12 Spring Data JPA:orm思想和hibernate以及jpa的概述和jpa的基本操作
spring data jpa
day1:orm思想和hibernate以及jpa的概述和jpa的基本操作day3:多表操作,复杂查询
day1:orm思想和hibernate以及jpa的概述和jpa的基本操作
第一 orm思想
主要目的:操作实体类就相当于操作数据库表
建立两个映射关系:
实体类和表的映射关系
实体类中属性和表中字段的映射关系
不再重点关注:具体的sql语句
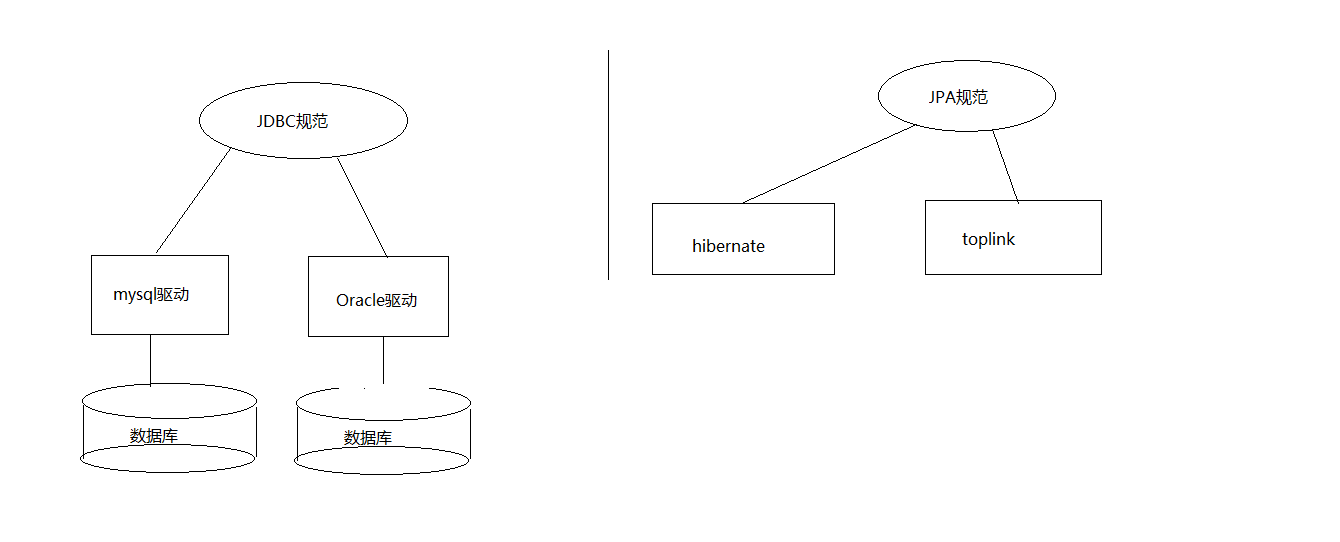
实现了ORM思想的框架:mybatis,hibernate
第二 hibernate框架介绍
Hibernate是一个开放源代码的对象关系映射框架,
它对JDBC进行了封装,
它将POJO与数据库表建立映射关系,是一个全自动的orm框架。
第三 JPA规范
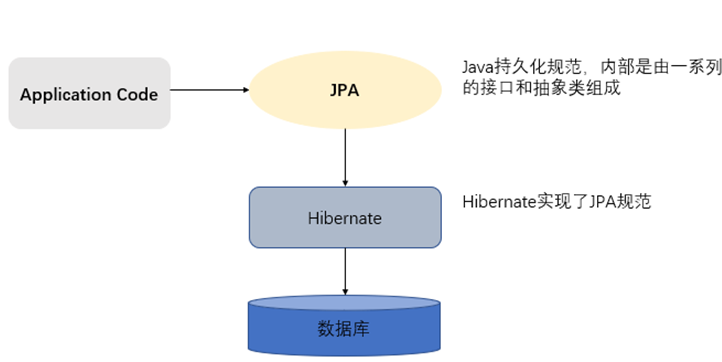
JPA的全称是Java Persistence API,jpa是一套基于ORM的规范,内部是由接口和抽象类组成。
第1章 JPA的入门案例
1.1 需求介绍
本章节我们是实现的功能是保存一个客户到数据库的客户表中。
1.2 开发包介绍
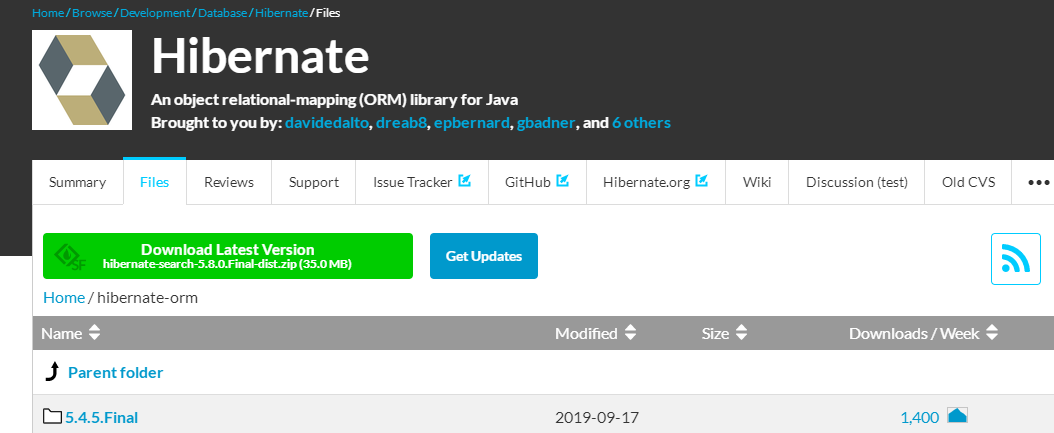
由于JPA是sun公司制定的API规范,所以我们不需要导入额外的JPA相关的jar包,只需要导入JPA的提供商的jar包。我们选择Hibernate作为JPA的提供商,所以需要通过Maven导入Hibernate的相关jar包。
https://sourceforge.net/projects/hibernate/files/hibernate-orm/
1.3 搭建开发环境
创建客户的数据库表
/*创建客户表*/
CREATE TABLE cst_customer (
cust_id bigint(32) NOT NULL AUTO_INCREMENT COMMENT '客户编号(主键)',
cust_name varchar(32) NOT NULL COMMENT '客户名称(公司名称)',
cust_source varchar(32) DEFAULT NULL COMMENT '客户信息来源',
cust_industry varchar(32) DEFAULT NULL COMMENT '客户所属行业',
cust_level varchar(32) DEFAULT NULL COMMENT '客户级别',
cust_address varchar(128) DEFAULT NULL COMMENT '客户联系地址',
cust_phone varchar(64) DEFAULT NULL COMMENT '客户联系电话',
PRIMARY KEY (`cust_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
i.搭建环境的过程
1.创建maven工程导入坐标
2.需要配置jpa的核心配置文件
*位置:配置到类路径下的一个叫做 META-INF 的文件夹下
*命名:persistence.xml
3.编写客户的实体类
4.配置实体类和表,类中属性和表中字段的映射关系
5.保存客户到数据库中
1.3.1 maven工程导入坐标
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.hibernate.version>5.3.5.Final</project.hibernate.version>
</properties> <dependencies>
<!-- hibernate对jpa的支持包 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- c3p0 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-c3p0</artifactId>
<version>${project.hibernate.version}</version>
</dependency>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- log日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- Mysql and MariaDB -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.17</version>
</dependency>
</dependencies>
1.3.2 需要配置jpa的核心配置文件
maven项目的resources目录下新建一个Directory
META-INF
在resources/META-INF目录下新建一个XML配置文件
persistence.xml
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="2.0">
<!--需要配置persistence-unit节点
持久化单元:
name:持久化单元名称
transaction-type:事务管理的方式
JTA:分布式事务管理
RESOURCE_LOCAL:本地事务管理
-->
<persistence-unit name="myJpa" transaction-type="RESOURCE_LOCAL">
<!--jpa的实现方式 -->
<provider>org.hibernate.jpa.HibernatePersistenceProvider</provider> <!--可选配置:配置jpa实现方的配置信息-->
<properties>
<!-- 数据库信息
用户名,javax.persistence.jdbc.user
密码, javax.persistence.jdbc.password
驱动, javax.persistence.jdbc.driver
数据库地址 javax.persistence.jdbc.url
-->
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="javax.persistence.jdbc.password" value="root"/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql:///itheima?serverTimezone=Asia/Shanghai"/> <!--配置jpa实现方(hibernate)的配置信息
显示sql : false|true
自动创建数据库表 : hibernate.hbm2ddl.auto
create : 程序运行时创建数据库表(如果有表,先删除表再创建)
update :程序运行时创建表(如果有表,不会创建表)
none :不会创建表 -->
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.hbm2ddl.auto" value="update" />
</properties>
</persistence-unit>
</persistence>
1.3.3 编写实体类和数据库表的映射配置
在实体类上使用JPA注解的形式配置映射关系
package cn.bjut.domain; import javax.persistence.*; /**
* 客户的实体类
* 配置映射关系
*
*
* 1.实体类和表的映射关系
* @Entity:声明实体类
* @Table : 配置实体类和表的映射关系
* name : 配置数据库表的名称
* 2.实体类中属性和表中字段的映射关系
*
*
*/
@Entity
@Table(name = "cst_customer")
public class Customer { /**
* @Id:声明主键的配置
* @GeneratedValue:配置主键的生成策略
* strategy
* GenerationType.IDENTITY :自增,mysql
* * 底层数据库必须支持自动增长(底层数据库支持的自动增长方式,对id自增)
* GenerationType.SEQUENCE : 序列,oracle
* * 底层数据库必须支持序列
* GenerationType.TABLE : jpa提供的一种机制,通过一张数据库表的形式帮助我们完成主键自增
* GenerationType.AUTO : 由程序自动的帮助我们选择主键生成策略
* @Column:配置属性和字段的映射关系
* name:数据库表中字段的名称
*/
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "cust_id")
private Long custId; //客户的主键 @Column(name = "cust_name")
private String custName;//客户名称 @Column(name="cust_source")
private String custSource;//客户来源 @Column(name="cust_level")
private String custLevel;//客户级别 @Column(name="cust_industry")
private String custIndustry;//客户所属行业 @Column(name="cust_phone")
private String custPhone;//客户的联系方式 @Column(name="cust_address")
private String custAddress;//客户地址 //===============下面是get/set方法和toString()方法=================//
1.3.4 实现保存操作
在src/test/java 目录下新建一个package
cn.bjut.test
JpaTest
package cn.bjut.test; import cn.bjut.domain.Customer;
import org.junit.Test; import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence; public class JpaTest {
/**
* 测试jpa的保存
* 案例:保存一个客户到数据库中
* Jpa的操作步骤
* 1.加载配置文件创建工厂(实体管理器工厂)对象
* 2.通过实体管理器工厂获取实体管理器
* 3.获取事务对象,开启事务
* 4.完成增删改查操作
* 5.提交事务(回滚事务)
* 6.释放资源
*/
@Test
public void testSave_01() {
//1.加载配置文件创建工厂(实体管理器工厂)对象
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJpa");
//2.通过实体管理器工厂获取实体管理器
EntityManager entityManager = factory.createEntityManager();
//3.获取事务对象,开启事务
EntityTransaction tx = entityManager.getTransaction();//获取事务对象
tx.begin(); //开启事务
//4.完成增删改查操作:保存一个客户到数据库中
Customer customer = new Customer();
customer.setCustName("Kang");
customer.setCustIndustry("Java后端开发");
//保存操作
entityManager.persist(customer);
//5.提交事务
tx.commit();
//6.释放资源
entityManager.close();
factory.close(); } }
第4章 JPA中的主键生成策略
通过annotation(注解)来映射hibernate实体的,基于annotation的hibernate主键标识为@Id, 其生成规则由@GeneratedValue设定的.这里的@id和@GeneratedValue都是JPA的标准用法。
IDENTITY:主键由数据库自动生成(主要是自动增长型) mysql
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long custId;
SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。 oracle
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,generator="payablemoney_seq")
@SequenceGenerator(name="payablemoney_seq", sequenceName="seq_payment")
private Long custId; //@SequenceGenerator源码中的定义
@Target({TYPE, METHOD, FIELD})
@Retention(RUNTIME)
public @interface SequenceGenerator {
//表示该表主键生成策略的名称,它被引用在@GeneratedValue中设置的“generator”值中
String name();
//属性表示生成策略用到的数据库序列名称。
String sequenceName() default "";
//表示主键初识值,默认为0
int initialValue() default 0;
//表示每次主键值增加的大小,例如设置1,则表示每次插入新记录后自动加1,默认为50
int allocationSize() default 50;
}
AUTO:主键由程序控制
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long custId;
TABLE:使用一个特定的数据库表格来保存主键
第5章 JPA的API介绍
5.1 Persistence对象
Persistence对象主要作用是用于获取EntityManagerFactory对象的 。通过调用该类的createEntityManagerFactory静态方法,根据配置文件中持久化单元名称创建EntityManagerFactory。
//1.加载配置文件创建(实体管理器)工厂对象
EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJpa");
5.2 EntityManagerFactory
EntityManagerFactory 接口主要用来创建 EntityManager 实例
//创建实体管理类
EntityManager em = factory.createEntityManager();
由于EntityManagerFactory 是一个线程安全的对象(即多个线程访问同一个EntityManagerFactory 对象不会有线程安全问题),并且EntityManagerFactory 的创建极其浪费资源,所以在使用JPA编程时,我们可以对EntityManagerFactory 的创建进行优化,只需要做到一个工程只存在一个EntityManagerFactory 即可。
5.3 EntityManager
我们可以通过调用EntityManager的方法完成获取事务,以及持久化数据库的操作
方法说明:
- getTransaction : 获取事务对象
- persist : 保存操作
- merge : 更新操作
- remove : 删除操作
- find/getReference : 根据id查询
5.4 EntityTransaction
在 JPA 规范中, EntityTransaction是完成事务操作的核心对象,对于EntityTransaction在我们的java代码中承接的功能比较简单。
- begin:开启事务
- commit:提交事务
- rollback:回滚事务
jpa操作的操作步骤
1.加载配置文件创建实体管理器工厂
Persisitence:静态方法(根据持久化单元名称创建实体管理器工厂)
createEntityMnagerFactory(持久化单元名称)
作用:创建实体管理器工厂 2.根据实体管理器工厂,创建实体管理器
EntityManagerFactory :获取EntityManager对象
方法:createEntityManager
* 内部维护的很多的内容
内部维护了数据库信息,
维护了缓存信息
维护了所有的实体管理器对象
再创建EntityManagerFactory的过程中会根据配置创建数据库表
* EntityManagerFactory的创建过程比较浪费资源
特点:线程安全的对象
多个线程访问同一个EntityManagerFactory不会有线程安全问题
* 如何解决EntityManagerFactory的创建过程浪费资源(耗时)的问题?
思路:创建一个公共的EntityManagerFactory的对象
* 静态代码块的形式创建EntityManagerFactory 3.创建事务对象,开启事务
EntityManager对象:实体类管理器
beginTransaction : 创建事务对象
presist : 保存
merge : 更新
remove : 删除
find/getRefrence : 根据id查询 Transaction 对象 : 事务
begin:开启事务
commit:提交事务
rollback:回滚
4.增删改查操作
5.提交事务
6.释放资源
20-抽取jpaUtils工具类
package cn.bjut.utils; import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence; /**
* 解决实体管理器工厂的浪费资源和耗时问题
* 通过静态代码块的形式,当程序第一次访问此工具类时,创建一个公共的实体管理器工厂对象
*
* 第一次访问getEntityManager方法:经过静态代码块创建一个factory对象,再调用方法创建一个EntityManager对象
* 第二次方法getEntityManager方法:直接通过一个已经创建好的factory对象,创建EntityManager对象
*/
public class JpaUtils { private static EntityManagerFactory factory; static {
//1.加载配置文件,创建entityManagerFactory
factory = Persistence.createEntityManagerFactory("myJpa");
} /**
* 获取EntityManager对象
*/
public static EntityManager getEntityManager() {
return factory.createEntityManager();
}
}
测试工具类的使用
@Test
public void testSave_utils() {
//1.加载配置文件创建(实体管理器)工厂对象
//EntityManagerFactory factory = Persistence.createEntityManagerFactory("myJpa");
//2.通过实体管理器工厂获取实体管理器
//EntityManager entityManager = factory.createEntityManager(); EntityManager entityManager = JpaUtils.getEntityManager();
//3.获取事务对象,开启事务
EntityTransaction tx = entityManager.getTransaction();//获取事务对象
tx.begin(); //开启事务
//4.完成增删改查操作:保存一个客户到数据库中
Customer customer = new Customer();
customer.setCustName("Kang2");
customer.setCustIndustry("Java后端开发2");
//保存操作
entityManager.persist(customer);
//5.提交事务
tx.commit();
//6.释放资源
entityManager.close();
//factory.close(); }
22-find方法:根据id查询客户
/**
* 根据id查询客户
* 使用find方法查询:
* 1.查询的对象就是当前客户对象本身
* 2.在调用find方法的时候,就会发送sql语句查询数据库
*
* 立即加载
*
*/
@Test
public void testFind() {
//1.通过工具类获取entityManager
EntityManager entityManager = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//3.增删改查 -- 根据id查询客户
/**
* find : 根据id查询数据
* class:查询数据的结果需要包装的实体类类型的字节码
* id:查询的主键的取值
*/
Customer customer = entityManager.find(Customer.class, 2l);
System.out.print(customer);
//4.提交事务
tx.commit();
//5.释放资源
entityManager.close();
}
23-延迟加载与立即加载
/**
* 根据id查询客户
* getReference方法
* 1.获取的对象是一个动态代理对象
* 2.调用getReference方法不会立即发送sql语句查询数据库
* * 当调用查询结果对象的时候,才会发送查询的sql语句:什么时候用,什么时候发送sql语句查询数据库
*
* 延迟加载(懒加载)
* * 得到的是一个动态代理对象
* * 什么时候用,什么使用才会查询
*/
@Test
public void testReference() {
//1.通过工具类获取entityManager
EntityManager entityManager = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//3.增删改查 -- 根据id查询客户
/**
* getReference : 根据id查询数据
* class:查询数据的结果需要包装的实体类类型的字节码
* id:查询的主键的取值
*/
Customer customer = entityManager.getReference(Customer.class, 1l);
System.out.print(customer);
//4.提交事务
tx.commit();
//5.释放资源
entityManager.close();
}
24-根据id删除客户
/**
* 删除客户的案例
*
*/
@Test
public void testRemove() {
//1.通过工具类获取entityManager
EntityManager entityManager = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//3.增删改查 -- 删除客户 //i 根据id查询客户
Customer customer = entityManager.find(Customer.class,1l);
//ii 调用remove方法完成删除操作
entityManager.remove(customer); //4.提交事务
tx.commit();
//5.释放资源
entityManager.close();
}
25-客户的更新操作
/**
* 更新客户的操作
* merge(Object)
*/
@Test
public void testUpdate() {
//1.通过工具类获取entityManager
EntityManager entityManager = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = entityManager.getTransaction();
tx.begin();
//3.增删改查 -- 更新操作 //i 查询客户
Customer customer = entityManager.find(Customer.class,1l);
//ii 更新客户
customer.setCustIndustry("it教育");
entityManager.merge(customer); //4.提交事务
tx.commit();
//5.释放资源
entityManager.close();
}
以上部分有关Jpa的小结:
ii.完成基本CRUD案例
persist : 保存
merge : 更新
remove : 删除
find/getRefrence : 根据id查询
05.JPQL查询
iii.jpql查询
sql:查询的是表和表中的字段
jpql:查询的是实体类和类中的属性
* jpql和sql语句的语法相似 .查询全部
.分页查询
.统计查询
.条件查询
.排序
27-jpql查询:查询全部
/**
* 测试jqpl查询
*/
public class JpqlTest { /**
* 查询全部
* jqpl:from cn.bjut.domain.Customer
* sql:SELECT * FROM cst_customer
*/
@Test
public void testFindAll() {
//1.获取entityManager对象
EntityManager em = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.查询全部
String jpql = "from cn.bjut.domain.Customer ";
Query query = em.createQuery(jpql);//创建Query查询对象,query对象才是执行jqpl的对象 //发送查询,并封装结果集
List list = query.getResultList(); for (Object obj : list) {
System.out.print(obj);
} //4.提交事务
tx.commit();
//5.释放资源
em.close();
} }
28-jpql查询:倒序
/**
* 排序查询: 倒序查询全部客户(根据id倒序)
* sql:SELECT * FROM cst_customer ORDER BY cust_id DESC
* jpql:from Customer order by custId desc
*
* 进行jpql查询
* 1.创建query查询对象
* 2.对参数进行赋值
* 3.查询,并得到返回结果
*/
@Test
public void testOrders() {
//1.获取entityManager对象
EntityManager em = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.查询全部
String jpql = "from Customer order by custId desc";
Query query = em.createQuery(jpql);//创建Query查询对象,query对象才是执行jqpl的对象 //发送查询,并封装结果集
List list = query.getResultList(); for (Object obj : list) {
System.out.println(obj);
} //4.提交事务
tx.commit();
//5.释放资源
em.close();
}
29-jpql查询:统计查询
/**
* 使用jpql查询,统计客户的总数
* sql:SELECT COUNT(cust_id) FROM cst_customer
* jpql:select count(custId) from Customer
*/
@Test
public void testCount() {
//1.获取entityManager对象
EntityManager em = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.查询全部
//i.根据jpql语句创建Query查询对象
String jpql = "select count(custId) from Customer";
Query query = em.createQuery(jpql);
//ii.对参数赋值
//iii.发送查询,并封装结果 /**
* getResultList : 直接将查询结果封装为list集合
* getSingleResult : 得到唯一的结果集
*/
Object result = query.getSingleResult(); System.out.println(result); //4.提交事务
tx.commit();
//5.释放资源
em.close();
}
30-jpql查询:分页查询
/**
* 分页查询
* sql:select * from cst_customer limit 0,2
* jqpl : from Customer
*/
@Test
public void testPaged() {
//1.获取entityManager对象
EntityManager em = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.查询全部
//i.根据jpql语句创建Query查询对象
String jpql = "from Customer";
Query query = em.createQuery(jpql);
//ii.对参数赋值 -- 分页参数
//起始索引
query.setFirstResult(0);
//每页查询的条数
query.setMaxResults(2); //iii.发送查询,并封装结果 /**
* getResultList : 直接将查询结果封装为list集合
* getSingleResult : 得到唯一的结果集
*/
List list = query.getResultList(); for(Object obj : list) {
System.out.println(obj);
} //4.提交事务
tx.commit();
//5.释放资源
em.close();
}
31-jpql查询:条件查询
/**
* 条件查询
* 案例:查询客户名称以‘传智播客’开头的客户
* sql:SELECT * FROM cst_customer WHERE cust_name LIKE ?
* jpql : from Customer where custName like ?
*/
@Test
public void testCondition() {
//1.获取entityManager对象
EntityManager em = JpaUtils.getEntityManager();
//2.开启事务
EntityTransaction tx = em.getTransaction();
tx.begin();
//3.查询全部
//i.根据jpql语句创建Query查询对象
String jpql = "from Customer where custName like ? ";
Query query = em.createQuery(jpql);
//ii.对参数赋值 -- 占位符参数
//第一个参数:占位符的索引位置(从1开始),第二个参数:取值
query.setParameter(1,"传智播客%"); //iii.发送查询,并封装结果 /**
* getResultList : 直接将查询结果封装为list集合
* getSingleResult : 得到唯一的结果集
*/
List list = query.getResultList(); for(Object obj : list) {
System.out.println(obj);
} //4.提交事务
tx.commit();
//5.释放资源
em.close();
}
=================
end
12 Spring Data JPA:orm思想和hibernate以及jpa的概述和jpa的基本操作的更多相关文章
- 12 Spring Data JPA:springDataJpa的运行原理以及基本操作(上)
spring data jpaday1:orm思想和hibernate以及jpa的概述和jpa的基本操作 day2:springdatajpa的运行原理 day2:springdatajpa的基本操作 ...
- 12 Spring Data JPA:springDataJpa的运行原理以及基本操作(下)
spring data jpaday1:orm思想和hibernate以及jpa的概述和jpa的基本操作 day2:springdatajpa的运行原理 day2:springdatajpa的基本操作 ...
- spring data jpa、 hibernate、 jpa 三者之间的关系
http://www.cnblogs.com/xiaoheike/p/5150553.html JPA规范与ORM框架之间的关系是怎样的呢? JPA规范本质上就是一种ORM规范,注意不是ORM框架-- ...
- 转:使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- 使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- Spring Data JPA 大纲归纳
第一天: springdatajpa day1:orm思想和hibernate以及jpa的概述和jpa的基本操作 day2:springdatajpa的运行原理以及基本操作 day3:多表操作,复杂查 ...
- spring data jpa(一)
第1章 Spring Data JPA的快速入门 1.1 需求说明 Spring Data JPA完成客户的基本CRUD操作 1.2 搭建Spring Data JPA的开发环境 1. ...
- 16 搭建Spring Data JPA的开发环境
使用Spring Data JPA,需要整合Spring与Spring Data JPA,并且需要提供JPA的服务提供者hibernate,所以需要导入spring相关坐标,hibernate坐标,数 ...
- hibernate、mybatis、spring data 的对比
转: 1.概念: Hibernate :Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库.着力 ...
随机推荐
- 071-PHP数组合并
<?php $arr1=array('a','b','c'); //定义一个数组 echo '数组$arr1的信息:<br />'; print_r($arr1); //输出数组信息 ...
- 使用WebClient下载文件到本地目录
利用WebClient实现下载文件 调用 string url = "https://timgsa.baidu.com/timg?image&quality=80&size= ...
- spring源码 ListableBeanFactory接口
ListableBeanFactory接口表示这些Bean是可列表的 /* * Copyright 2002-2016 the original author or authors. * * Lice ...
- hdu 1160 上升序列 dp
FatMouse's Speed Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
- 第七篇:Python3连接MySQL
第七篇:Python3连接MySQL 连接数据库 注意事项 在进行本文以下内容之前需要注意: 你有一个MySQL数据库,并且已经启动. 你有可以连接该数据库的用户名和密码 你有一个有权限操作的data ...
- UVA - 1612 Guess (猜名次)(贪心)
题意:有n(n<=16384)位选手参加编程比赛.比赛有3道题目,每个选手的每道题目都有一个评测之前的预得分(这个分数和选手提交程序的时间相关,提交得越早,预得分越大).接下来是系统测试.如果某 ...
- mac安装vue没有使用权限不足
➜ ~ vue init webpack frontend ⠋ downloading template /usr/local/lib/node_modules/vue-cli/node_modul ...
- sql同时删除多个表的数据
DELETE语句中指定多个表,根据多个表中的特定条件,从一个表或多个表中删除行. 不过,您不能在一个多表DELETE语句中使用ORDER BY或LIMIT. DELETE t1, t2 FROM t1 ...
- arm 裸机学习笔记
位置无关码 bl 是位置无关码,指令中带的数值是,编译的时候,编译器计算好的,需要跳转的位置减去 bl 指令所在位置的结果.这样当程序最开始在 4k sram 中运行的时候,跳转的位置是在 0 + o ...
- 实验吧web-易-上传绕过
随便上传一个png文件,出现提示 我们再上传一个php文件,却出现提示 上传遇到问题是肯定的,题目就是上传绕过,所以我们下面要做的就是绕过检测. 这里使用00截断. 首先在提交时抓包 我们将图中upl ...