Hadoop(13)-MapReduce框架原理--Job提交源码和切片源码解析
1.MapReduce的数据流

1) Input -> Mapper阶段
这一阶段的主要分工就是将文件切片和把文件转成K,V对
输入源是一个文件,经过InputFormat之后,到了Mapper就成了K,V对,以上一章的流量案例来说,经过InputFormat之后,变成了手机号为key,这一行数据为value的K,V对,所以这里我们可以自定义InputFormat,按照具体的业务来实现将文件切片并且转为K,V对的方式
2) Mapper -> Reducer阶段
这一阶段叫做shuffle(洗牌)阶段,从Mapper出来的数据是无序的K,V对,那到了Reducer阶段,就变成了有序了.所以我们可以自定义排序规则
3) Reducer -> Output阶段
文件数据经过之前的种种处理,已经变成了有序的数据,这一阶段就是将数据写入文件
2.数据切片与MapTask并行度决定机制
问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
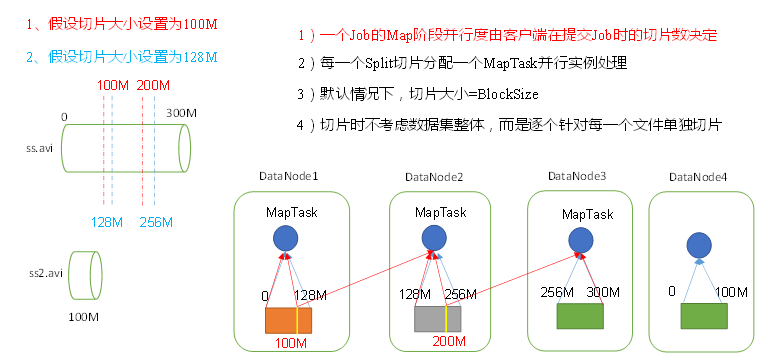
一个300M的数据,按照blocksize=128M进行存储,在datanode上分别是0-128m,128m-256m,256m-300m
1) 红线切片,将数据按照100M进行切片,每个MapTask处理同样大小的100M数据,看似很公平,datanode1的MapTask处理100M数据,剩下的28m传输给datanode2的MapTask,datanode2的MapTask处理28m+本地的72m数据,剩下的56m再传输给datanode3的MapTask.这样就增加了84m的网络传输数据.为了减少网络传输,yarn有一个本地原则,即block保存在哪个节点上,就在哪个节点上启动MapTask
2) 蓝线切片,切片大小128m=blocksize,每一个datanode启动的MapTask处理的数据都是128m,虽然看似处理速度比1)的100m慢一些,但是却节省了紧张的网络传输资源
所以约定俗成的,切片大小=blocksize
3.Job提交流程源码


确定job的输出路径是否有问题



创建jobid和临时文件夹

生成job的配置信息

经过这一步写入后,文件夹里就有了文件


最后提交job

整理一下
waitForCompletion() submit(); // 1建立连接
connect();
// 1)创建提交Job的代理
new Cluster(getConfiguration());
// (1)判断是本地yarn还是远程
initialize(jobTrackAddr, conf); // 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); // 2)获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID(); // 3)拷贝jar包到集群
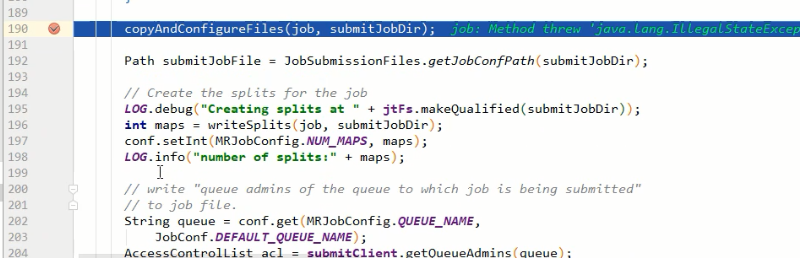
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir); // 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job); // 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out); // 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
4.FileInputFormat切片机制
上一小章的job提交流程里,生成的临时文件夹里面,有一个job.split文件,说明切片是在job提交之前就切好了,是本地的Driver类做的
那么就再追一下切片源码


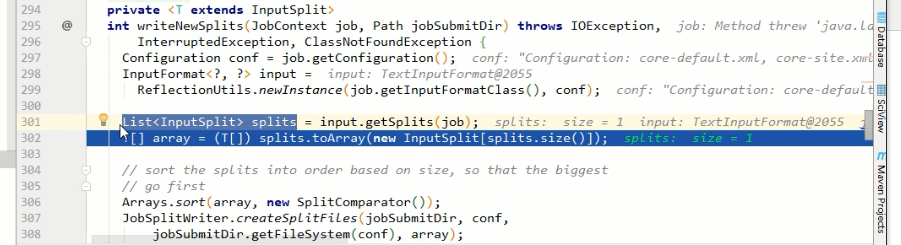
最小值minsize=1,最大值maxsize是long的最大值

遍历input源的文件夹,对每一个文件进行切片,先判断文件是否可切
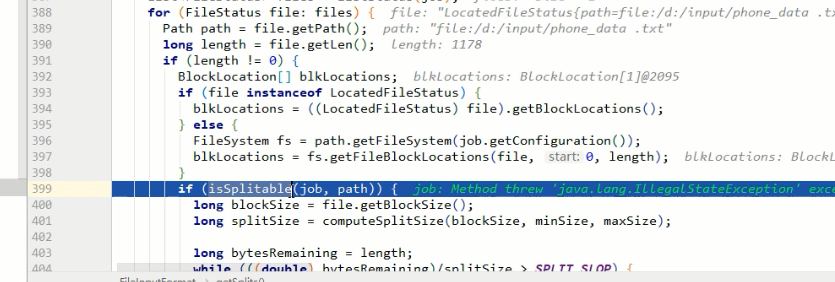
计算切片大小

如,minsize=1,blocksize=32G(33554432),maxsize=9223372036854775807
通过计算,返回的是blocksize.也就是返回的中间值
如果想增加切片大小,那么就增加minsize的大小到>blocksize,如果想减小切片大小,那么就减小maxsize大小到<blocksize

bytesRemaining是文件的大小,根据上面计算到的splitSize来进行切片
404行的SPLIT_SLOP的值是1.1,比的时候是按1.1倍来比,而409行切的时候是按1倍来切
假如blocksize=32M,现在要切一个32.001M的文件,为了多出来的1k启动一个MapTask,很浪费不值当~,所以这样做是为了保证,切出来的片,至少是blocksize大小的10%以上,如果不够10%,那就交给最后的MapTask哥们来处理好了
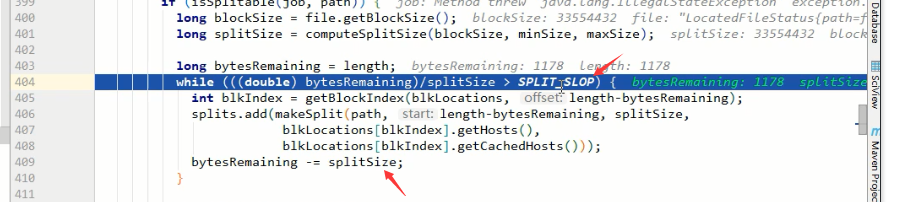
最后将切片放到切片list里

总结一下

Hadoop(13)-MapReduce框架原理--Job提交源码和切片源码解析的更多相关文章
- MapReduce之Job提交流程源码和切片源码分析
hadoop2.7.2 MapReduce Job提交源码及切片源码分析 首先从waitForCompletion函数进入 boolean result = job.waitForCompletion ...
- 大数据入门第七天——MapReduce详解(二)切片源码浅析与自定义patition
一.mapTask并行度的决定机制 1.概述 一个job的map阶段并行度由客户端在提交job时决定 而客户端对map阶段并行度的规划的基本逻辑为: 将待处理数据执行逻辑切片(即按照一个特定切片大小, ...
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述 2.排序分类 3.WritableComparable案例 这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进 ...
- Hadoop(16)-MapReduce框架原理-自定义FileInputFormat
1. 需求 将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文 ...
- Hadoop(20)-MapReduce框架原理-OutputFormat
1.outputFormat接口实现类 2.自定义outputFormat 步骤: 1). 定义一个类继承FileOutputFormat 2). 定义一个类继承RecordWrite,重写write ...
- Hadoop(14)-MapReduce框架原理-切片机制
1.FileInputFormat切片机制 切片机制 比如一个文件夹下有5个小文件,切片时会切5个片,而不是一个片 案例分析 2.FileInputFormat切片大小的参数配置 源码中计算切片大小的 ...
- Hadoop(19)-MapReduce框架原理-Combiner合并
1. Combiner概述 2. 自定义Combiner实现步骤 1). 定义一个Combiner继承Reducer,重写reduce方法 public class WordcountCombiner ...
随机推荐
- font not embeded
转自:http://blog.csdn.net/chenyusiyuan/article/details/4078671,感谢分享! 装了半天adobe acrobat distiller 要泪崩,解 ...
- SVNKit学习——使用High-Level API管理Working Copy示例(六)
本篇内容是基于SVNKit High-Level API实现的针对Working copy的操作,操作内容与SVN图形化界面.命令行类似. High-Level API类图: 核心思想: 所有操作由各 ...
- java面试题之----get和post请求方法的区别
GET和POST两种基本请求方法的区别 GET和POST是HTTP请求的两种基本方法,要说它们的区别,接触过WEB开发的人都能说出一二. 最直观的区别就是GET把参数包含在URL中,POST通过req ...
- 使用WindowsService为宿主实装WCF 服务
1. 写WCF服务 创建一个接口类,与一个实现类.接口类上打上[ServiceContract]标签,需要暴露的服务方法上打上[OperationContract] (注意:增加System.Se ...
- May 16th 2017 Week 20th Tuesday
The most fearful enemy is not having a firm conviction. 最可怕的敌人,就是没有坚强的信念. A firm conviction or belie ...
- 长大Tips
队名:CW 队员: B20150304403 王香辉 B20150304408 李孟君 B20150304411 曾翡 B20150304414 吴海波 B20150304430 文淼 B201503 ...
- 一个简单的例子理解Kubernetes的三种IP地址类型
很多Kubernetes的初学者对Kubernetes里面三种不同的IP地址和工作机制理解得不是很清楚. 本文我们通过一个最简单的例子来学习. 用如下命令行创建一个基于nginx的deployment ...
- Hybris ECP(Enterprise Commerce Platform)的调试
This blog is written to demonstrate how to setup debug environment for Hybris ECP(Enterprise Commerc ...
- bzoj 2434 [Noi2011]阿狸的打字机——AC自动机
题目:https://www.lydsy.com/JudgeOnline/problem.php?id=2434 dfs AC自动机,走过的点权值+1,回溯的时候权值-1:走到询问的 y 串的节点,看 ...
- 牛客国庆集训派对Day2 F、平衡二叉树 【构造+记忆化搜索】
任意门:https://www.nowcoder.com/acm/contest/202/F 时间限制:C/C++ 1秒,其他语言2秒空间限制:C/C++ 1048576K,其他语言2097152K6 ...