强化学习 车杆游戏 DQN 深度强化学习 Demo
网上搜寻到的代码,亲测比较好用,分享如下。
import gym
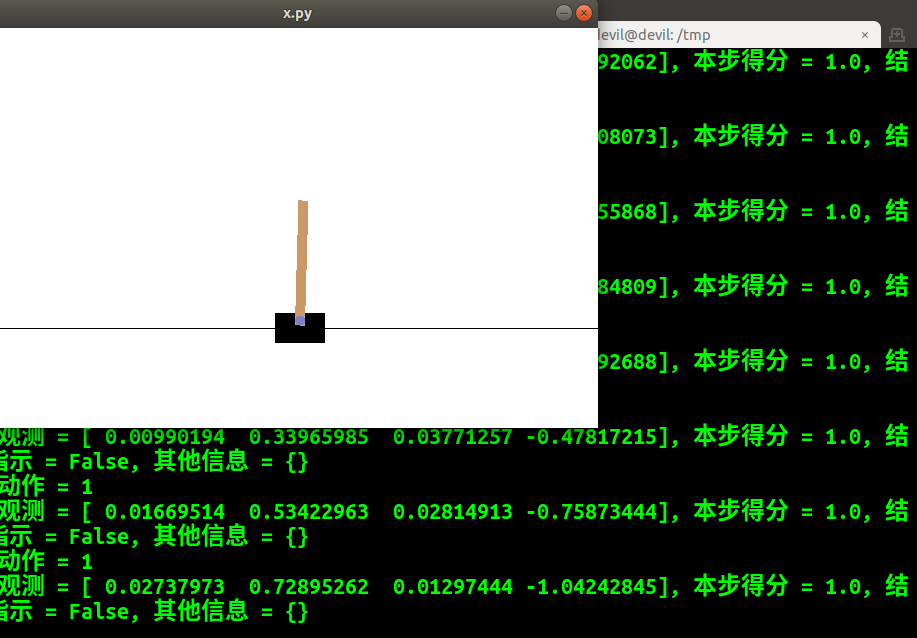
import time env = gym.make('CartPole-v0') # 获得游戏环境
observation = env.reset() # 复位游戏环境,新一局游戏开始
print ('新一局游戏 初始观测 = {}'.format(observation))
for t in range(200):
env.render()
action = env.action_space.sample() # 随机选择动作
print ('{}: 动作 = {}'.format(t, action))
observation, reward, done, info = env.step(action) # 执行行为
print ('{}: 观测 = {}, 本步得分 = {}, 结束指示 = {}, 其他信息 = {}'.format(
t, observation, reward, done, info))
if done:
break
time.sleep(1)#可加可不加,有的话就可以看到图 env.close()
以下给出多个回合的代码:
import gym
env = gym.make('CartPole-v0')
n_episode = 20
for i_episode in range(n_episode):
observation = env.reset()
episode_reward = 0
while True:
# env.render()
action = env.action_space.sample() # 随机选
observation, reward, done, _ = env.step(action)
episode_reward += reward
state = observation
if done:
break
print ('第{}局得分 = {}'.format(i_episode, episode_reward))
env.close()
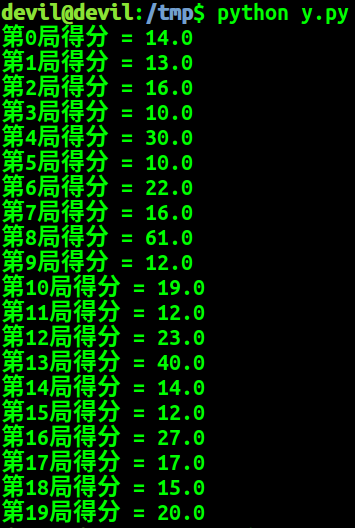
这次的多回合游戏并没有加入绘图,需要绘图的话可以将 env.render() 加入。
构建一个完整的 DQN 网络, 代码如下:
#encoding:UTF-8 #Cart Pole Environment
import gym
env = gym.make('CartPole-v0') #搭建 DQN
import torch.nn as nn
model = nn.Sequential(
nn.Linear(env.observation_space.shape[0], 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, env.action_space.n)
) import random
def act(model, state, epsilon):
if random.random() > epsilon: # 选最大的
state = torch.FloatTensor(state).unsqueeze(0)
q_value = model.forward(state)
action = q_value.max(1)[1].item()
else: # 随便选
action = random.randrange(env.action_space.n)
return action #训练
# epsilon值不断下降
import math
def calc_epsilon(t, epsilon_start=1.0,
epsilon_final=0.01, epsilon_decay=500):
epsilon = epsilon_final + (epsilon_start - epsilon_final) \
* math.exp(-1. * t / epsilon_decay)
return epsilon # 最近历史缓存
import numpy as np
from collections import deque batch_size = 32 class ReplayBuffer(object):
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity) def push(self, state, action, reward, next_state, done):
state = np.expand_dims(state, 0)
next_state = np.expand_dims(next_state, 0)
self.buffer.append((state, action, reward, next_state, done)) def sample(self, batch_size):
state, action, reward, next_state, done = zip( \
*random.sample(self.buffer, batch_size))
concat_state = np.concatenate(state)
concat_next_state = np.concatenate(next_state)
return concat_state, action, reward, concat_next_state, done def __len__(self):
return len(self.buffer) replay_buffer = ReplayBuffer(1000) import torch.optim
optimizer = torch.optim.Adam(model.parameters()) gamma = 0.99 episode_rewards = [] # 各局得分,用来判断训练是否完成
t = 0 # 训练步数,用于计算epsilon while True: # 开始新的一局
state = env.reset()
episode_reward = 0 while True:
epsilon = calc_epsilon(t)
action = act(model, state, epsilon)
next_state, reward, done, _ = env.step(action)
replay_buffer.push(state, action, reward, next_state, done) state = next_state
episode_reward += reward if len(replay_buffer) > batch_size: # 计算时间差分误差
sample_state, sample_action, sample_reward, sample_next_state, \
sample_done = replay_buffer.sample(batch_size) sample_state = torch.tensor(sample_state, dtype=torch.float32)
sample_action = torch.tensor(sample_action, dtype=torch.int64)
sample_reward = torch.tensor(sample_reward, dtype=torch.float32)
sample_next_state = torch.tensor(sample_next_state,
dtype=torch.float32)
sample_done = torch.tensor(sample_done, dtype=torch.float32) next_qs = model(sample_next_state)
next_q, _ = next_qs.max(1)
expected_q = sample_reward + gamma * next_q * (1 - sample_done) qs = model(sample_state)
q = qs.gather(1, sample_action.unsqueeze(1)).squeeze(1) td_error = expected_q - q # 计算 MSE 损失
loss = td_error.pow(2).mean() # 根据损失改进网络
optimizer.zero_grad()
loss.backward()
optimizer.step() t += 1 if done: # 本局结束
i_episode = len(episode_rewards)
print ('第{}局收益 = {}'.format(i_episode, episode_reward))
episode_rewards.append(episode_reward)
break if len(episode_rewards) > 20 and np.mean(episode_rewards[-20:]) > 195:
break # 训练结束 #使用 (固定 ϵ 的值为0)
n_episode = 20
for i_episode in range(n_episode):
observation = env.reset()
episode_reward = 0
while True:
# env.render()
action = act(model, observation, 0)
observation, reward, done, _ = env.step(action)
episode_reward += reward
state = observation
if done:
break
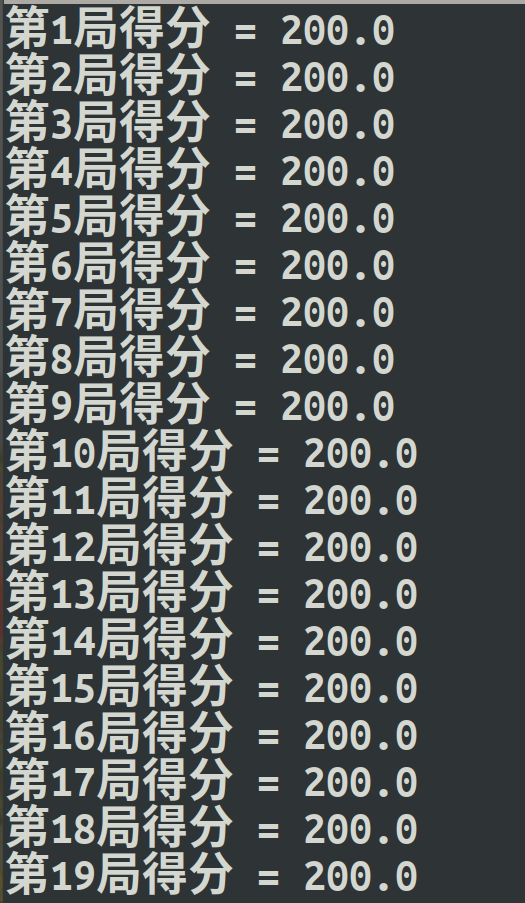
print ('第{}局得分 = {}'.format(i_episode, episode_reward))
训练过程:

测试过程:
以上代码来自:
该书阅读后个人感觉非常好,照比市面上的同类pytorch书籍相比该书虽然略显深奥,但是各方面的讲解脉络十分的清晰,在同类书籍中首推,而且全书所有代码都可以跑通,十分的难得。
强化学习 车杆游戏 DQN 深度强化学习 Demo的更多相关文章
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- 5G网络的深度强化学习:联合波束成形,功率控制和干扰协调
摘要:第五代无线通信(5G)支持大幅增加流量和数据速率,并提高语音呼叫的可靠性.在5G无线网络中共同优化波束成形,功率控制和干扰协调以增强最终用户的通信性能是一项重大挑战.在本文中,我们制定波束形成, ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 强化学习(十二) Dueling DQN
在强化学习(十一) Prioritized Replay DQN中,我们讨论了对DQN的经验回放池按权重采样来优化DQN算法的方法,本文讨论另一种优化方法,Dueling DQN.本章内容主要参考了I ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 深度强化学习——连续动作控制DDPG、NAF
一.存在的问题 DQN是一个面向离散控制的算法,即输出的动作是离散的.对应到Atari 游戏中,只需要几个离散的键盘或手柄按键进行控制. 然而在实际中,控制问题则是连续的,高维的,比如一个具有6个关节 ...
- 强化学习(3)-----DQN
看这篇https://blog.csdn.net/qq_16234613/article/details/80268564 1.DQN 原因:在普通的Q-learning中,当状态和动作空间是离散且维 ...
- 深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird
深度强化学习(DQN-Deep Q Network)之应用-Flappy Bird 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-fu ...
随机推荐
- python16_day40【数据结构】
一.链表 #!/usr/bin/env python # -*-coding:utf8-*- __author__ = "willian" # 一.简单链表 class Node( ...
- JavaScript在页面中的引用方法
现在前端开发越来越流行,框架也越来越多,像ExtJs.JQuery.Bootstrap等.虽然入行这么多年,但是感觉自己在前端方面还是存在基础不牢的地方,特别是CSS和JS.因此最近打算重新阅读这方面 ...
- net.tcp协议的wcf服务在远程计算机无法调用问题分析
可能原因1:net.tcp监听端口服务没有启动. 可能原因2:防火墙阻止了端口服务器路径访问. 可能原因3:配置文件路径endpoint路径和引用路径不一致 可能原因4:权限受限制.
- C# 使用 wkhtmltopdf 把HTML文本或文件转换为PDF
一.简介 之前也记录过一篇关于把 HTML 文本或 HTML 文件转换为 PDF 的博客,只是之前那种方法有些局限性. 后来又了解到 wkhtmltopdf.exe 这个工具,这个工具比起之前的那种方 ...
- Centos 7 无法上网的解决办法
首先,鼠标右击桌面,点击“在终端中打开”. 然后如下图所示,输入:su,按回车后输入自己的root密码:注意,输密码的时候密码区域并不显示任何东西哦,自己输错了就多按几次backspace就行 ...
- 2018 China Collegiate Programming Contest Final (CCPC-Final 2018)
Problem A. Mischievous Problem Setter 签到. #include <bits/stdc++.h> using namespace std; #defin ...
- G.Finding the Radius for an Inserted Circle 2017 ACM-ICPC 亚洲区(南宁赛区)网络赛
地址:https://nanti.jisuanke.com/t/17314 题目: Three circles C_{a}Ca, C_{b}Cb, and C_{c}Cc, all ...
- hdu5880 Family View
地址:http://acm.split.hdu.edu.cn/showproblem.php?pid=5880 题目: Family View Time Limit: 3000/1000 MS (Ja ...
- uva1351 dp
这题说的是给了 一个串 然后 比如 aaaaabbbbbbcdddd 可以化成5(a)6(b)c4(d) 这样的串明显 长度更短了 , 请 计算出使得这个串最短的 长度是多少, dp[i][j] 表示 ...
- tomcat jdbc pool
文中内容主要转自:http://www.open-open.com/lib/view/open1327478028639.html http://www.open-open.com/lib/view/ ...