Hive(10)-文件存储格式
Hive支持的存储数据的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET
一. 列式存储和行式存储
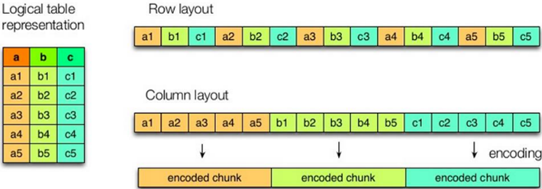
左边为逻辑表,右边第一个为行式存储,第二个为列式存储
1. 行式存储的特点
查询满足条件的一整行数据的时候,列存储则需要去每个聚集的字段找到对应的每个列的值,行存储只需要找到其中一个值,其余的值都在相邻地方,所以此时行存储查询的速度更快。
2.列式存储的特点
因为每个字段的数据聚集存储,在查询只需要少数几个字段的时候,能大大减少读取的数据量;每个字段的数据类型一定是相同的,列式存储可以针对性的设计更好的设计压缩算法。
TEXTFILE和SEQUENCEFILE的存储格式都是基于行存储的;
ORC和PARQUET是基于列式存储的。
二. TextFile格式
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用,但使用Gzip这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
三. Orc格式
Orc (Optimized Row Columnar)是Hive 0.11版里引入的新的存储格式。
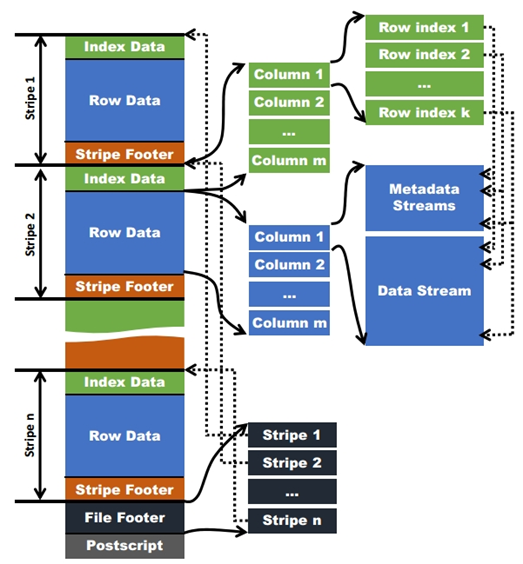
每个Orc文件由1个或多个stripe组成,每个stripe一般为HDFS的块大小,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer.
1)Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset。
2)Row Data:存的是具体的数据,先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个Stream来存储。
3)Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
四. Parquet格式
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。
1) 行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
2) 列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
3) 页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。
通常情况下,在存储Parquet数据的时候会按照Block大小设置行组的大小,由于一般情况下每一个Mapper任务处理数据的最小单位是一个Block,这样可以把每一个行组由一个Mapper任务处理,增大任务执行并行度。
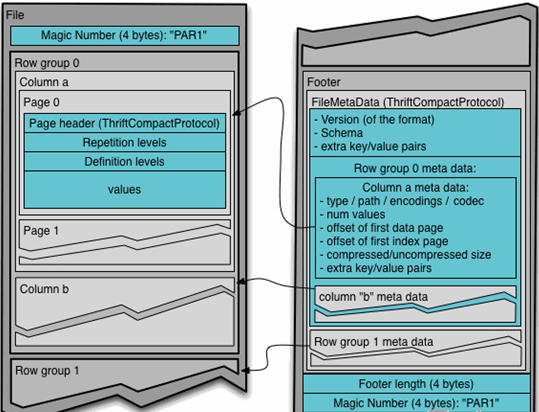
一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length记录了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和该文件存储数据的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据,在Parquet中,有三种类型的页:数据页、字典页和索引页。数据页用于存储当前行组中该列的值,字典页存储该列值的编码字典,每一个列块中最多包含一个字典页,索引页用来存储当前行组下该列的索引,目前Parquet中还不支持索引页。
Hive(10)-文件存储格式的更多相关文章
- 大数据:Hive - ORC 文件存储格式
一.ORC File文件结构 ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache ...
- Hive - ORC 文件存储格式【转】
一.ORC File文件结构 ORC的全称是(Optimized Row Columnar),ORC文件格式是一种Hadoop生态圈中的列式存储格式,它的产生早在2013年初,最初产生自Apache ...
- 【图解】Hive文件存储格式
摘自:https://blog.csdn.net/xueyao0201/article/details/79103973 引申阅读原理篇: 大数据:Hive - ORC 文件存储格式 大数据:Parq ...
- hive常见的存储格式
Hive常见文件存储格式 背景:列式存储和行式存储 首先来看一下一张表的存储格式: 字段A 字段B 字段C A1 B1 C1 A2 B2 C2 A3 B3 C3 A4 B4 C4 A5 B5 C5 行 ...
- Hive文件存储格式
hive文件存储格式 1.textfile textfile为默认格式 存储方式:行存储 磁盘开销大 数据解析开销大 压缩的text文件 hive无法进行合并和拆分 2.sequencef ...
- Hive文件存储格式和hive数据压缩
一.存储格式行存储和列存储 二.Hive文件存储格式 三.创建语句和压缩 一.存储格式行存储和列存储 行存储可以理解为一条记录存储一行,通过条件能够查询一整行数据. 列存储,以字段聚集存储,可以理解为 ...
- Hive性能调优(一)----文件存储格式及压缩方式选择
合理使用文件存储格式 建表时,尽量使用 orc.parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量. 采用合 ...
- hive从入门到放弃(六)——常用文件存储格式
hive 存储格式有很多,但常用的一般是 TextFile.ORC.Parquet 格式,在我们单位最多的也是这三种 hive 默认的文件存储格式是 TextFile. 除 TextFile 外的其他 ...
- Hive-ORC文件存储格式
ORC文件格式是从Hive-0.11版本开始的.关于ORC文件格式的官方文档,以及基于官方文档的翻译内容这里就不赘述了,有兴趣的可以仔细研究了解一下.本文接下来根据论文<Major Techni ...
随机推荐
- Jmeter————监控服务器性能
1. 下载jmeter插件 上面2个是jmeter插件,第3个要放在监控的服务器中. 2. 解压压缩包 找到解压包中的JAR文件,并拷贝到jmeter的lib/ext目录下,这里下载的1.4版本的插件 ...
- 构建微软智能云:介绍新的Azure业务转型创新技术
在我和用户的交流中发现,在任何类型和规模的组织中,每当涉及到在云中实现商业价值的最大化并取得竞争优势的时候,就会明显呈现三个趋势.首先,应用程序促进着组织更快速实现价值.同时,诸如机器学习.数据预测分 ...
- UDF/UDAF开发总结
参考文章: https://www.cnblogs.com/itxuexiwang/p/6264547.html https://www.cnblogs.com/eRrsr/p/6096989.htm ...
- Redis的数据类型及其常用命令
快速入门Redis 首先安装redis: windows下安装redis Linux下安装redis 1. 什么是redis Redis属于nosql(非关系型数据库) 关系型数据库是基于关系表的数据 ...
- GCD vs NSOperation
GCD is a lightweight way to represent units of work that are going to be executed concurrently. You ...
- eclipse git 解决冲突
1,team->synchronize workspace 2, merge tool 合并本地版本 3,add to git index 4,commit 5,push
- centos7安装docker-ce新版
先卸载系统的旧版本yum remove docker \ docker-common \ docker-selinux \ ...
- Eclipse 连接真实机器调试
一.手机开启调试模式 二.安装adb.exe 1.确信 \android-sdk-windows\tools\下有 adb.exe AdbWinApi.dll AdbWinUsbApi ...
- the longest distance of a binary tree
版权声明:欢迎查看本博客.希望对你有有所帮助 https://blog.csdn.net/cqs_2012/article/details/24880735 the longest distance ...
- 1968. [AHOI2005]约数研究【数论】
Description Input 只有一行一个整数 N(0 < N < 1000000). Output 只有一行输出,为整数M,即f(1)到f(N)的累加和. Sample Input ...