在zookeeper集群的基础上,搭建solrCloud
1 将在window中部署的单机版solr上传到node-01中
cd /export/software/
rz
选择资料中的solr.zip进行上传(此zip就是 solr的简单部署:在tomcat中启动slor 的内容, 包含solr-home和tomcat)
2 将zip进行解压到指定目录中
由于是zip文件,在linux上解压需要unzip
yum -y install unzip
unzip solr.zip
mv solr /export/servers/
3 修改tomcat的Catalina.sh的配置文件
cd /export/servers/solr/apache-tomcat-7.0./bin
vi catalina.sh //注意此时修改的.sh的文件 为非.bat //添加如下内容:(此处后面还会进行修改, 目前只是为了测试单机版本能否在linux中运行)
export "JAVA_OPTS=-Dsolr.solr.home=/export/servers/solr/solr-home"
4 启动tomcat测试单机版本能否在linux中运行
//注意: 由于是解压的是zip文件, tomcat中的.sh文件都没有任何的执行缺陷, 需要进行赋权限:
chmod /export/servers/solr/apache-tomcat-7.0./bin/* //启动tomcat:
cd /export/servers/solr/apache-tomcat-7.0.77/bin/
./startup.sh
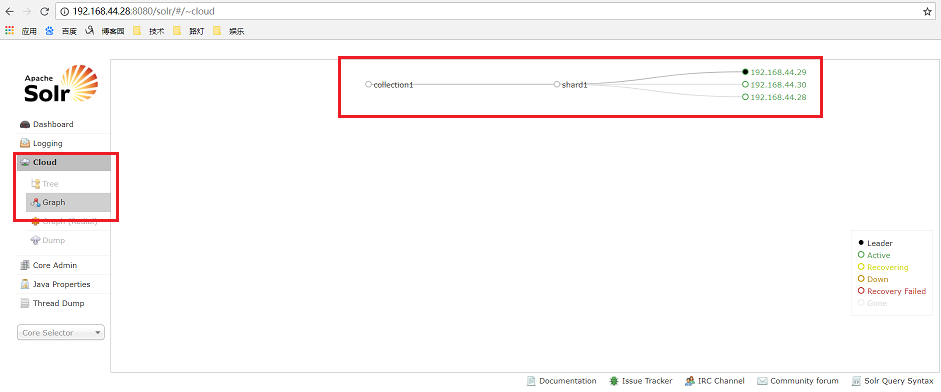
访问 192.168.44.28:8080/solr 看是否成功 192.168.44.28是你当前虚拟机的ip
5 成功后: 将tomcat务必先关闭
./shutdown.sh
6 将solr的配置文件交给zookeeper进行管理
//1. 需要先上传solr的安装包
cd /export/software/
rz
//2. 解压solr的安装包
unzip solr-4.10..zip
//3. 将solr安装包复制到/export/servers下
mv solr-4.10. /export/servers/
//4. 开始执行上传
cd /export/servers/solr-4.10./example/scripts/cloud-scripts/
//注意: 以下命令是一行 而且要确保三台机器的zookeeper是开启的 zookeeper集群的搭建
./zkcli.sh -zkhost node-:,node-:,node-: -cmd upconfig -confdir /export/servers/solr/solr-home/collection1/conf/ -confname solrconf
//参数解释: -zkhost指定zookeeper地址列表, -cmd指定命令, upconfig上传配置的命令, -confdir配置文件所在目录, -confname配置名称

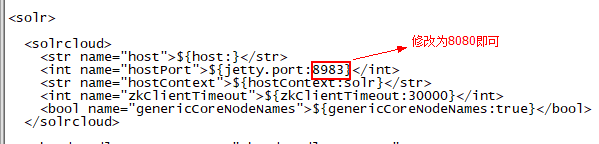
7 修改solr.xml配置文件
solr.xml是solr集群管理文件
cd /export/servers/solr/solr-home/
vi solr.xml
8 修改tomcat的Catalina.sh配置文件
其实可以单独修改每个solr的solrhome地址(修改每个solr的 web.xml 文件, 关联它自己的solrhome),然后在这里直接配置-DzHost就可以了,这里就先不做介绍了。
cd /export/servers/solr/apache-tomcat-7.0./bin/
vi catalina.sh
// 修改如下内容
export "JAVA_OPTS=-Dsolr.solr.home=/export/servers/solr/solr-home //原来的内容 //以下为替换后的内容 注意: 这是一行内容, 复制时一起复制即可
export "JAVA_OPTS=-Dsolr.solr.home=/export/servers/solr/solr-home -DzkHost=node-01:2181,node-02:2181,node-03:2181
9 将solr目录发送到其他两台linux上(node2,node3)
cd /export/servers/
scp -r solr root@node-:$PWD
scp -r solr root@node-:$PWD
10 依次启动三台solr即可
cd /export/servers/solr/apache-tomcat-7.0./bin/
./startup.sh
------------------------------以上 基本搭建就完成了 下面介绍solrCloud相关的管理命令-------------------------------
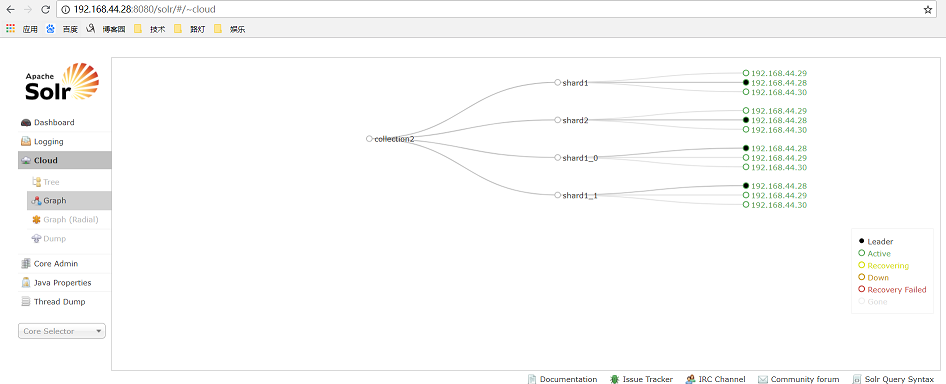
1 创建新集群(创建一个索引库)
http://192.168.44.28:8080/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=3&maxShardsPerNode=8&property.schema=schema.xml&property.config=solrconfig.xml //接口参数说明: action: 表示执行的操作 CREATE 创建
name: 新集群的名称
numShards: 分片数
replicationFactor: 每个分片的节点数
maxShardsPerNode: 设置每个分片的最大节点数, 默认为1
property.schema: 指定使用的schema文件 (注意, 此文件必须在zookeeper上存在)
property.config: 指定使用的solrConfig文件 (注意, 此文件必须在zookeeper上存在)
2 删除core命令
http://192.168.44.28:8080/solr/admin/collections?action=DELETE&name=collection1
3 查询所有的Core
http://192.168.44.28:8080/solr/admin/collections?action=LIST
4 分裂shard(扩展容量)
分裂: 就是将某个分片分成两个分片
注意: 一旦分裂后, 虽然原来的分片还可以提供服务, 但是已经不再保存数据, 会将数据保存到新的分裂后的分片
http://192.168.44.28:8080/solr/admin/collections?action=SPLITSHARD&collection=collection2&shard=shard1 参数说明:
shard: 指定要分裂的分片
5 删除某个分片
注意: 删除的分片必须是已经被分裂的, 或者是已经无法提供服务的
http://192.168.44.28:8080/solr/admin/collections?action=DELETESHARD&shard=shard1&collection=collection2
使用java代码对zookeeper集群中的solrCloud数据进行CURD
在zookeeper集群的基础上,搭建solrCloud的更多相关文章
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- 在zookeeper集群的基础上,搭建伪solrCloud集群
伪集群的搭建:将solrCloud搭建到同一台机器上. 准备工作 1 将在window中部署的单机版solr上传到服务器(虚拟机)中 solr的简单部署:在tomcat中启动slor 的内容 这一次放 ...
- [k8s]zookeeper集群在k8s的搭建(statefulset模式)-pod的调度
之前一直docker-compose跑zk集群,现在把它挪到k8s集群里. docker-compose跑zk集群 zk集群in k8s部署 参考: https://github.com/kubern ...
- 第八章 搭建hadoop2.2.0集群,Zookeeper集群和hbase-0.98.0-hadoop2-bin.tar.gz集群
安装配置jdk,SSH 一.首先,先搭建三台小集群,虚拟机的话,创建三个 下面为这三台机器分别分配IP地址及相应的角色:集群有个特点,三台机子用户名最好一致,要不你就创建一个组,把这些用户放到组里面去 ...
- 关于Linux系统下zookeeper集群的搭建
1.集群概述 1.1什么是集群 1.1.1集群概念 集群是一种计算机系统, 它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作.在某种意义上,他们可以被看作是一台计算机.集群系 ...
- docker-compose搭建zookeeper集群环境 CodingCode
docker-compose搭建zookeeper集群环境 使用docker-compose搭建zookeeper集群环境 zookeeper是一个集群环境,用来管理微服务架构下面的配置管理功能. 这 ...
- Zookeeper集群介绍及其搭建
1 Zookeeper集群简介 1为什么搭建Zookeeper集群 大部分分布式应用需要一个主控.协调器或者控制器来管理物理分布的子进程.目前,大多数都要开发私有的协调程序,缺乏一个通用机制,协调程序 ...
- Zookeeper 集群 BindException: Cannot assign requested address 解决方案
前言 经历: 最近在搭建zookeeper集群,基础是3台机器(尝试过ubuntu 17 和 Centos 7). 一开始选择的是3台腾讯云服务器,每台机器在java环境配置正确的情况下,单机的情况都 ...
- 构建Zookeeper集群(zkcluster) ~一篇文章玩转zk集群^.^
概念 Zookeeper集群是由一个leader(负责人)主机和多个follower(追随者)或observer(观察者)主机组成. 构建一个Zookeeper集群需要有一个leader和一个foll ...
随机推荐
- android开发之eclipse调试debug模式详解
之前我写了一个相关的帖子,但是今天看了一个还是写的比我详细,于是我拿过来和大家分享. 1.在程序中添加一个断点 如果所示:在Eclipse中添加了一个程序断点 在Eclipse中一共有三种添加断 ...
- ng 指令的自定义、使用
1.创建和使用var app = angular.module('myApp',['ng']);app.directive('指令名称',func); 自定义指令的命名:驼峰式,有两部分构成,前缀一般 ...
- python学习之aop装饰模式
实际开发过程当中可能要对某些方法或者流程做出改进,添加监控,添加日志记录等所以我们要去改动已有的代码,自己的或者别人的,但改动后测试不周会引发不可控的异常,aop 模式解决了这类问题引发重复代码大量积 ...
- 关于Bootstrap table的回调onLoadSuccess()和onPostBody()使用小结
关于Bootstrap table的回调onLoadSuccess()和onPostBody()使用小结 Bootstrap table 是一款基于 Bootstrap 的 jQuery 表格插件, ...
- 安装PL/SQL客户端来访问操作步骤
1 2 3.改变路径 4 5 6 7 8 9.选择注册机 10
- CoreDNS kubernetes 安装使用
kubernetes 以前是skydns 后面变为 dnsmasq,coredns 也是一个不错的工具 1. 准备环境 安装 kubernetes 配置 kubelet 的cluster-dns 2 ...
- C++输入流和输出流、缓冲区
一.C++输入流和输出流 输入和输出的概念是相对程序而言的. 键盘输入数据到程序叫标准输入,程序数据输出到显示器叫标准输出,标准输入和标准输出统称为标准I/O,文件的输入和输出叫文件I/O. cout ...
- CentOS上面搭建SVN服务器
1.安装svn sudo yum install subversion 查看安装位置 which svnserve 确认安装成功 svnserve --version 2.修改全局配置文件修改全局配置 ...
- POI 单元格
OI 单元格合并中的CellRangeAddress 参数: CellRangeAddress(int, int, int, int) 参数:起始行号,终止行号, 起始列号,终止列号 sheet.ad ...
- java图形化界面-------鼠标监听画圆----------使用匿名类
package com.aa; import java.awt.Color; import java.awt.Graphics; import java.awt.event.MouseAdapter; ...