elasticsearch term 查询之一
1、前言
1.1、term query
term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词,所以我们的搜索词必须是文档分词集合中的一个。比如说我们要查找年龄为39的所有文档
POST /bank/_search?pretty
{
"query": {
"term": {
"age": ""
}
}
}
结果:

另外再查询address=Avenue的文档,没有查到结果
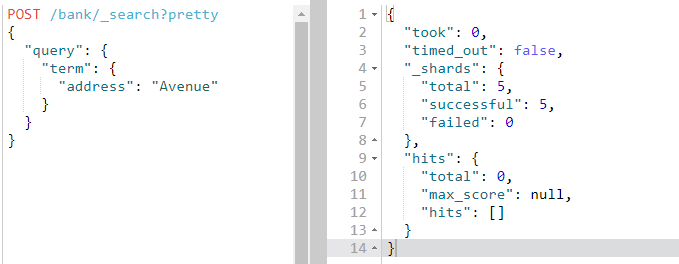
为什么?
字符串字段可以是文本类型(视为全文,如电子邮件正文)或关键字(视为精确值,如电子邮件地址或邮政编码)。精确值(如数字,日期和关键字)具有在添加到倒排索引的字段中指定的确切值,以使其可被搜索。
但是,分析文本字段。这意味着它们的值首先通过一个分析器产生一个项目列表,然后将其添加到倒排索引中。
分析文本的方法有很多种:默认的标准分析器会删除大部分的标点符号,将文本分解为单个的单词,并将其分解为小写字母。例如,标准分析仪会将字符串“Quick Brown Fox!”变成[quick,brown,fox]。
先看Avenue的分析

因为171 Putnam Avenue被分解为 171,putnam,avenue三个词,因此在Avenue时无法查询到,因为第一个字符是大写
下面做一个测试演示
首先,创建一个索引,指定字段映射,并索引一个文档
创建索引和索引数据
PUT my_index
{
"mappings": {
"my_type": {
"properties": {
"full_text": {
"type": "text"
},
"exact_value": {
"type": "keyword"
}
}
}
}
} PUT my_index/my_type/1
{
"full_text": "Quick Foxes!", 3
"exact_value": "Quick Foxes!"
}
1、full_text字段是文本类型,将被分析。
2、exact_value字段是关键字类型,不会被分析。
3、full_text倒排索引将包含术语:[quick,foxes]。
4、exact_value倒排索引将包含确切的术语:[Quick Foxes!]
现在,比较术语查询和匹配查询的结果:
GET my_index/my_type/_search
{
"query": {
"term": {
"exact_value": "Quick Foxes!"
}
}
} GET my_index/my_type/_search
{
"query": {
"term": {
"full_text": "Quick Foxes!"
}
}
} GET my_index/my_type/_search
{
"query": {
"term": {
"full_text": "foxes"
}
}
} GET my_index/my_type/_search
{
"query": {
"match": {
"full_text": "Quick Foxes!"
}
}
}
1、此查询匹配,因为exact_value字段包含确切的术语Quick Foxes !.
2、这个查询不匹配,因为full_text字段只包含quick和foxes这两个词。 它不包含确切的术语Quick Foxes !.
3、术语foxes的查询匹配full_text字段。
4、full_text字段上的匹配查询首先分析查询字符串,然后查找包含快速或狐狸或两者的文档。
再看看分析
GET /my_index/_analyze
{
"field": "exact_value",
"text": "Quick Foxes!"
} 结果:
{
"tokens": [
{
"token": "Quick Foxes!",
"start_offset": 0,
"end_offset": 12,
"type": "word",
"position": 0
}
]
}
GET /my_index/_analyze
{
"field": "full_text",
"text": "Quick Foxes!"
}
结果: {
"tokens": [
{
"token": "quick",
"start_offset": 0,
"end_offset": 5,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "foxes",
"start_offset": 6,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 1
}
]
}
elasticsearch term 查询之一的更多相关文章
- elasticsearch term 查询二:Range Query
Range Query 将文档与具有一定范围内字词的字段进行匹配. Lucene查询的类型取决于字段类型,对于字符串字段,TermRangeQuery,对于数字/日期字段,查询是NumericRang ...
- Elasticsearch 结构化搜索、keyword、Term查询
前言 Elasticsearch 中的结构化搜索,即面向数值.日期.时间.布尔等类型数据的搜索,这些数据类型格式精确,通常使用基于词项的term精确匹配或者prefix前缀匹配.本文还将新版本的&qu ...
- Elasticsearch中的Term查询和全文查询
目录 前言 Term 查询 exists 查询 fuzzy 查询 ids 查询 prefix 查询 range 查询 regexp 查询 term 查询 terms 查询 terms_set 查询 t ...
- 【转】elasticsearch的查询器query与过滤器filter的区别
很多刚学elasticsearch的人对于查询方面很是苦恼,说实话es的查询语法真心不简单- 当然你如果入门之后,会发现elasticsearch的rest api设计是多么有意思. 说正题,ela ...
- ES 入门记录之 match和term查询的区别
ElasticSearch 系列文章 1 ES 入门之一 安装ElasticSearcha 2 ES 记录之如何创建一个索引映射 3 ElasticSearch 学习记录之Text keyword 两 ...
- ElasticSearch—分页查询
ElasticSearch查询—分页查询详解 Elasticsearch中数据都存储在分片中,当执行搜索时每个分片独立搜索后,数据再经过整合返回.那么,如何实现分页查询呢? 按照一般的查询流程来说,如 ...
- ElasticSearch高级查询
ElasticSearch高级查询 https://www.imooc.com/video/15759/0 ElasticSearch查询 1,子条件查询:特定字段查询所指特定值 1.1query c ...
- ELK 学习笔记之 elasticsearch 基本查询
elasticsearch 基本查询: 基本查询: term查询: terms查询: from和size查询: match查询: match_all查询: match_phrase查询: multi_ ...
- 【Elasticsearch】ElasticSearch基本查询
学习elasticsearch查询用法的时候,发现这篇文章写得很详细,为以后方便查看,就直接搬过来了,原文链接在下面. 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附 ...
随机推荐
- [Leetcode Week8]Edit Distance
Edit Distance 题解 原创文章,拒绝转载 题目来源:https://leetcode.com/problems/edit-distance/description/ Description ...
- TASK_KILLABLE:Linux 中的新进程状态【转】
转自:https://www.ibm.com/developerworks/cn/linux/l-task-killable/index.html 新的睡眠状态允许 TASK_UNINTERRUPTI ...
- 1.hadoop环境搭建以及配置
提前说明一下:由于环境的配置搞得我很头疼,所以记录下来.并不是零基础,像hadoop的由来.发展史.结构.各个组件,这里都没有介绍,只是为了自己能够在忘了的时候回忆起来,所以记录下来 如何在linux ...
- 如何用sqlplus执行sql脚本,且让出错后及时退出sqlplus
按sqlplus常规作法,是要登陆,输入用户名和密码才能操作的. 并且,如果不作特别设置,SQL脚本里的部门语句有问题后,它还是会坚持执行完成其余的SQL的. 为了安全和自动化,得改进一下了. sql ...
- [BZOJ1475]方格取数 网络流 最小割
1475: 方格取数 Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 1025 Solved: 512[Submit][Status][Discuss] ...
- (转)zeromq 安装
http://youzifei.iteye.com/blog/1698237 zeromq 今天在安装zeromq的时候费了好大的力气才算装好 下面来回顾一下在linux安装zeromq的过程 首先 ...
- aoj 0033 Ball【dfs/枚举】
有一个形似央视大楼(Orz)的筒,从A口可以放球,放进去的球可通过挡板DE使其掉进B裤管或C裤管里,现有带1-10标号的球按给定顺序从A口放入,问是否有一种控制挡板的策略可以使B裤管和C裤管中的球从下 ...
- Python与数据结构[4] -> 散列表[0] -> 散列表与散列函数的 Python 实现
散列表 / Hash Table 散列表与散列函数 散列表是一种将关键字映射到特定数组位置的一种数据结构,而将关键字映射到0至TableSize-1过程的函数,即为散列函数. Hash Table: ...
- 1087: Common Substrings (哈希)
1087: Common Substrings Time Limit:3000/1000 MS (Java/Others) Memory Limit:163840/131072 KB (Java/ ...
- POJ3026 Borg Maze(Prim)(BFS)
Borg Maze Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 12729 Accepted: 4153 Descri ...