最后实例化一个xls,对其写入数据,生成文件 - 代码实现:
# -*- coding:utf-8 -*-
# Author : Konmu
'''
纯文本文件 student.txt为学生信息, 里面的内容(包括花括号)如下所示:
{
"1":["张三",150,120,100],
"2":["李四",90,99,95],
"3":["王五",60,66,68]
}
请将上述内容写到 student.xls 文件中
'''
import json
import xlwt
f = open('C:/Users/xxx/Desktop/t.txt','r',encoding='utf-8')
content = f.read()
data = json.loads(content) #用于将str类型的数据转成dict
work = xlwt.Workbook()#生成Workbook对象
Sheet_Student = work.add_sheet('student',cell_overwrite_ok=True)#创建sheet对象
'''
写入信息内容
'''
col = 0
row = 0
for k,v in data.items():
Sheet_Student.write(row,col,k)
for i,j in enumerate(v):
Sheet_Student.write(row,i+1,j)
row+=1
work.save('C:/Users/xxx/Desktop/信息统计.xls')
- 测试效果:
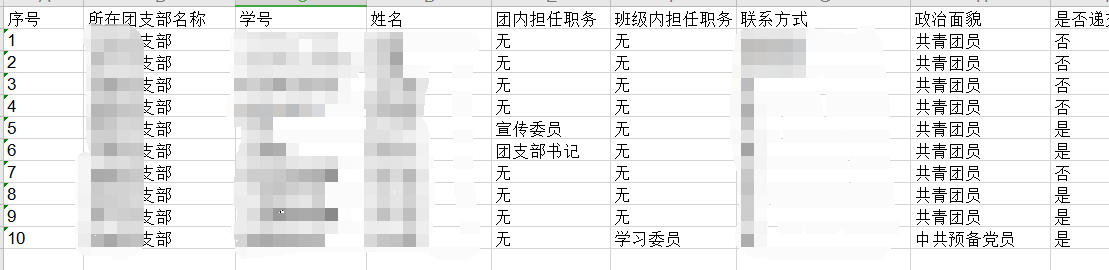
字符型数据
- 和上面这个比起来简单多了,就不赘述了
- 代码示例:
# -*- coding:utf-8 -*-
# Author : Konmu
'''
纯文本文件 city.txt为城市信息, 里面的内容(包括花括号)如下所示:
{
"1" : "上海",
"2" : "北京",
"3" : "成都"
}
请将上述内容写到 city.xls 文件中
'''
import json
import xlwt
f = open('C:/Users/xxx/Desktop/city.txt','r',encoding='utf-8')
content = f.read()
data = json.loads(content) #用于将str类型的数据转成dict
work = xlwt.Workbook()#生成Workbook对象
Sheet_Student = work.add_sheet('student',cell_overwrite_ok=True)#创建sheet对象
'''
写入信息内容
'''
col = 0
row = 0
for k,v in data.items():
Sheet_Student.write(row,col,k)
Sheet_Student.write(row,1,v)
row+=1
work.save('C:/Users/xxx/Desktop/city.xls')
列表型数据
- 最简单的一个,大家想练习的话,可以先着手弄这个,题目给的时候是由难到易的
- 代码示例:
# -*- coding:utf-8 -*-
# Author : Konmu
'''
纯文本文件 numbers.txt, 里面的内容(包括方括号)如下所示:
[
[1, 82, 65535],
[20, 90, 13],
[26, 809, 1024]
]
'''
import json
import xlwt
f = open('C:/Users/xxxx/Desktop/number.txt','r',encoding='utf-8')
content = f.read()
data = json.loads(content) #用于将str类型的数据转成dict
work = xlwt.Workbook()#生成Workbook对象
Sheet_Student = work.add_sheet('student',cell_overwrite_ok=True)#创建sheet对象
'''
写入信息内容
'''
for row in range(len(data)):
for col in range(len(data[0])):
Sheet_Student.write(row,col,data[row][col])
work.save('C:/Users/xxxx/Desktop/number.xls')
结语
Excel在我们的日常中运用的还是很广泛的,能够快捷的对大量数据进行操作还是能帮我们节省很多的时间的,完结,撒花★,°:.☆( ̄▽ ̄)/$:.°★ 。
Python 每日一练(5)的更多相关文章
- python每日一练:0007题
第 0007 题: 有个目录,里面是你自己写过的程序,统计一下你写过多少行代码.包括空行和注释,但是要分别列出来. # -*- coding:utf-8 -*- import os def count ...
- [python每日一练]--0012:敏感词过滤 type2
题目链接:https://github.com/Show-Me-the-Code/show-me-the-code代码github链接:https://github.com/wjsaya/python ...
- Python 每日一练 | Flask 实现半成品留言板
留言板Flask实现 引言 看了几天网上的代码,终于写出来一个半成品的Flask的留言板项目,为什么说是半成品呢?因为没能实现留言板那种及时评论刷新的效果,可能还是在重定向上有问题 或者渲染写的存在问 ...
- Python 每日一练(4)
引言 今天继续是python每日一练的几个专题,主要涵盖简单的敏感词识别以及图片爬虫 敏感词识别 这个敏感词的识别写的感觉比较简单,总的概括之后感觉功能可以简略成if filter_words in ...
- Python 每日一练(3)
引言 今天的每日一练,学习了一下用Python生成四位的图像验证码,就是我们常常在登录时见到的那种(#`O′) 思路分析 正如常见的那种图像验证码,它是由数字和字母的随机组合产生的,所以我们首先的第一 ...
- Python每日一练(1)
这两天在做Python的每日一练,感觉收获颇丰,所以来记录分享一下,一共做了三个,涉及socket,PIL,pymysql三个库,另外终于开始了Flask框架的学习,后续也会做出一些分析 第一个是一个 ...
- Python 每日一练(2)
引言 我又双叒叕的来啦,新博客的第二篇文章,这次是继之前公众号上每日一练的第二个,这次是专题实对于文件的一些处理的练习 主要有以下几类: 1.实现英文文章字频统计 2.统一剪裁某一指定目录下的所有图片 ...
- Python每日一练(1):计算文件夹内各个文章中出现次数最多的单词
#coding:utf-8 import os,re path = 'test' files = os.listdir(path) def count_word(words): dic = {} ma ...
- Python 每日一练(7)
引言 今天的练习比较轻松,原本是有两题的,但是第一题那个大致看了一下,其实和之前的6个练习差不多,就是把xls中的文件数据读取出来后,进行一下处理,对于那题而言就是一个求和操作,所以就没练了,所以今天 ...
随机推荐
- spark系列-3、缓存、共享变量
一.persist 和 unpersist 1.1.persist() : 用来设置RDD的存储级别 存储级别 意义 MEMORY_ONLY 将RDD作为反序列化的的对象存储JVM中.如果RDD不能 ...
- 两个命令把 Vim 打造成 Python IDE
运行下面两个命令,即可把 Vim(含插件)配置成 Python IDE.目前支持 MAC 和 Ubuntu. Shell curl -O https://raw.githubusercontent ...
- 使用django开发论坛输出调试信息时附加远程客户端IP地址!
前言 最近使用django开发了个匿名社区(哈士奇社区 4nmb.com),但是有个问题一直困扰我半天,就是如何在django调试信息上输出远程客户端的真实IP地址,在网上找了很多资料也没见人遇到过, ...
- vue 搭建框架到安装插件依赖,Element、axios、qs等
一.使用vue 单页面开发,首先要安装好本地环境 步骤如下: 1 下载nodejs 安装 (此时npm 和 node环境都已经装好)2 安装淘宝镜像 npm install -g cnpm --reg ...
- cmake安装jsoncpp
cd jsoncpp- mkdir -p build/debug cd build/debug cmake -DCMAKE_BUILD_TYPE=release -DBUILD_STATIC_LIBS ...
- spring学习笔记(二)spring中的事件及多线程
我们知道,在实际开发中为了解耦,或者提高用户体验,都会采用到异步的方式.这里举个简单的例子,在用户注册的sh时候,一般我们都会要求手机验证码验证,邮箱验证,而这都依赖于第三方.这种情况下,我们一般会通 ...
- python学习之组成字符串的两种方式
第一种就是加法,比如 a ='张三' b = '李四' 那么print c =a+b 例如之前提到的 或者数值转换成字符串的 num = 100 str(num) 其他参照表格中的转换即可 2.组成 ...
- ssh chroot 设置
目的 让特定的用户登录linux服务器后,对其操作权限进行限制: 不能使用任何方式杀掉服务器现有的进程 最好只能查看相关的目录和文件 最好只能运行特定的命令,比如cat.ls.tail等 场景模拟 一 ...
- 最小生成树的本质是什么?Prim算法道破天机
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是算法和数据结构专题20篇文章,我们继续最小生成树算法,来把它说完. 在上一篇文章当中,我们主要学习了最小生成树的Kruskal算法.今 ...
- 写ssm项目的注意点
注意事项: 输出台乱码 a链接以post提交 表单提交前验证 onsubmit 属性在提交表单时触发. onsubmit 属性只在 中使用. <form action="/demo/d ...