记录一个不同的流媒体网站实现方法,和用Python爬虫爬它的坑
今天找到一片电影,想把它下载下来。
先开Networks工具分析一下:

初步分析发现,视频加载时会拉取TS格式的文件,推测这是一个m3u8的索引,记录着几百段TS文件,这样方便快进时加载。
但是实际分析m3u8文件时,发现这并不是一个有效的索引文件,应该只是载入一个形式,实际的handler在其他地方:

但这样分析js太麻烦了。通过几次尝试,发现了规律:视频文件名是由y8TL59oh4680xxx.ts组成的,xxx是序号,这样就简单多了!
把之前爬音乐文件的爬虫改一改,得到这样一个程序:
import requests
import os
import re
from tkinter import Tk
from tkinter.simpledialog import askinteger, askfloat, askstring
from tkinter.filedialog import askopenfilename, askopenfilenames, asksaveasfilename, askdirectory
from tkinter.messagebox import showinfo, showwarning, showerror
def downloadSong(SongID, FileName):
headers = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36"}
r = requests.get("https://www.mmicloud.com/20190406/I1RrJf8s/2000kb/hls/y8TL59oh" + str(SongID) + ".ts",headers=headers);
#print("State:")
#print(r)
filepath=os.path.join(str(SongID) + ".ts")
with open(filepath,"wb") as file:
file.write(r.content)
print(SongID)
for i in range(4680000, 4680900):
downloadSong(i, str(i))
这个程序循环爬取文件名从y8TL59oh4680000.ts到y8TL59oh4680899.ts的900个视频文件。
程序中的循环最大值之所以定在4680900,是因为我发现影片有860多段,于是就多下载一些,如果下载不了就是下完了,出错倒也无所谓。
让他开始运行,看起来工作良好,有在顺利的下载文件:
于是我就放下手头的事,先休息去了。过了大约半个小时,他已经下载了300多个文件了:
我就放下心来,这个爬虫应该是没什么问题了,于是我就用VSCode写了一些代码。当我再次看到任务栏时,爬虫已经不见了!
我再次启动爬虫,过了一会又会有同样的问题!难道是变量i溢出了?试着debug一下,把i的范围缩小试试:
import requests
import os
import re
from tkinter import Tk
from tkinter.simpledialog import askinteger, askfloat, askstring
from tkinter.filedialog import askopenfilename, askopenfilenames, asksaveasfilename, askdirectory
from tkinter.messagebox import showinfo, showwarning, showerror
def downloadSong(SongID, FileName):
headers = {"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36"}
r = requests.get("https://www.mmicloud.com/20190406/I1RrJf8s/2000kb/hls/y8TL59oh4680" + str(SongID) + ".ts",headers=headers);
#print("State:")
#print(r)
filepath=os.path.join(str(SongID) + ".ts")
with open(filepath,"wb") as file:
file.write(r.content)
print(SongID)
for i in range(566, 900):
downloadSong(i, str(i))
经过debug,发现程序应该是没有问题,只是因为控制台窗口最小化时,爬虫会被内存回收掉,所以导致了程序退出。
折腾了半天!
我换成用IDLE编辑器自带的Run Modules,有普通窗口的话就不容易被回收掉把:

过了一阵子,爬虫终于把文件爬完了。一看文件夹,又出问题了:

文件名不一致!
还记得之前我们debug的时候把变量i的范围改小了吗?这就是原因!
那好吧,选中所有名字长的文件,右键,重命名,命名成a,然后文件就可以自动命名为a (1), a (2), a (3), a (4), a (5), ...这样。
问题。。解决了?
我拿着这些命名为a (1), a (2), a (3), a (4), a (5), ...的文件去转码,合并,来来回回整了一个小时多。当合并之后,才发现,
文件顺序全是乱的!!!
啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊啊天煞的Windows!!!!!!!!!!
没办法,有气出不来,只好继续写代码。。。
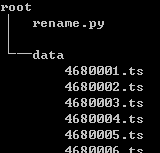
还好我留了一份没有重命名过的文件夹,那就用python写一个批量重命名程序吧:
import os
PROJECT_DIR_PATH = os.path.dirname(os.path.abspath(os.path.abspath(__file__)))
DIR_PATH = os.path.join(PROJECT_DIR_PATH, 'data')
files = os.listdir(DIR_PATH)
for filename in files:
name, suffix = os.path.splitext(filename)
new_name = os.path.join(DIR_PATH, name[4:7])
old_name = os.path.join(DIR_PATH, filename)
os.rename(old_name, new_name)
把文件目录改成这样,就可以使用上面的程序了:
爽爽快快的运行完程序,发现命名是成功了,但后缀名没有了。。。
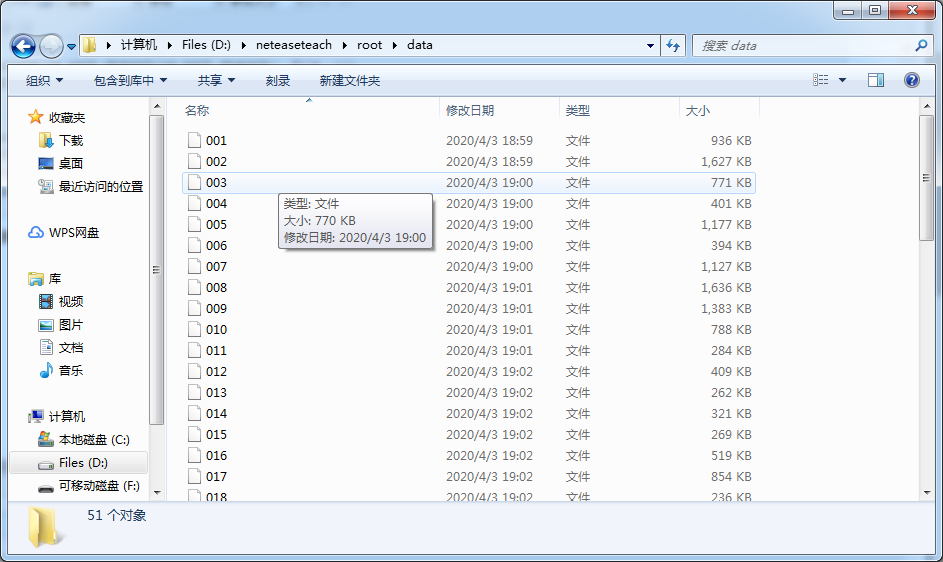
失误失误!再写一个补救程序:
import os
PROJECT_DIR_PATH = os.path.dirname(os.path.abspath(os.path.abspath(__file__)))
DIR_PATH = os.path.join(PROJECT_DIR_PATH, 'data')
files = os.listdir(DIR_PATH)
for filename in files:
name, suffix = os.path.splitext(filename)
new_name = os.path.join(DIR_PATH, filename + ".ts")
old_name = os.path.join(DIR_PATH, filename)
os.rename(old_name, new_name)
心惊胆战的运行完,目录终于正常了:
然后又是转码、合并,又是一个多小时。最后,总算拿到了胜利的果实:

太难了!
下载这篇电影花费了我一整天的时间。上午和中午找片源,下午写代码+写爬虫+爬资源,晚上还得操心重命名和转码的问题,这中间都够我看6-7片电影了。ε=(´ο`*)))唉。。。
不多说了,电影只能明天看了。各位,晚安!
记录一个不同的流媒体网站实现方法,和用Python爬虫爬它的坑的更多相关文章
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- Python爬虫爬取美剧网站
一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间.之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了.但是,作为一个宅diao ...
- 批量下载小说网站上的小说(python爬虫)
随便说点什么 因为在学python,所有自然而然的就掉进了爬虫这个坑里,好吧,主要是因为我觉得爬虫比较酷,才入坑的. 想想看,你可以批量自动的采集互联网上海量的资料数据,是多么令人激动啊! 所以我就被 ...
- 【记录一个问题】用毫无用处的方法解决了libtask的asm.S在ndk下编译的问题
昨天提到,libtask中的asm.S使用的是ARM 32位的语法,因此在ARM 64下无法编译通过. 于是查了一下资料,改写了一下汇编代码,使得可以在64位下编译通过.源码如下 #if define ...
- 记录一个引用文件所有js文件的方法
在项目api声明的时候,避免每次添加新的js都要对应去处理 首先我在项目api文件下新建一个files的文件夹,然后再api文件夹下的index.js这样写: var api = {}; const ...
- python爬虫爬取ip记录网站信息并存入数据库
import requests import re import pymysql #10页 仔细观察路由 db = pymysql.connect("localhost",&quo ...
- 7月17日——高校就业信息网站功能及数据获取之python爬虫
本周我们小组在分析上周用户需求之后,确定了网站的主要框架和功能.数据收集和存储方式,以及项目任务分配. 一.网站的主要框架和功能. 网站近期将要实现的主要功能有,先重点收集高校(华东五校)就业宣讲会的 ...
- python爬虫--爬取某网站电影下载地址
前言:因为自己还是python世界的一名小学生,还有很多路要走,所以本文以目的为向导,达到目的即可,对于那些我自己都没弄懂的原理,不做去做过多解释,以免误人子弟,大家可以网上搜索. 友情提示:本代码用 ...
- 写一个python 爬虫爬取百度电影并存入mysql中
目标是利用python爬取百度搜索的电影 在类型 地区 年代各个标签下 电影的名字 评分 和图片连接 以及 电影连接 首先我们先在mysql中建表 create table liubo4( id in ...
随机推荐
- Windows激活服务器搭建
1.下载服务端的安装包,下载地址: https://github.com/Wind4/vlmcsd/releases 注意,下载编译好的包省时间,名称为:binaries.tar.gz 或者直接下载我 ...
- Flutter01-学习准备
1. 简介: Flutter是谷歌的移动UI框架,可以快速在iOS和Android上构建高质量的原生用户界面. Flutter可以与现有的代码一起工作.在全世界,Flutter正在被越来越多的开发者和 ...
- JS 获取一段时间内的工作时长小时数
本来想是想找轮子的,但是并没有找到能用的,多数都是问题很大,所以就自己写了一个 需求说明 支持自选时间段,即开始时间与结束时间根据用户的上班及下班时间判定返回小时数 技术栈 moment.js 思考过 ...
- 零基础JavaScript编码(一)
任务目的 JavaScript初体验 初步明白JavaScript的简单基本语法,如变量.函数 初步了解JavaScript的事件是什么 初步了解JavaScript中的DOM是什么 任务描述 参考以 ...
- koa进阶史(一)
1,设置静态文件目录,将__dirname 写成_dirname,乍看没什么毛病,但是一运行之后发现,_dirname is not defined,下次注意哈 app.use(express.sta ...
- weex 和 appcan 的个人理解
appcan是浏览器技术,前端代码运行在webview上,而weex是原生引擎渲染,说白了就是把H5翻译成原生. weex的官网上说,在开发weex页面就像开发普通网页一样,在渲染weex页面时和原生 ...
- Markdown For EditPlus插件发布(基于EditPlus快速编辑Markdonw文件,写作爱好的福音来啦)
详细介绍: Markdown For EditPlus插件使用说明 开发缘由 特点好处: 中文版使用说明 相关命令(输入字符敲空格自动输出): EditPlus常用快捷键: 相关教程: English ...
- django models中字段
AutoField:一个自动递增的整型字段,添加记录时它会自动增长.你通常不需要直接使用这个字段:如果你不指定主键的话,系统会自动添加一个主键字段到你的model.(参阅自动主键字段) Boolean ...
- python_字符串&列表&元组&字典之间转换学习
#!/usr/bin/env/python #-*-coding:utf-8-*- #Author:LingChongShi #查看源码Ctrl+左键 #数据类型之间的转换 Str='www.baid ...
- AspNetCore3.1_Secutiry源码解析_2_Authentication_核心对象
系列文章目录 AspNetCore3.1_Secutiry源码解析_1_目录 AspNetCore3.1_Secutiry源码解析_2_Authentication_核心项目 AspNetCore3. ...