ClouderManager集群在Linux里浏览器默认是英文,在Win里浏览器是中文,怎么更改?(图文详解)
不多说,直接上干货!
问题详情
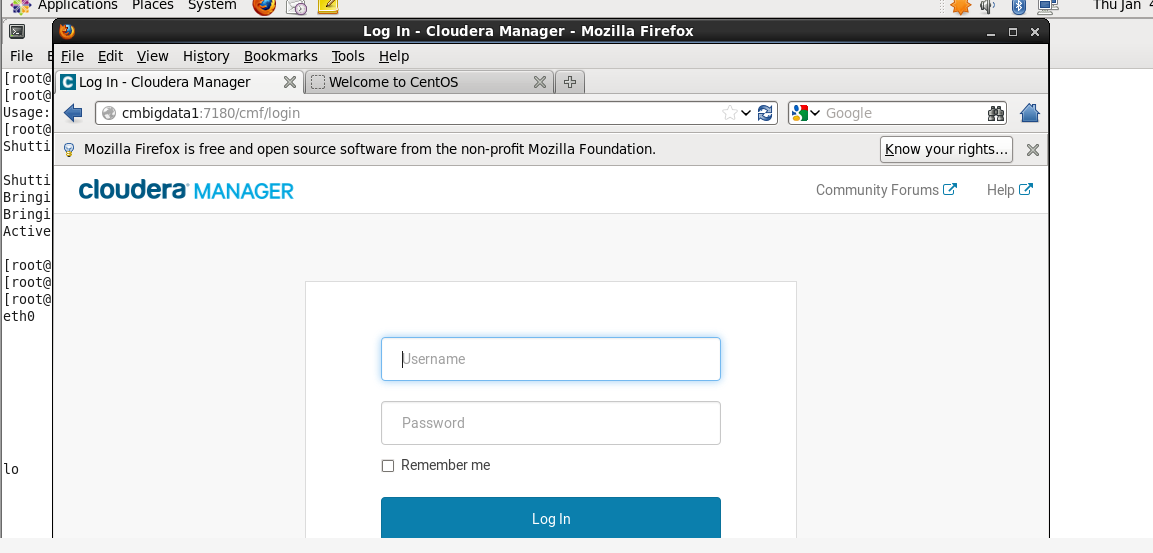
在这里面如何英文改中文的吗?
莫非要把linux的语言环境给改了??
我找找网页的语言字体怎么更改下
找到对应页面,修改成中文
解决办法


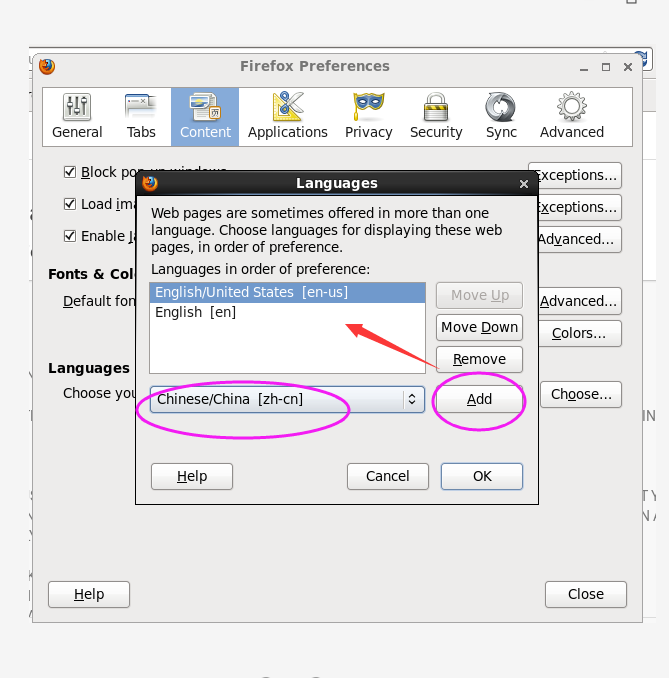
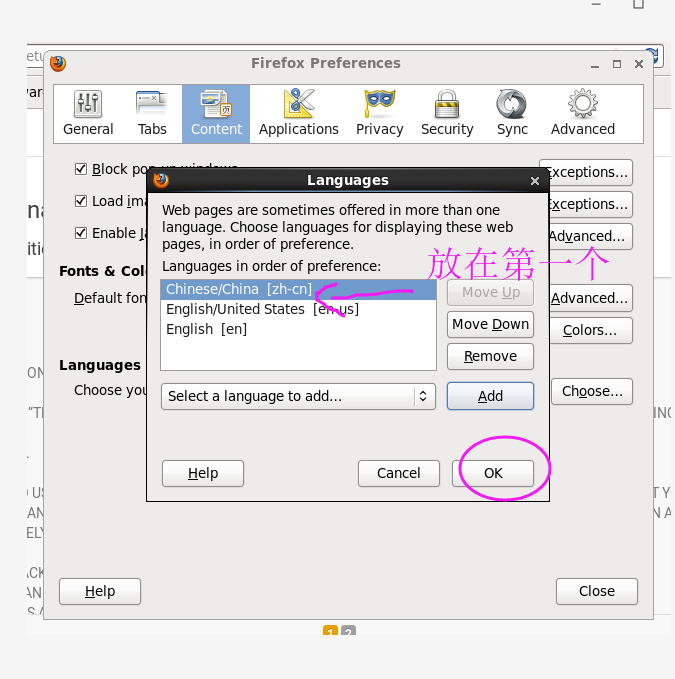
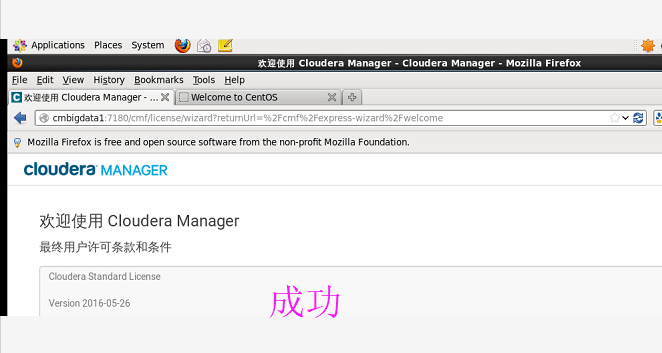
刷新下,即可
同时,大家可以关注我的个人博客:
http://www.cnblogs.com/zlslch/ 和 http://www.cnblogs.com/lchzls/ http://www.cnblogs.com/sunnyDream/
详情请见:http://www.cnblogs.com/zlslch/p/7473861.html
人生苦短,我愿分享。本公众号将秉持活到老学到老学习无休止的交流分享开源精神,汇聚于互联网和个人学习工作的精华干货知识,一切来于互联网,反馈回互联网。
目前研究领域:大数据、机器学习、深度学习、人工智能、数据挖掘、数据分析。 语言涉及:Java、Scala、Python、Shell、Linux等 。同时还涉及平常所使用的手机、电脑和互联网上的使用技巧、问题和实用软件。 只要你一直关注和呆在群里,每天必须有收获
对应本平台的讨论和答疑QQ群:大数据和人工智能躺过的坑(总群)(161156071)![]()
![]()
![]()
![]()
![]()



ClouderManager集群在Linux里浏览器默认是英文,在Win里浏览器是中文,怎么更改?(图文详解)的更多相关文章
- 全网最全的Windows下Anaconda2 / Anaconda3里正确下载安装OpenCV(离线方式和在线方式)(图文详解)
不多说,直接上干货! 说明: Anaconda2-5.0.0-Windows-x86_64.exe安装下来,默认的Python2.7 Anaconda3-4.2.0-Windows-x86_64.ex ...
- 全网最详细的Windows系统里Oracle 11g R2 Client(64bit)的下载与安装(图文详解)
不多说,直接上干货! 环境: windows10系统(64位) 最好先安装jre或jdk(此软件用来打开oracle自带的可视化操作界面,不装也没关系:可以安装plsql,或者直接用命令行操作) Or ...
- 全网最详细的大数据集群环境下如何正确安装并配置多个不同版本的Cloudera Hue(图文详解)
不多说,直接上干货! 为什么要写这么一篇博文呢? 是因为啊,对于Hue不同版本之间,其实,差异还是相对来说有点大的,具体,大家在使用的时候亲身体会就知道了,比如一些提示和界面. 全网最详细的大数据集群 ...
- 全网最详细的CentOS7里如何安装MySQL(得改为替换安装MariaDB)(图文详解)
不多说,直接上干货! 直接yum install mysql的话会报错,原因在于yum安装库里没有直接可以用的安装包,此时需要用到MariaDB了,MariaDB是MySQL社区开发的分支,也是一个增 ...
- 安装cloudermanager时出现org.spingframework.web.bind.***** host[] is not present at AnnotationMethodHandlerAdapter.java line 738 ****错误(图文详解)(博主推荐)
不多说,直接上干货! 首先,这个问题,写给需要帮助的朋友们,本人在此,搜索资料近半天,才得以解决.看过国内和国外,资料甚少.特此,写此博客,为了弥补此错误解决的资料少的缘故! 问题详解 解决办法 ...
- CentOS系统里如何正确取消或者延长屏幕保护自动锁屏功能(图文详解)
不多说,直接上干货! 对于我这里想说的是,分别从CentOS6.X 和 CentOS7.X来谈及. 1. 问题:默认启动屏幕保护 问题描述: CentOS系统在用户闲置一段时间(默认为5分钟)后, ...
- Windows里安装wireshark或者ethereal工具(包括汉化破解)(图文详解)
不多说,直接上干货! https://www.wireshark.org/download.html 我这里,读取的是,来自于https://www.ll.mit.edu/ideval/data/19 ...
- Spark Mllib里如何删除每一条数据中所有的双引号“”(图文详解)
不多说,直接上干货! 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第13章 使用决策树二元分类算法来预测分类StumbleUpon数据集
- Spark Mllib里如何将trainDara训练数据文件里第一行是字段名不是数据给删除掉(图文详解)
不多说,直接上干货! 具体,见 Hadoop+Spark大数据巨量分析与机器学习整合开发实战的第13章 使用决策树二元分类算法来预测分类StumbleUpon数据集
随机推荐
- IntelliJ IDEA 2016.1.3(64) license server 与汉化
license server:http://idea.iteblog.com/key.php 汉化:将resources_cn.jar 复制到安装IDEA安装目录下的lib文件夹中.重新打开即可. r ...
- 18-11-2 Scrum Meeting 5
1. 会议照片 2. 工作记录 - 昨天完成工作 1 把数据导入数据库 2 中译英选择题和英译中选择题的查询接口 - 今日计划工作 1 配置页面 2 实现中译英选择题和英译中选择题的查询接口 3 整理 ...
- 使用memset初始化C++自定义类型
当类型本身或者类型的成员变量带有虚函数以及像std::vector这类复杂数据结构的时候.就会出错,原因是memset把类型本身所带的一些隐含的信息也给置0了.如:虚表指针.std::vector的内 ...
- ASP.NET Core2实现静默获取微信公众号的用户OpenId
最近在做个微信公众号的项目,需要将入口放置在公众号二级菜单内,通过点击该菜单链接后进入到该项目中去,进入到项目后程序会自动通过微信公众号的API完成用户的OpenId获取.需求很简单,实现起来也不复杂 ...
- 20145233计算机病毒实践九之IDA的使用
20145233计算机病毒实践之IDA的使用 PSLIST导出函数做了什么 这个函数是一个export函数,所以在view中选择export 查到后,双击打开这个函数的位置 仔细看这个函数可以发现这个 ...
- jsp+mysql的字符过滤器
jsp+mysql项目里面,在和数据库交互的时候,总是出现乱码.这都是老生常谈的事情了. 之前在那里放了一放,今天觉得还是尽早解决.用了一个过滤器. 代码: package wang.util; im ...
- Kubernetes 自动伸缩 auto-scaling
使用 Kubernetes 的客户能够迅速响应终端用户的请求,交付软件也比以往更快.但是,当你的服务增长速度比预期更快时,计算资源不够时,该怎么处理呢? 此时可以很自豪地说: Kubernetes 1 ...
- Http 安全检测
httpsecurityreport.com www.ssllabs.com
- elasticsearch不能使用root启动问题解决
问题: es安装好之后,使用root启动会报错:can not run elasticsearch as root [root@iZbp1bb2egi7w0ueys548pZ bin]# ./elas ...
- Kafka与.net core(三)kafka操作
1.Kafka相关知识 Broker:即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为broker. Message消息:是通信的基本单位,每个 producer 可以向一个 ...