Python爬虫系列(五):分析HTML结构
今晚,被烦死了。9点多才下班,就想回来看书学习,结果被唠叨唠叨个小时,我不断喊不要和我聊天了,还反复说。我只想安安静静看看书,学习学习,全世界都不要打扰我
接着上一个讨论,我们今晚要分析HTML结构了
1.获取元素
html_doc = """
<html>
<head>
<title>The Dormouse's story
</title>
</head>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
# 直接访问head元素
print(soup.head)
# 多个a元素只会返回第一个
print(soup.a)
# 通过层级获取 注意:上面没有body,soup会自动补全
print(soup.body.p)
# 获取所有a,返回a的数组
print(soup.find_all('a'))
2.获取内容和子元素
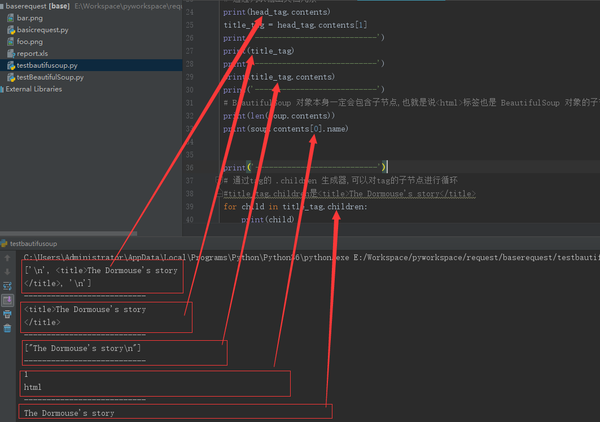
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
head_tag = soup.head
# 通过列表输出文档元素
print(head_tag.contents)
title_tag = head_tag.contents[1]
print('---------------------------')
print(title_tag)
print('---------------------------')
print(title_tag.contents)
print('---------------------------')
# BeautifulSoup 对象本身一定会包含子节点,也就是说<html>标签也是 BeautifulSoup 对象的子节点:
print(len(soup.contents))
print(soup.contents[0].name)
print('---------------------------')
# 通过tag的 .children 生成器,可以对tag的子节点进行循环
#title_tag.children是<title>The Dormouse's story</title>
for child in title_tag.children:
print(child)
# 字符串没有 .contents 属性,因为字符串没有子节点:
print('---------------------------')
text = title_tag.contents[0]
print(text.contents) #直接报错 :AttributeError: 'NavigableString' object has no attribute 'contents'
3.跨级获取子节点
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
head_tag = soup.head
# 递归获取所有子节点
for child in head_tag.descendants:
print('-----------------------')
print(child)
# 直接子节点
print(len(list(soup.children)))
# 跨级子节点:包括换行符 都算成了子节点。在使用的过程中,一定要注意判空
print(len(list(soup.descendants)))
4.string字符串
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
head_tag = soup.head
# title_tag.string是title标签的子节点。即便是纯粹的string 这个就是 NavigableString
# print(title_tag.string)
# 如果一个tag仅有一个子节点,那么这个tag也可以使用 .string 方法,输出结果与当前唯一子节点的 .string 结果相同:
print(head_tag.contents)
# 如果tag包含了多个子节点,tag就无法确定 .string 方法应该调用哪个子节点的内容, .string 的输出结果是 None :
print(soup.html.string)
5.遍历字符串和去除空白字符
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
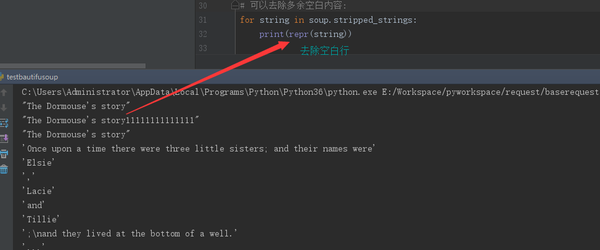
# 如果tag中包含多个字符串 [2] ,可以使用 .strings 来循环获取:
# for string in soup.strings:
# print(repr(string))
# 输出的字符串中可能包含了很多空格或空行, 使用.stripped_strings
# 可以去除多余空白内容:
for string in soup.stripped_strings:
print(repr(string))

去除空白字符
6.父节点
每个节点都有自己的父节点。除了第一个
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, "lxml")
title_tag = soup.title
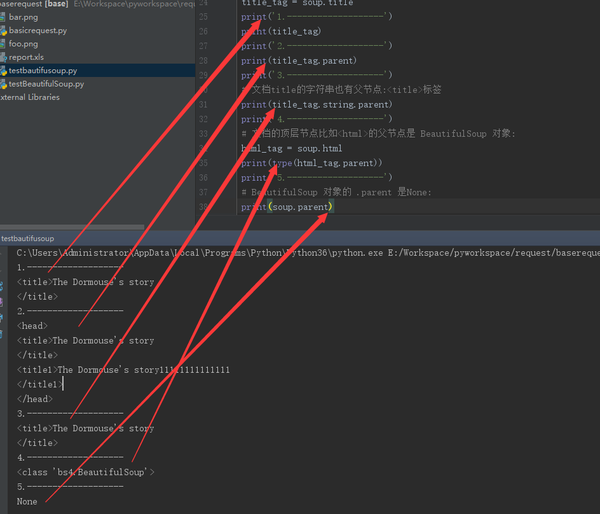
print('1.-------------------')
print(title_tag)
print('2.-------------------')
print(title_tag.parent)
print('3.-------------------')
# 文档title的字符串也有父节点:<title>标签
print(title_tag.string.parent)
print('4.-------------------')
# 文档的顶层节点比如<html>的父节点是 BeautifulSoup 对象:
html_tag = soup.html
print(type(html_tag.parent))
print('5.-------------------')
# BeautifulSoup 对象的 .parent 是None:
print(soup.parent)
遍历所有父节点:
soup = BeautifulSoup(html_doc, "lxml")
link = soup.a
for parent in link.parents:
if parent is None:
print(parent)
else:
print(parent.name)

7.兄弟节点
同一个级别的节点查找
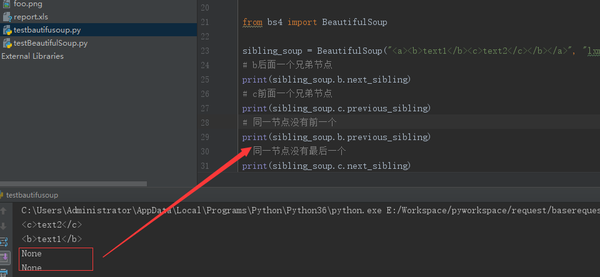
sibling_soup = BeautifulSoup("<a><b>text1</b><c>text2</c></b></a>", "lxml")
# b后面一个兄弟节点
print(sibling_soup.b.next_sibling)
# c前面一个兄弟节点
print(sibling_soup.c.previous_sibling)
# 同一节点没有前一个
print(sibling_soup.b.previous_sibling)
# 同一节点没有最后一个
print(sibling_soup.c.next_sibling)
获取前后所有的兄弟节点
注意:这些节点包括字符串和符号
soup = BeautifulSoup(html_doc, "lxml")
for sibling in soup.a.next_siblings:
print('--------------------------')
print(repr(sibling))
for sibling in soup.find(id="link3").previous_siblings:
print('******************************')
print(repr(sibling))

8.回退和前进
注意看next_sibling和next_element的差别
soup = BeautifulSoup(html_doc, "lxml")
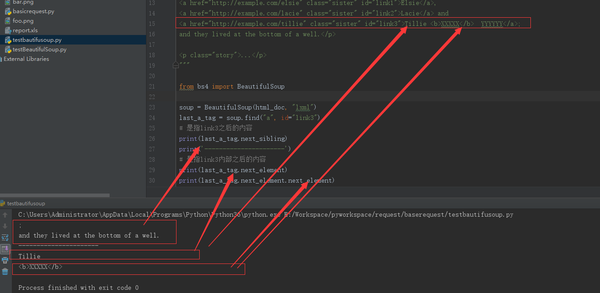
last_a_tag = soup.find("a", id="link3")
# 是指link3之后的内容
print(last_a_tag.next_sibling)
print('----------------------')
# 是指link3内部之后的内容
print(last_a_tag.next_element)
print(last_a_tag.next_element.next_element)
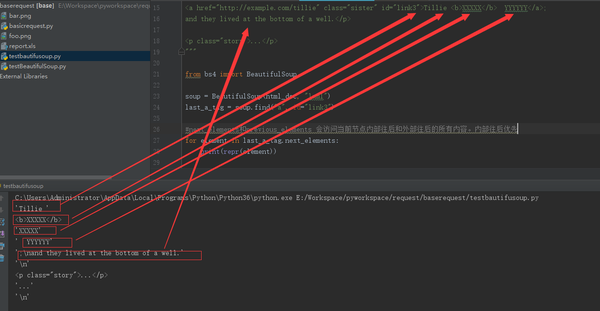
soup = BeautifulSoup(html_doc, "lxml")
last_a_tag = soup.find("a", id="link3")
#next_elements和previous_elements 会访问当前节点内部往后和外部往后的所有内容。内部往后优先
for element in last_a_tag.next_elements:
print(repr(element))
还有一节,培训新手的文档就结束了。真心希望同学们要好好学习,不然我白讲。 不下班回家陪我的小公举,却来义务教你写代码,而且是从零开始手把手教。兄弟们要加油啊
Python爬虫系列(五):分析HTML结构的更多相关文章
- 爬虫系列(五) re的基本使用
1.简介 究竟什么是正则表达式 (Regular Expression) 呢?可以用下面的一句话简单概括: 正则表达式是一组特殊的 字符序列,由一些事先定义好的字符以及这些字符的组合形成,常常用于 匹 ...
- Python爬虫实战五之模拟登录淘宝并获取所有订单
经过多次尝试,模拟登录淘宝终于成功了,实在是不容易,淘宝的登录加密和验证太复杂了,煞费苦心,在此写出来和大家一起分享,希望大家支持. 温馨提示 更新时间,2016-02-01,现在淘宝换成了滑块验证了 ...
- Python爬虫进阶五之多线程的用法
前言 我们之前写的爬虫都是单个线程的?这怎么够?一旦一个地方卡到不动了,那不就永远等待下去了?为此我们可以使用多线程或者多进程来处理. 首先声明一点! 多线程和多进程是不一样的!一个是 thread ...
- Python爬虫入门五之URLError异常处理
大家好,本节在这里主要说的是URLError还有HTTPError,以及对它们的一些处理. 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的 ...
- 转 Python爬虫入门五之URLError异常处理
静觅 » Python爬虫入门五之URLError异常处理 1.URLError 首先解释下URLError可能产生的原因: 网络无连接,即本机无法上网 连接不到特定的服务器 服务器不存在 在代码中, ...
- Python爬虫和情感分析简介
摘要 这篇短文的目的是分享我这几天里从头开始学习Python爬虫技术的经验,并展示对爬取的文本进行情感分析(文本分类)的一些挖掘结果. 不同于其他专注爬虫技术的介绍,这里首先阐述爬取网络数据动机,接着 ...
- Python爬虫系列 - 初探:爬取旅游评论
Python爬虫目前是基于requests包,下面是该包的文档,查一些资料还是比较方便. http://docs.python-requests.org/en/master/ POST发送内容格式 爬 ...
- python 爬虫系列教程方法总结及推荐
爬虫,是我学习的比较多的,也是比较了解的.打算写一个系列教程,网上搜罗一下,感觉别人写的已经很好了,我没必要重复造轮子了. 爬虫不过就是访问一个页面然后用一些匹配方式把自己需要的东西摘出来. 而访问页 ...
- $python爬虫系列(2)—— requests和BeautifulSoup库的基本用法
本文主要介绍python爬虫的两大利器:requests和BeautifulSoup库的基本用法. 1. 安装requests和BeautifulSoup库 可以通过3种方式安装: easy_inst ...
随机推荐
- Altium Designer 20下载与安装教程
目录 一.Altium Designer 20下载 二.Altium Designer 20安装 三.Altium Designer 20破解 四.Altium Designer 20汉化 作者:st ...
- Natas15 Writeup(sql盲注之布尔盲注)
Natas15: 源码如下 /* CREATE TABLE `users` ( `username` varchar(64) DEFAULT NULL, `password` varchar(64) ...
- 【转】Kerberos简介
Kerberos协议: Kerberos协议主要用于计算机网络的身份鉴别(Authentication), 其特点是用户只需输入一次身份验证信息就可以凭借此验证获得的票据(ticket-grantin ...
- 小米官网轮播图js+css3+html实现
官网轮播: 我的轮播: 重难点: 1.布局 2.图片和右下角小圆点的同步问题 3.setInterval定时器的使用 4.淡入淡出动画效果 5.左右箭头点击时,图片和小圆点的效果同步 6.另一种轮播思 ...
- 还是只使用console.log()进行调试?好吧,其实还有更多。
在浏览器控制台中打印消息无疑可以拯救所有开发人员. console.log()消息就像您的大多数疾病的药,同时调试了代码中的一些有线问题. 那里的大多数开发人员都喜欢— 让我们在浏览器中打印消息以了解 ...
- Java基础语法(2)-变量
title: Java基础语法(2)-变量 blog: CSDN data: Java学习路线及视频 1.什么是变量? 变量的概念 内存中的一个存储区域 该区域的数据可以在同一类型范围内不断变化 变量 ...
- 两片74门实现的双边沿D触发器
最近一个项目需要时钟上升沿和下降沿都可以触发的D触发器,但并没有找到符合要求的商品IC.也去看了一些文献,但都是给的示意图然后用分立元件实现的(应该是准备做成IC).这里给出一种最少2个IC就能搭出来 ...
- [最短路,floyd] Codeforces 1204C Anna, Svyatoslav and Maps
题目:http://codeforces.com/contest/1204/problem/C C. Anna, Svyatoslav and Maps time limit per test 2 s ...
- iOS自动化环境搭建(超详细)
1.macOS相关库安装 libimobiledevice > brew install libimobiledevice 使用本机与苹果iOS设备的服务进行通信的库. ideviceinsta ...
- Error response from daemon: rpc error: code = AlreadyExists desc = name conflicts with an existing object: service myweb already exists
主机环境 centos7.2 执行 docker service create --replicas 6 --name myweb -p 80:80 nginx:latest 时 报 Error re ...