Hawk 6. 高级话题:子流程系统
子流程的定义
当流程设计的越来越复杂,越来越长时,就难以进行管理了。因此,采用模块化的设计才会更加合理。本节我们介绍子流程的原理和使用。
所谓子流程,就是能先构造出一个流程,然后被其他流程调用。被调用的流程就是子流程。
学过编程和数学的人,应该能够了解子流程其实就是函数,可以定义输入参数和输出,把整个功能看成整体,从而方便重用。
子流程能够分为:
- 子流-生成
- 如生成全国城市列表的流
- 生成某个网站全部分类的流
- 子流-转换
- 通过输入url地址,就能转换出该页面中所有需要信息的流
- 子流-执行
- 例如可以构造获取某个页面所有图片的执行流
- 子流-过滤 (这一项系统没有提供,比较少用)
- 如过滤掉所有内容为空,或内容包含
abc的流
值得指出,子流还可以调用其他的子流,形成树状的调用结构。
当加载一个任务时,该任务依赖的子任务也会自动加载。对子流的修改,也会传递到主流上。
子流可以类比于一般的函数,它可以接受主流传递给它的参数,从而执行内部流程。
这样,就可以配置出本来在系统中不存在的子模块,从而扩展系统的功能。
子流在调用时,行为和系统默认提供的生成/转换/执行器完全一致。
如何创建子流
你可以将一个网页采集器认定为一个特殊的转换子流。当你创建了一个子流之后,就能按照一般的转换器,执行器来操作。
例子1
新建一个数据清洗,命名为主流程,生成1-20的区间数,列名为id.
接下来,我们希望能生成id2和id3两个列,数值分别为id的两倍和三倍,再把它们拼接起来。你可以直接拖入两个python转换器到id, 脚本为int(value)*2 和int(value)*3,最后再拖入一个合并多列,格式为{0}_{1},再删掉刚才生成的三个列,这样就生成了下面的列:
2_3
4_6
6_9
...但是,如果不仅有id这一列,还有别的列需要做一样的处理,那就需要做重复的操作了。我们完全可以将其封装起来重复使用。
新建一个数据清洗,命名为子流程,新建从文本生成,列名为id, 内容只要一个1就可以了,之后按照刚才的步骤,生成2_3这样的列。
之后,在主流程上,对id列拖入子流-转换,在弹出的面板上,ETL选择中填入子流程,调用范围填入1:100,刷新后,即可看到和之前相同的结果。
从上面可以看出,子流可以分为两部分:参数部分和执行部分。子流程中的第一个从文本生成,只是参数,目的是为了设计器能构成输出数据的完整流程。但要想被别的模块调用,则只应该有执行部分。而参数部分,需要主流程传递给子流程。这就是调用范围的意义,它能设置在子流上,成为执行部分的那一段。
举例子,如果一个长度为20个模块的子流,前两个为参数部分,后18个是执行部分,因此调用范围可以写2:18(从0开始)。 当然为了方便,你可以给冒号后第二个数比较大的值,如100。
因此,主流程应当提供子流程所需的所有参数,同时列名和子流程参数部分需要完全一致。当子流-转换模块勾选返回多个数据时,它会进入一转多模式,这类似于XPath转换器。
子流程在抓取详细页面时非常有用,你可以创建生成所有目标url的主流程,再创建从url获取页面全部信息的子流程,之后进行调用即可。
当子流是执行器时,在调试时是不会执行的,因此也看不到效果。这一点需要特别注意。
注意!
主流程不会将所有的参数都传递给子流程,因为这可能并没有必要。因此,需要在子流的转换器上,显式地设置原列名,并用空格分割,这样才能传递过去。
例子2
我们以Hawk-Project的大众点评为例讲解,可以加载工程后自行研究。之前已经讲过思路,这里我们只讲大概的轮廓:
大众点评区域能够获取一个城市所有的区县:
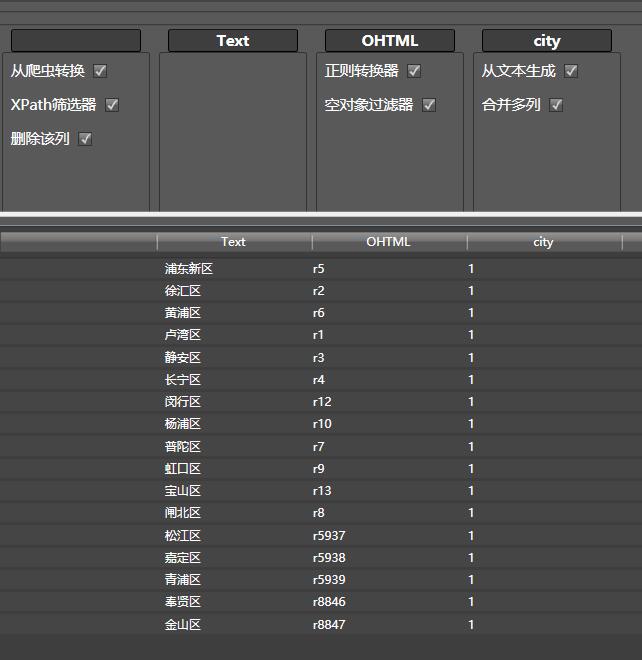
大众点评类别能够获取城市的所有美食种类。
之后,我们用大众点评门店,来调用刚才实现的两个子流:
拖入从子流-生成到大众点评门店,按照如下方式配置:
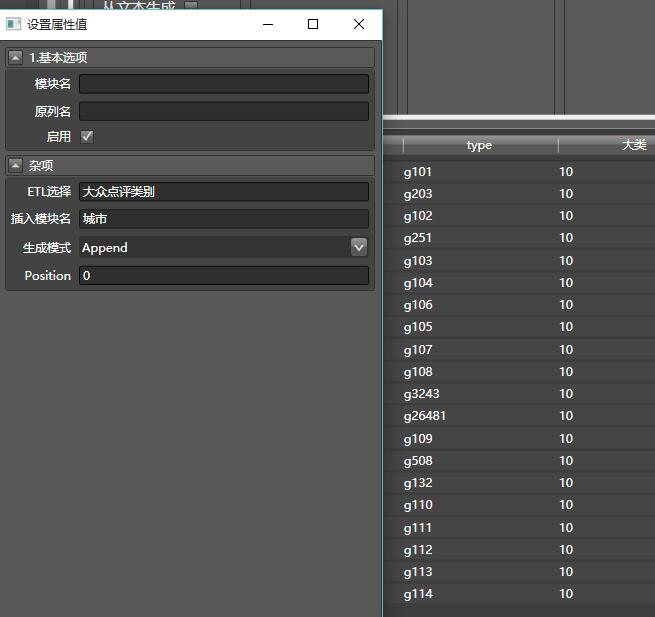
我们对必要的列名进行修改,之后再拖入另一个从子流-生成,配置如下,尤其注意生成模式改为Cross
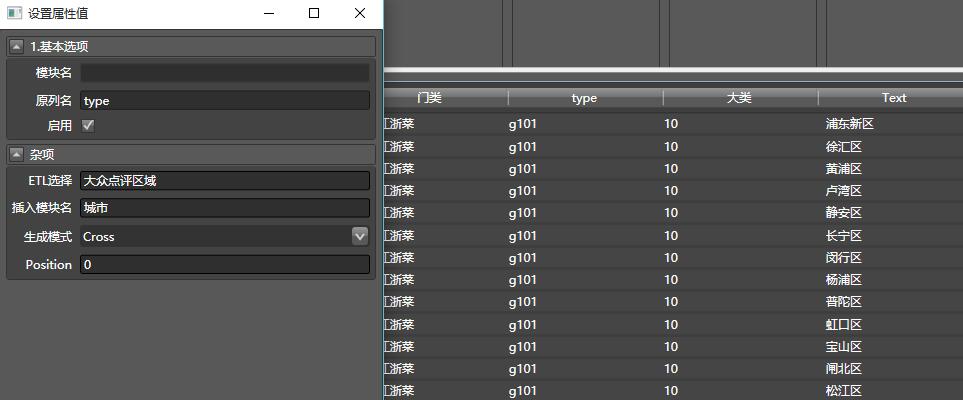
这样就能生成所有区县下,所有美食门类的组合。
之后,按照之前介绍的方式,即可抓取所有美食信息。
子流嵌套
子流程不仅可以被主流程调用,子流程还可以拥有自己的子流程。从而形成复杂的树状调用结构。这样就能实现绝大多数的需求和复杂功能。
目前,流程之间还不能自调用,也不能形成调用环。虽然函数确实是可以递归调用的,但对一个以generator为核心的流系统,递归可能并不需要。但如果真的支持,那一定会相当强大。
Hawk 6. 高级话题:子流程系统的更多相关文章
- 转:如何学习SQL(第四部分:DBMS扩展功能与SQL高级话题)
转自:http://blog.163.com/mig3719@126/blog/static/285720652010950102575/ 9. DBMS提供的扩展功能 掌握了基本的关系模型原理和DB ...
- 易普优APS与国外知名高级计划排程系统对比
众所周知软件执行效率受制于硬件性能,市面上的APS产品多为单机版本,企业要应用好APS,保证紧急插单.计划下发全程无忧,用户电脑硬件性能是不容忽视的一大瓶颈.APS的直接用户是车间管理人员.计划员,而 ...
- 易普优APS 5.0高级计划排程系统助力工业4.0智能工厂建设
(一)智能工厂建设核心 <中国制造2025>明确提出要推进制造过程智能化,智能工厂是实现智能制造的重要载体.作为智能工厂,在生产过程应实现自动化.透明化.可视化.精益化的同时,产品检测.质 ...
- C#中的线程(四)高级话题
C#中的线程(四)高级话题 Keywords:C# 线程Source:http://www.albahari.com/threading/Author: Joe AlbahariTranslato ...
- rust 高级话题
目录 rust高级话题 前言 零大小类型ZST 动态大小类型DST 正确的安装方法 结构体 复制和移动 特征对象 引用.生命周期.所有权 生命周期 错误处理 交叉编译 智能指针 闭包 动态分派和静态分 ...
- APS高级计划排程系统和生产排产系统
一.什么是APS高级计划排程系统 APS高级计划与排程是解决生产排程和生产调度问题,常被称为排序问题或资源分配问题. 目前,市场逐步走向个性化.以销定产模式:生产逐步以多品种小批量形成存在.对于离散制 ...
- 为什么众多软件厂商无法提供APS高级计划排程系统?工厂目前生产计划是怎么排产的?
一.行业现状如想了解一下目前现状,去考察一下上了ERP的企业,会发现一个有趣的现象该企业无论ERP软件搞得如何如火如荼,似乎都与生产调度人员无关. 车间里或者生产线上的生产作业计划.生产过程的调度和管 ...
- 工厂为什么要进行计划排产,APS高级计划排程系统的优势作用是什么?
我们每个人的指挥中心是大脑,大脑对我们身体发出各种各样的指令,不停的告诉我们身体去干什么. 那么,一个制造企业的指挥中心是哪里?工厂每天都会接到各种各样的订单,通过几百上千的工人,使用各种设备来生产. ...
- (四) 一起学 Unix 环境高级编程(APUE) 之 系统数据文件和信息
. . . . . 目录 (一) 一起学 Unix 环境高级编程 (APUE) 之 标准IO (二) 一起学 Unix 环境高级编程 (APUE) 之 文件 IO (三) 一起学 Unix 环境高级编 ...
随机推荐
- 07.LoT.UI 前后台通用框架分解系列之——强大的文本编辑器
LOT.UI分解系列汇总:http://www.cnblogs.com/dunitian/p/4822808.html#lotui LoT.UI开源地址如下:https://github.com/du ...
- Matlab 绘制三维立体图(以地质异常体为例)
前言:在地球物理勘探,流体空间分布等多种场景中,定位空间点P(x,y,x)的物理属性值Q,并绘制三维空间分布图,对我们洞察空间场景有十分重要的意义. 1. 三维立体图的基本要件: 全空间网格化 网格节 ...
- angular2系列教程(八)In-memory web api、HTTP服务、依赖注入、Observable
大家好,今天我们要讲是angular2的http功能模块,这个功能模块的代码不在angular2里面,需要我们另外引入: index.html <script src="lib/htt ...
- OpenCV人脸识别LBPH算法源码分析
1 背景及理论基础 人脸识别是指将一个需要识别的人脸和人脸库中的某个人脸对应起来(类似于指纹识别),目的是完成识别功能,该术语需要和人脸检测进行区分,人脸检测是在一张图片中把人脸定位出来,完成的是搜寻 ...
- SDWebImage源码解读_之SDWebImageDecoder
第四篇 前言 首先,我们要弄明白一个问题? 为什么要对UIImage进行解码呢?难道不能直接使用吗? 其实不解码也是可以使用的,假如说我们通过imageNamed:来加载image,系统默认会在主线程 ...
- Effective前端2:优化html标签
div { float: left; } .keyboard > div + div { margin-left: 8px; } --> div{display:table-cell;ve ...
- redis成长之路——(一)
为什么使用redis Redis适合所有数据in-momory的场景,虽然Redis也提供持久化功能,但实际更多的是一个disk-backed的功能,跟传统意义上的持久化有比较大的差别,那么可能大家就 ...
- PHP设计模式(一)简单工厂模式 (Simple Factory For PHP)
最近天气变化无常,身为程序猿的寡人!~终究难耐天气的挑战,病倒了,果然,程序猿还需多保养自己的身体,有句话这么说:一生只有两件事能报复你:不够努力的辜负和过度消耗身体的后患.话不多说,开始吧. 一.什 ...
- JavaMail发送邮件
发送邮件包含的内容有: from字段 --用于指明发件人 to字段 --用于指明收件人 subject字段 --用于说明邮件主题 cc字段 -- 抄送,将邮件发送给收件人的同时抄 ...
- 关于我 — About Me
个人简介 姓名:周旭龙 关注:.NET开发技术.Web前端技术 邮箱:edisonchou@hotmail.com GitHub: https://github.com/edisonchou 主要经历 ...