使用Fluentd + MongoDB构建实时日志收集系统
Fluentd是一个日志收集系统,它的特点在于其各部分均是可定制化的,你可以通过简单的配置,将日志收集到不同的地方。
目前开源社区已经贡献了下面一些存储插件:MongoDB, Redis, CouchDB,Amazon S3, Amazon SQS, Scribe, 0MQ, AMQP, Delayed, Growl 等等。
本文要介绍的是在Fluentd的最新版中已经内置的MongoDB支持。主要通过一个收集Apache日志的例子来说明其使用方法:
机制图解
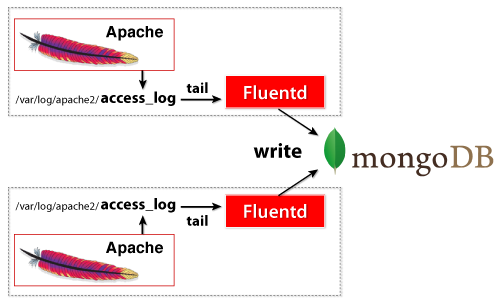
安装
为了完成相关的测试,需要安装下面一些组件:
- Fluentd with MongoDB Plugin
- MongoDB
- Apache (with the Combined Log Format)
在Fluentd的最新安装包中已经包含了MongoDB插件,你也可以用命令
gem install fluent-plugin-mongo
来进行安装
配置
如果你是使用上面的deb/rpm包安装的Fluentd,那么配置文件位置在:/etc/td-agent/td-agent.conf,否则其位置应该在:/etc/fluentd/fluentd.conf
首先我们编辑配置文件中的source来设置日志来源
<source>
type tail
format apache
path /var/log/apache2/access_log
tag mongo.apache
</source>
其中:
- type tail: tail方式是 Fluentd 内置的输入方式,其原理是不停地从源文件中获取新的日志。
- format apache: 指定使用 Fluentd 内置的 Apache 日志解析器。
- path /var/log/apache2/access_log: 指定日志文件位置。
- tag mongo.apache: 指定tag,tag被用来对不同的日志进行分类
下面再来编辑输出配置,配置日志收集后存储到MongoDB中
<match mongo.**>
# plugin type
type mongo # mongodb db + collection
database apache
collection access # mongodb host + port
host localhost
port 27017 # interval
flush_interval 10s
</match>
match标签后面可以跟正则表达式以匹配我们指定的tag,只有匹配成功的tag对应的日志才会运用里面的配置。配置中的其它项都比较好理解,看注释就可以了,其中flush_interval是用来控制多长时间将日志写入MongoDB一次。
测试
用ab工具对Apache进行访问,以产生相应的访问日志以供收集
$ ab -n 100 -c 10 http://localhost/
然后我们在MongoDB中就能看到收集到的日志了
$ mongo
> use apache
> db.access.find()
{ "_id" : ObjectId("4ed1ed3a340765ce73000001"), "host" : "127.0.0.1", "user" : "-", "method" : "GET", "path" : "/", "code" : "200", "size" : "44", "time" : ISODate("2011-11-27T07:56:27Z") }
{ "_id" : ObjectId("4ed1ed3a340765ce73000002"), "host" : "127.0.0.1", "user" : "-", "method" : "GET", "path" : "/", "code" : "200", "size" : "44", "time" : ISODate("2011-11-27T07:56:34Z") }
{ "_id" : ObjectId("4ed1ed3a340765ce73000003"), "host" : "127.0.0.1", "user" : "-", "method" : "GET", "path" : "/", "code" : "200", "size" : "44", "time" : ISODate("2011-11-27T07:56:34Z") }
来源: blog.treasure-data.com翻译: http://blog.nosqlfan.com/html/3521.html
使用Fluentd + MongoDB构建实时日志收集系统的更多相关文章
- 用ElasticSearch,LogStash,Kibana搭建实时日志收集系统
用ElasticSearch,LogStash,Kibana搭建实时日志收集系统 介绍 这套系统,logstash负责收集处理日志文件内容存储到elasticsearch搜索引擎数据库中.kibana ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- Go实现海量日志收集系统(一)
项目背景 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机器规模不大,一个系统通常 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
- GO学习-(32) Go实现日志收集系统1
Go实现日志收集系统1 项目背景 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机 ...
- Flume -- 开源分布式日志收集系统
Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. 一.Flum ...
- 用fabric部署维护kle日志收集系统
最近搞了一个logstash kafka elasticsearch kibana 整合部署的日志收集系统.部署参考lagstash + elasticsearch + kibana 3 + kafk ...
- 基于Flume的美团日志收集系统(二)改进和优化
在<基于Flume的美团日志收集系统(一)架构和设计>中,我们详述了基于Flume的美团日志收集系统的架构设计,以及为什么做这样的设计.在本节中,我们将会讲述在实际部署和使用过程中遇到的问 ...
随机推荐
- 人工智能-基于百度baidu-ai和图灵机器人实现学说话机器人
本文引用了2个js文件,这里提供下CDN资源,! <script type="application/javascript" src="https://cdn.bo ...
- 人工智能-baidu-aip语音识别(语音转文字)
做这个之前,需要在电脑上安装FFmpeg工具,将要转的语音格式转为PCM格式.FFmpeg不需要安装,下载后,打开bin文件夹,然后将路径放在系统环境变量里.记住,要关闭所有打开的Pycharm,然后 ...
- PyNest——Part1:neurons and simple neural networks
neurons and simple neural networks pynest – nest模拟器的界面 神经模拟工具(NEST:www.nest-initiative.org)专为仿真点神经元的 ...
- sqlserver整理的实用资料
1 --- 创建 备份数据的 device 2 3 USE DB_ZJ 4 EXEC sp_addumpdevice 'disk', 'testBack', 'c:\MyNwind_1.dat' 5 ...
- Django设置上传文件夹
django提供了两种字段类型models.FileField与models.ImageField,用于保存上传文件与图象.这两类字段提供了一个参数'upload_to',用于定义上传文件保存的路径( ...
- LeetCode:二叉树的锯齿形层次遍历【103】
LeetCode:二叉树的锯齿形层次遍历[103] 题目描述 给定一个二叉树,返回其节点值的锯齿形层次遍历.(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行). 例如:给定二叉树 ...
- $.proxy() 的妙用
$.proxy() 最主要就是用来修改函数执行时的上下文对象的. 先看以下情景: <div id="panel" style="display:none;" ...
- linux 网卡buffer大小
参考截取一部分:https://blog.csdn.net/ysu108/article/details/7764461 在linux下可以修改协议栈改变tcp缓冲相关参数: 修改系统套接字缓冲区 e ...
- Qt事件机制---信号通过事件实现,事件可以过滤,事件更底层,事件是基础,信号是扩展。
转:http://www.cnblogs.com/findumars/p/8001484.html Qt事件机制(是动作发生后,一种通知对象的消息,是被动与主动的总和.先处理自己队列中的消息,然后再处 ...
- 黑色CSS3立体动画菜单
在线演示 本地下载