python掉包侠与深浅拷贝
今日所得
包
logging模块
hashlib模块
openpyxl模块
深浅拷贝
包
在学习模块的时候我们了解过模块的四种表现形式,其中的一种就是包。
什么是包?
它是一系列模块文件的结合体,表示形式就是一个文件夹,该文件夹的内部通常会有一个__init__.py文件,而包的本质其实还是一个模块。
首次导入包的步骤:
先产生一个执行文件的名称空间
1.创建包下面的__init__.py文件的名称空间
2.执行包下面的__init__.py文件中的代码,将产生的名字放入包下面的__init__.py文件名称空间中
3.在执行文件中拿到一个指向包下面的__init__.py文件名称空间的名字
在导入语句中 .号的左边肯定是一个包(文件夹)
#当你作为包的设计者来说
1.当模块的功能特别多的情况下 应该分文件管理
2.每个模块之间为了避免后期模块改名的问题 你可以使用相对导入(包里面的文件都应该是#被导入的模块) #站在包的开发者 如果使用绝对路径来管理的自己的模块 那么它只需要永远以包的路径为基准依次导入模块
#站在包的使用者 你必须得将包所在的那个文件夹路径添加到system path中(******)
python2如果要导入包 包下面必须要有__init__.py文件
python3如果要导入包 包下面没有__init__.py文件也不会报错
当你在删程序不必要的文件的时候 千万不要随意删除__init__.py文件
logging模块
日志模块,日志模块中有五个等级和四个对象
#5个等级
logging.debug('debug日志') #
logging.info('info日志') #
logging.warning('warning日志') #
logging.error('error日志') #
logging.critical('critical日志') #
#四个对象
#1.logger对象:负责产生日志
#2.filter对象 : 过滤日志(了解)
#3.handler对象:控制日志输出的位置(文件/终端)
#4.formmater对象:规定日志内容的格式
#日志的配置
"""
下面的两个变量对应的值 需要你手动修改
"""
logfile_dir = os.path.dirname(__file__) # log文件的目录
logfile_name = 'a3.log' # log文件名 # 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir) # log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name)
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 默认都会使用该k:v配置
},
} # 使用日志字典配置
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger('asajdjdskaj')
logger1.debug('好好的 不要浮躁 努力就有收获')
hashlib模块
#hashlib模块(加密模块)
import hashlib # 这个加密的过程是无法解密的
md = hashlib.md5() # 生成一个帮你造密文的对象
md.update('hello'.encode('utf-8')) # 往对象里传明文数据 update只能接受bytes类型的数据
md.update(b'morning') # 往对象里传明文数据 update只能接受bytes类型的数据
print(md.hexdigest()) # 获取明文数据对应的密文
除了我们常用的md5外,还有一些其他的算法,但是对于不同的算法,使用方法是相同的,密文的长度越长,内部对应的算法越复杂。但是密文太长也有两个缺点,一是时间消耗越长,二是占用空间更大,所以通常情况下使用md5就足够了。
md = hashlib.md5()
#md.update(b'are') # 传入的内容 可以分多次传入 只要传入的内容相同 那么生成的密文肯定相同
md.update(b'a')
md.update(b'r')
md.update(b'e')
print(md.hexdigest())
"""
hashlib模块应用场景
1.密码的密文存储
2.校验文件内容是否一致
"""
#加盐处理
# 公司自己在每一个需要加密的数据之前 先手动添加一些内容
import hashlib
md = hashlib.md5()
md.update(b'oldboy.com') # 加盐处理
md.update(b'hello') # 真正的内容
print(md.hexdigest()) #动态加盐
import hashlib
def get_md5(data):
md = hashlib.md5()
md.update('加盐'.encode('utf-8'))
md.update(data.encode('utf-8'))
return md.hexdigest() password = input('password>>>:')
res = get_md5(password)
print(res)
openpyxl模块
openpyxl比较火的操作excel表格的模块
03版本之前 excel文件的后缀名 叫xls
03版本之后 excel文件的后缀名 叫xlsx
其它操作excel的模块:
xlwd 写excel xlrt读excel
xlwd和xlrt既支持03版本之前的excel文件,也支持03版本之后的excel文件
openpyxl 只支持03版本之后的 xlsx
from openpyxl import Workbook wb = Workbook() # 先生成一个工作簿
wb1 = wb.create_sheet('index',0) # 创建一个表单页 后面可以通过数字控制位置
wb2 = wb.create_sheet('index1')
wb1.title ='login' # 后期可以通过表单页对象点title修改表单页名称 wb1['A3'] = 666 # 在列表中A3的位置添加数字
wb1['A4'] = 444
wb1.cell(row=6,column=3,value=8888) # 在列表的第6行第3列添加值8888
wb1['A5'] = '=sum(A3:A4)' # 将列表的A3和A4位置进行加法运算,输出结果到A5上 wb.save('test.xlsx') # 保存新建的excel文件,要注意保存之前要确认文件是否关闭,未关闭会报错。
from openpyxl import load_workbook # 读文件
wb = load_workbook('test.xlsx',read_only=True,data_only=True)
print(wb)
print(wb.sheetnames) # ['login', 'Sheet', 'index1']
print(wb['login']['A3'].value) # 读出文件中login里A3处的值
深浅拷贝
l1 = [1,2,3,[4,5,6]]
l2 = l1
print(id(l1),id(l2)) # 值拷贝
#浅拷贝
import copy
l1 = [1,2,3,[4,5,6]]
l2 = copy.copy(l1)
print(l1,l2) # 值相同
print(id(l1),id(l2)) # 地址不同
l1[0]=0
print(l1,l2) # l1=[0, 2, 3, [4, 5, 6]],l2=[1, 2, 3, [4, 5, 6]]
l1[3].append(7)
print(l1,l2) # l1=[0, 2, 3, [4, 5, 6, 7]],l2=[1, 2, 3, [4, 5, 6, 7]]
浅拷贝图示
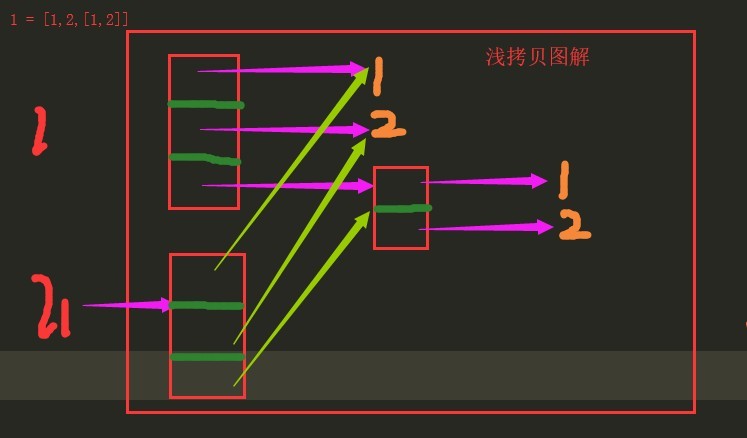
对于浅拷贝来说,只是在内存中重新创建了开辟了一个空间存放一个新列表,但是新列表中的元素与原列表中的元素是公用的,当原列表中存放的是可变类型,浅拷贝指向的是原可变类型,所以当原列表中可变类型中的元素发生变化,浅拷贝的也会跟着一起变。
#深拷贝
l2 = copy.deepcopy(l1)
l1[3].append(7)
print(l1,l2) # l1 = [1, 2, 3, [4, 5, 6, 7]],l2=[1, 2, 3, [4, 5, 6]]
深拷贝图示
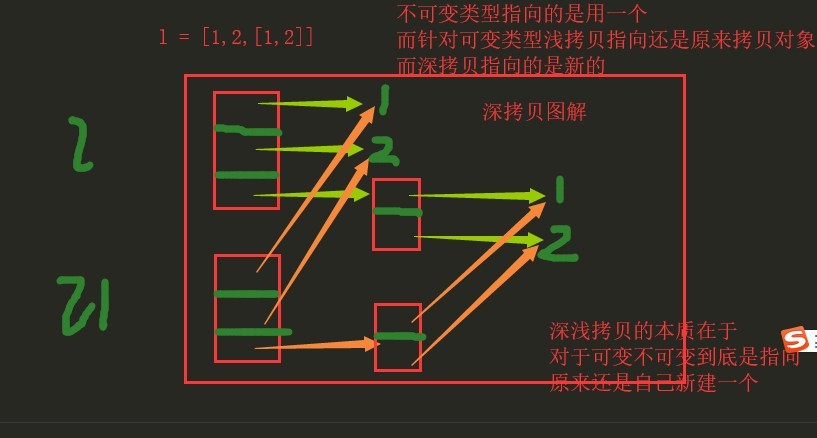
对于深copy来说,列表是在内存中重新创建的,列表中可变的数据类型是重新创建的,列表中的不可变的数据类型是公用的。
总结:深浅拷贝中,不可变的数据类型都是公用的,但在浅拷贝只是指向可变数据类型,而深拷贝则是完全新建一个。
python掉包侠与深浅拷贝的更多相关文章
- python学习笔记:深浅拷贝的使用和原理
在理解深浅拷贝之前,我们先熟悉下变量对象和数据类型 1.变量和对象 变量-引用-对象(可变对象,不可变对象) 在python中一切都是对象,比如[1,2],'hello world',123,{'k1 ...
- python之路(三)-深浅拷贝
深浅拷贝用法来自copy模块. 导入模块:import copy 浅拷贝:copy.copy 深拷贝:deepcopy 字面理解:浅拷贝指仅仅拷贝数据集合的第一层数据,深拷贝指拷贝数据集合的所有层.所 ...
- python变量存储和深浅拷贝
python的变量及其存储 在高级语言中,变量是对内存及其地址的抽象.对于python而言,python的一切变量都是对象,变量的存储,采用了引用语义的方式,存储的只是一个变量的值所在的内存地址,而不 ...
- python内存相关以及深浅拷贝讲解
3.9 内存相关 3.9.1 id,查看内存地址 >>> v1 = [11,22,33] >>> v2 = [11,22,33] >>> prin ...
- Python collection模块与深浅拷贝
collection模块是对Python的通用内置容器:字典.列表.元组和集合的扩展,它包含一些专业的容器数据类型: Counter(计数器):dict子类,用于计算可哈希性对象的个数. Ordere ...
- Python基础入门知识点——深浅拷贝
深浅拷贝 对象引用.浅拷贝.深拷贝(拓展.难点.重点) Python中,对象的赋值,拷贝(深/浅拷贝)之间是有差异的,如果使用的时候不注意,就可能产生意外的结果 其实这个是由于共享内存导致的结果 拷贝 ...
- 从零开始的Python学习Episode 8——深浅拷贝
深浅拷贝 一.浅拷贝 列表中存储的是数据的内存地址,当我们要查询或修改列表中的数据时,我们是通过列表中的地址找到要访问的内存.当我们修改列表中的数据时,如果修改的是一个不可变类型(整型,长整型,浮点数 ...
- python set集合 以及 深浅拷贝
set集合 特点: 无序, 不重复, 元素必须可哈希(不可变) 作用: 去重复 本身是可变的数据类型. 有增删改查操作. frozenset()冻结的集合. 不可变的. 可hash的 深浅拷贝() 1 ...
- python神坑系列之深浅拷贝
深浅拷贝 1.注意在拷贝中只有使用了.deepcopy方法才能进行深度拷贝!其余的一律是浅拷贝 #深拷贝import copy lst = copy.deepcopy(lst1) 浅拷贝: 拷贝的是 ...
随机推荐
- 3D打印前途光明,它需要怎样的进化?
在很长一段时间内,笔者都认为3D打印只会存在于科幻场景内,众多的科技大佬在前几年也和我保持相当一致的看法,代工大王郭台铭曾口出狂言:如果3D打印能够普及,我就把"郭"字倒过来写,时 ...
- Mac系统的SVN客户端:Snail SVN 精简版
Mac系统的SVN客户端:Snail SVN 精简版 前言 本人在公司中,使用的是windows操作系统,svn客户端自然也就使用tortoise svn.但自从男朋友给我买了台macbook pro ...
- zookeeper以及集群的搭建
今天我来写一写zookeeper集群的搭建流程 1.zookeeper的搭建不难,难的是对他的理解以及良好的使用.单机版的zookeeper只需要解压后直接命令 启动即可 解压zookeeper,ta ...
- ruoyi BeanUtils
package com.ruoyi.common.utils.bean; import java.lang.reflect.Method; import java.util.ArrayList; im ...
- PAT Basic 插⼊与归并(25) [two pointers]
题目 根据维基百科的定义: 插⼊排序是迭代算法,逐⼀获得输⼊数据,逐步产⽣有序的输出序列.每步迭代中,算法从输⼊序列中取出⼀元素,将之插⼊有序序列中正确的位置.如此迭代直到全部元素有序.归并排序进⾏如 ...
- 数据分析-Matplotlib:绘图和可视化
学习路线 简介 简单绘制线形图 plot函数 支持图类型 保存图表 1.简介 Matplotlib是一个强大的Python绘图和数据可视化的工具包.数据可视化也是我们数据分析的最重要的工作之一,可以帮 ...
- Spring--Spring 注入
Spring 提供了三种主要的装配机制: 在 XML 中进行显式配置 在 Java 中进行显式配置 隐式的 bean 发现机制和自动装配 Spring 从两个角度来实现自动化装配: 组件扫描:Spri ...
- HTTP协议解析小白文
1. 什么是HTTP协议? HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本 ...
- 题解-------[ZJOI2009]对称的正方形
传送门 题目大意 找到所有的上下左右都相同的正方形. 思路:二分+二维Hash 这道题我们首先想到不能暴力判断一个正方形是否合法. 然后我们发现当一个正方形合法时,以这个正方形为中心且比它小的正方形也 ...
- 2019深圳Android千人开发者大会【NEW·无界】
报名地址:https://www.hdb.com/dis/mjcsegnslu 安卓巴士技术社区是中国领先的安卓开发者社区,现已聚集超过85万开发者,数年来一直致力于IT从业者的知识分享服务. 安卓巴 ...