Data Replication in a Multi-Cloud Environment using Hadoop & Peer-to-Peer technologies
要FQ。。。
——————————————————————————————————————————————————————
Few years ago, i started working on a project named Jxtadoop providing Hadoop Distributed Filesystem capabilities on top of of a peer-to-peer network. This initial goal was simply to load a file once to a Data Cloud which will take care of replication wherever the peers (data nodes) are deployed... I also wanted to avoid putting my data outside of my private network to ensure complete data privacy.
After some times, it appeared that this solution is also a very good fit to support data replication in a Multi-Cloud Environment. Any file (small or big) can be loaded in one cloud and then gets automatically replicated to the other clouds. This makes multi-cloud Data Brokering very easy and straightforward.
Hadoop is a very good candidate to provide those functionalities at a datacenter level. However when moving to a multi-cloud environment, it is no longer viable unless a Virtual Private Data Network is built. This VPDN is created on top of a peer-to-peer network which provides redundancy, multi-path routing, privacy, encryption across all the clouds...
Concept
Let's assume we are in a true Multi-Cloud Broker environment. For this blog, i assume i actually have 3 clouds hosting multiple workloads (aka virtual servers) in each. The picture below depicts a classical configuration which will appear in the coming years where business will source IT from different Cloud providers and really consume IT in a true Service Broker model.
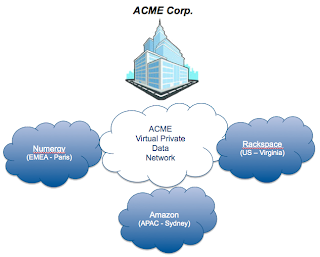
ACME Corp. has its headquarters based out of France and subsidiaries all over the world.
The new strategy is to source IT infrastructure from local service providers to deliver IT services directly to the local branches. There is no will to set up local IT anymore.
Data replication, propagation, protection (...) is really an issue in such a configuration and reversibility has to also be configured.
Setting up this Virtual Private Data Network will support this Service Broker Strategy.
Conceptually, the solution is very simple. A master node (calledRendez-vous Namenode) is located in the HQ and is the brain of the VPDN. That's where all the logic is handled such as data availability, multi-path data transfer, data placement... In each Cloud, there is a Relay Datanode which acts as the entry point for the Cloud. It will play a routing role communicating directly with other Cloud relays and also play a buffering role for data transmission. To avoid any SPOF, all those peers can be deployed in a multi-instance mode.
Finally each workload instance (physical servers, virtual machines, containers...) hosts a Peer Datanode which is the actual endpoint for data storage and consumption.
Virtual Private Data Network Architecture
As explained in the previous section, the overall architecture relies on three main components.
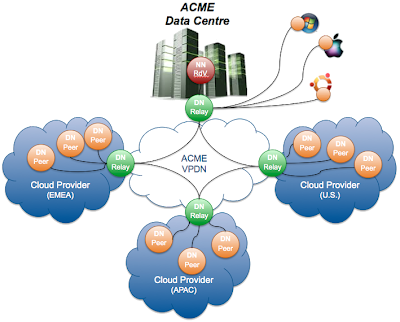
- Namenode Rendez-Vous providing Data Transport Logic as well as Data placement and replication. It has the peer-to-peer network topology overall understanding as well as the data cloud meta-data. There is no data traffic going through this peer.
- Datanode Relay providing Data Storage as well as Data Transport. The local peers which can communicate between each others through multicast, will rely on the relays to communicate with remote peers located in other data clouds. It can also store data as a temporary buffer.
- Datanode Peer providing Data Storage to store data chunks on each server peer and even on remote desktop peers.
All the peers can be made redundant (multiple Rendez-Vous, multiple Relays ...) to increase the multi-path routing capability and avoid any SPOF. The data is then split into chunks of pre-defined size and dispatched across the Data Cloud. Data locality can be set to ensure there is one replica per Cloud or that replicas are limited to a Cloud (for example for data which must stay in a specific country).
All the communications are multi-path, authenticated, encrypted... There is no need to set-up VPNs between the Clouds which could lead to some contentions points. Here the communication is either direct through multicast or going through the best (shortest) routing path at the peer-to-peer layer level.
The traffic flows are of 2 kinds.
. The RPC flow and the DATA flow. The first one handles all the signaling required to operate the VPDN such as routing, heartbeat, placement requests, updates ... There is actually no business data on this flow, hence it is possible to have a set-up where data traffic is limited to a cloud or even a country while the commands are centrally managed.
. The DATA flow is the actual business data transferred over the wire. This flow can be local to a datacentre using multicast wherever possible. It can also still be local but transiting through the Cloud relay for multiple domains. Finally this flow can go through multiple relays. In the example below, a data block located on the Windows PC will get replicated to the APAC Cloud by going through 2 relays (the DC one + the APAC Cloud one).
Benefits
This new approach brings many benefits for a mutli-Cloud environment and for companies willing to operate their IT with an IT Service Broker model.
- Redundancy : the data is automatically replicated in the Clouds wherever needed ;
- Availability : the data is always available with the use of multiple replicas (3, 5, 7...) ;
- Efficiency : quick deployment, quick capacity expansion ;
- Simplicity : load once on a peer and automated replication ;
- Future-proof : leverage big data technologies ;
- Portable : can run on any server and desktop platforms supporting Java 7 ;
- Confidentiality : all the data transfer are encrypted, authenticated ... ;
- Locality : data can be located in a specific Cloud and not leak outside ;
Setting up your own environment
The technology used to create this Virtual Private Data Network can be found here. The testing described above has been done using a physical environment from OVH in France to simulate the HQ. 3 clouds have been consumed :Numergy (EMEA - France), Rackspace (U.S. - Virginia) and Amazon (APAC - Australia).
The testing leveraged Docker to create multiple Datanode peers on a single VM with a complex network topology (see1 & 2). The associated containers can be found on the Docker main repository :
- Namenode Rendez-Vous (jxtadoop/namenode)
- Datanode Relay (jxtadoop/relay)
- Datanode Peer (jxtadoop/datanode)
Desktop clients have been installed on Mac OS, Windows and Linux. Just ensure you use Windows 7.
Conclusion
This concludes my Jxtadoop project which will get released as version 1.0.0 later this month. I'll provide a SaaS set-up with a Rendez-vous Namenode and a Relay Peer for quick testing.
Next ideas :
- Roll-out StandaloneHDFSUI for Jxtadoop ;
- Release FileSharing capability based on Jxtadoop ;
- PaaS/SaaS set-up for Jxtadoop with Docker and CloudFoundry ;
- Think about magic combination of App Virtualization (Docker), Network Virtualization (Open vSwitch) and Data Virtualization (Jxtadoop) ;
Links
Data Replication in a Multi-Cloud Environment using Hadoop & Peer-to-Peer technologies的更多相关文章
- elasticsearch6.7 05. Document APIs(1)data replication model
data replication model 本节首先简要介绍Elasticsearch的data replication model,然后详细描述以下CRUD api: 1.读写文档(Reading ...
- ACID、Data Replication、CAP与BASE
ACID 在传数据库系统中,事务具有ACID 4个属性. (1) 原子性(Atomicity):事务是一个原子操作单元,其对数据的修改,要么全都执行,要么全都不执行. (2) 一致性(Consiste ...
- 【Cloud Computing】Hadoop环境安装、基本命令及MapReduce字数统计程序
[Cloud Computing]Hadoop环境安装.基本命令及MapReduce字数统计程序 1.虚拟机准备 1.1 模板机器配置 1.1.1 主机配置 IP地址:在学校校园网Wifi下连接下 V ...
- 6 Multi-Cloud Architecture Designs for an Effective Cloud
https://www.simform.com/multi-cloud-architecture/ Enterprises increasingly want to take advantage of ...
- Hive-0.x.x - Enviornment Setup
All Hadoop sub-projects such as Hive, Pig, and HBase support Linux operating system. Therefore, you ...
- Enabling granular discretionary access control for data stored in a cloud computing environment
Enabling discretionary data access control in a cloud computing environment can begin with the obtai ...
- Tagging Physical Resources in a Cloud Computing Environment
A cloud system may create physical resource tags to store relationships between cloud computing offe ...
- Awesome Big Data List
https://github.com/onurakpolat/awesome-bigdata A curated list of awesome big data frameworks, resour ...
- Scalable MySQL Cluster with Master-Slave Replication, ProxySQL Load Balancing and Orchestrator
MySQL is one of the most popular open-source relational databases, used by lots of projects around t ...
随机推荐
- 【记录一下】phpMyAdmin 4.5.0-beta1 发布,要求 PHP 5.5
详情点击: [开源中国]http://www.oschina.net/news/65696/phpmyadmin-4-5-0-beta1 [phpMyAdmin]https://www.phpmyad ...
- PHP超全局变量$_ENV详解,及$_ENV为空的可能原因
PHP中的$_ENV存储了一些系统的环境变量,因为牵扯到实际的操作系统,所以不可能给出$_ENV的完整列表. $_ENV为空的可能原因: 你的php.ini的variables_order值为&qu ...
- C#分析URL参数获取参数和值得对应列表(二)
不错博客: [C#HttpHelper]官方产品发布与源码下载---苏飞版http://www.sufeinet.com/thread-3-1-1.html http://blog.csdn.net/ ...
- 使用spring-boot-admin对spring-boot服务进行监控
原文:http://www.cnblogs.com/ityouknow/p/8440455.html 上一篇文章<springboot(十九):使用Spring Boot Actuator监控应 ...
- 直接拿来用!最火的iOS开源项目(三)
相比Android,GitHub上的iOS开源项目更可谓是姹紫嫣红.尽管效果各异,但究其根源,却都是因为开发者本身对于某种效果的需求以及热爱.在“直接拿来用!最火的iOS开源项目”系列文章(一).(二 ...
- git:FETCH_HEAD
FETCH_HEAD: 是一个版本链接,记录在本地的一个文件中,指向着目前已经从远程仓库取下来的分支的末端版本. 举例说明:将远程origin仓库的xx分支合并到本地的yy分支.git fetch o ...
- RTOS系统与Linux系统的区别
RTOS是实时操作系统 Linux是时分系统,不过可以通过配置内核改成实时系统 分时操作系统 英文:Time-sharing Operating System 释义:使一台计算机同时为几个.几十个甚 ...
- android BSP与硬件相关子系统读书笔记(1)android BSP移植综述
从linux驱动转行至Android驱动开发大半年了,一开始就产生了一个很纠结目标和问题,就是不停的google如何porting android!这个问题得到的结果对于初出茅庐的我,感到迷惘.随着工 ...
- 【java】为数组全部元素赋同样的值 以及 数组之间的复制
为数组全部元素赋同样的值 : boolean[] resArray=new boolean[100]; Arrays.fill(resArray, true); 数组之间的复制: System.arr ...
- 总结对Docker这个东西的想法
记得一开始的时候,还只能在一些网站上看到关于Docker零星的一些消息,之后的不久,有关Docker消息就遍布网络. 是什么因素让Docker火起来的? 或者说什么原因促使大家都对Docker感兴趣并 ...