KNN最近邻算法
算法概述
K最近邻(K-Nearest Neighbor,KNN)算法,是著名的模式识别统计学方法,在机器学习分类算法中占有相当大的地位。它是一个理论上比较成熟的方法。既是最简单的机器学习算法之一,也是基于实例的学习方法中最基本的,又是最好的文本分类算法之一。
基本思想
如果一个实例在特征空间中的K个最相似(即特征空间中最近邻)的实例中的大多数属于某一个类别,则该实例也属于这个类别。所选择的邻居都是已经正确分类的实例。
该算法假定所有的实例对应于N维欧式空间中的一个点。通过计算一个点与其他所有点之间的距离,取出与该点最近的K个点,然后统计这K个点里面所属分类比例最大的,则这个点属于该分类。
该算法涉及3个主要因素:实例集、距离或相似的衡量、k的大小。
一个实例的最近邻是根据标准欧氏距离定义的。更精确地讲,把任意的实例x表示为下面的特征向量:
(x1,x2,x3....,xn)其中xi表示为该实例的第i个属性。
基本思想
如果一个实例在特征空间中的K个最相似(即特征空间中最近邻)的实例中的大多数属于某一个类别,则该实例也属于这个类别。所选择的邻居都是已经正确分类的实例。
该算法假定所有的实例对应于N维欧式空间Ân中的点。通过计算一个点与其他所有点之间的距离,取出与该点最近的K个点,然后统计这K个点里面所属分类比例最大的,则这个点属于该分类。
该算法涉及3个主要因素:实例集、距离或相似的衡量、k的大小。
一个实例的最近邻是根据标准欧氏距离定义的。更精确地讲,把任意的实例x表示为下面的特征向量:
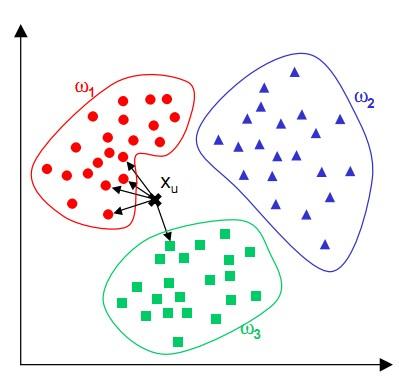
简单来说,KNN可以看成:有那么一堆你已经知道分类的数据,然后当一个新数据进入的时候,就开始跟训练数据里的每个点求距离,然后挑离这个训练数据最近的K个点看看这几个点属于什么类型,然后用少数服从多数的原则,给新数据归类。
KNN算法的决策过程
下图中有两种类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形,中间那个绿色的圆形是待分类数据:
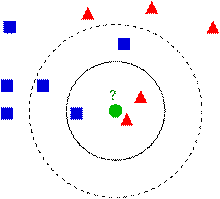
如果K=3,那么离绿色点最近的有2个红色的三角形和1个蓝色的正方形,这三个点进行投票,于是绿色的待分类点就属于红色的三角形。而如果K=5,那么离绿色点最近的有2个红色的三角形和3个蓝色的正方形,这五个点进行投票,于是绿色的待分类点就属于蓝色的正方形
距离加权最近邻算法
对k-最近邻算法的一个显而易见的改进是对k个近邻的贡献加权,根据它们相对查询点xq的距离,将较大的权值赋给较近的近邻。加权欧氏距离公式。在传统的欧氏距离中,各特征的权重相同,也就是认定各个特征对于分类的贡献是相同的,显然这是不符合实际情况的。同等的权重使得特征向量之间相似度计算不够准确, 进而影响分类精度。加权欧氏距离公式,特征权重通过灵敏度方法获得(根据业务需求调整,例如关键字加权、词性加权等)
如果使用按距离加权,那么允许所有的训练样例影响xq的分类事实上没有坏处,因为非常远的实例对(xq)的影响很小。考虑所有样例的惟一不足是会使分类运行得更慢。如果分类一个新的查询实例时考虑所有的训练样例,我们称此为全局(global)法。如果仅考虑最靠近的训练样例,我们称此为局部(local)法。
KNN的优缺点
(1)优点
①简单,易于理解,易于实现,无需参数估计,无需训练;
②精度高,对异常值不敏感(个别噪音数据对结果的影响不是很大);
③适合对稀有事件进行分类;
④特别适合于多分类问题(multi-modal,对象具有多个类别标签),KNN要比SVM表现要好.
(2)缺点
①对测试样本分类时的计算量大,空间开销大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本;
②可解释性差,无法给出决策树那样的规则;
③最大的缺点是当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进;
④消极学习方法。
对k-近邻算法的说明
按距离加权的k-近邻算法是一种非常有效的归纳推理方法。它对训练数据中的噪声有很好的鲁棒性,而且当给定足够大的训练集合时它也非常有效。注意通过取k个近邻的加权平均,可以消除孤立的噪声样例的影响。
问题一:近邻间的距离会被大量的不相关属性所支配。
应用k-近邻算法的一个实践问题是,实例间的距离是根据实例的所有属性(也就是包含实例的欧氏空间的所有坐标轴)计算的。这与那些只选择全部实例属性的一个子集的方法不同,例如决策树学习系统。
比如这样一个问题:每个实例由20个属性描述,但在这些属性中仅有2个与它的分类是有关。在这种情况下,这两个相关属性的值一致的实例可能在这个20维的实例空间中相距很远。结果,依赖这20个属性的相似性度量会误导k-近邻算法的分类。近邻间的距离会被大量的不相关属性所支配。这种由于存在很多不相关属性所导致的难题,有时被称为维度灾难(curse of dimensionality)。最近邻方法对这个问题特别敏感。
解决方法:当计算两个实例间的距离时对每个属性加权。
这相当于按比例缩放欧氏空间中的坐标轴,缩短对应于不太相关属性的坐标轴,拉长对应于更相关的属性的坐标轴。每个坐标轴应伸展的数量可以通过交叉验证的方法自动决定。
问题二:应用k-近邻算法的另外一个实践问题是如何建立高效的索引。因为这个算法推迟所有的处理,直到接收到一个新的查询,所以处理每个新查询可能需要大量的计算。
解决方法:目前已经开发了很多方法用来对存储的训练样例进行索引,以便在增加一定存储开销情况下更高效地确定最近邻。一种索引方法是kd-tree(Bentley 1975;Friedman et al. 1977),它把实例存储在树的叶结点内,邻近的实例存储在同一个或附近的结点内。通过测试新查询xq的选定属性,树的内部结点把查询xq排列到相关的叶结点。
Python实现KNN
import numpy as np class KNearestNeighbor(object):
def __init__(self, datas=None, targets=None, predict_sample=None, k=3):
self.datas = datas
self.targets = targets
self.predict_sample = predict_sample
self.k = k
self.dis = np.zeros(self.targets.shape)
self.distance()
self.k_dis = {}
self.predict_label = self.predict()
print(self.predict_label) def distance(self):
for i in range(len(self.targets)):
self.dis[i] = sum([x * x for x in (self.datas[i] - self.predict_sample)]) def predict(self):
loc = np.argsort(self.dis)[:self.k]
for i in range(len(loc)):
if self.targets[loc[i]] in self.k_dis.keys():
self.k_dis[self.targets[loc[i]]] += 1
else:
self.k_dis[self.targets[loc[i]]] = 1
key, value = self.targets[loc[0]], self.k_dis[self.targets[loc[0]]]
for k, v in self.k_dis.items():
if value < v:
key, value = k, v
return key
用python实现的knn代码处理一下sklearn中的iris数据集
#! /usr/bin/env python
# -*- coding:utf-8 -*-
import numpy as np
from sklearn.datasets import load_iris class KNearestNeighbor(object):
def __init__(self, datas=None, targets=None, predict_sample=None, k=3):
self.datas = datas
self.targets = targets
self.predict_sample = predict_sample
self.k = k
self.dis = np.zeros(self.targets.shape)
self.distance()
self.k_dis = {}
self.predict_label = self.predict()
print(self.predict_label) def distance(self):
for i in range(len(self.targets)):
self.dis[i] = sum([x * x for x in (self.datas[i] - self.predict_sample)]) def predict(self):
loc = np.argsort(self.dis)[:self.k]
for i in range(len(loc)):
if self.targets[loc[i]] in self.k_dis.keys():
self.k_dis[self.targets[loc[i]]] += 1
else:
self.k_dis[self.targets[loc[i]]] = 1
key, value = self.targets[loc[0]], self.k_dis[self.targets[loc[0]]]
for k, v in self.k_dis.items():
if value < v:
key, value = k, v
return key def main():
datas, targets = load_iris().data, load_iris().target
error_times = 0
for i in range(len(datas)):
predict_sample = datas[i]
knn = KNearestNeighbor(datas, targets, predict_sample)
print(targets[i])
print("***************")
if knn.predict_label != targets[i]:
error_times +=1
print("error times: ", error_times) if __name__ == '__main__':
main()
KNN最近邻算法的更多相关文章
- 【udacity】机器学习-knn最近邻算法
Evernote Export 1.基于实例的学习介绍 不同级别的学习,去除所有的数据点(xi,yi),然后放入一个数据库中,下次直接提取数据 但是这样的实现方法将不能进行泛化,这种方式只能简单的 ...
- 在opencv3中实现机器学习算法之:利用最近邻算法(knn)实现手写数字分类
手写数字digits分类,这可是深度学习算法的入门练习.而且还有专门的手写数字MINIST库.opencv提供了一张手写数字图片给我们,先来看看 这是一张密密麻麻的手写数字图:图片大小为1000*20 ...
- KNN(k-nearest neighbor的缩写)又叫最近邻算法
KNN(k-nearest neighbor的缩写)又叫最近邻算法 机器学习笔记--KNN算法1 前言 Hello ,everyone. 我是小花.大四毕业,留在学校有点事情,就在这里和大家吹吹我们的 ...
- 【算法】K最近邻算法(K-NEAREST NEIGHBOURS,KNN)
K最近邻算法(k-nearest neighbours,KNN) 算法 对一个元素进行分类 查看它k个最近的邻居 在这些邻居中,哪个种类多,这个元素有更大概率是这个种类 使用 使用KNN来做两项基本工 ...
- 最近邻算法(KNN)
最近邻算法: 1.什么是最近邻是什么? kNN算法全程是k-最近邻算法(k-Nearest Neighbor) kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数数以一个类型别 ...
- 机器学习---K最近邻(k-Nearest Neighbour,KNN)分类算法
K最近邻(k-Nearest Neighbour,KNN)分类算法 1.K最近邻(k-Nearest Neighbour,KNN) K最近邻(k-Nearest Neighbour,KNN)分类算法, ...
- k最近邻算法(kNN)
from numpy import * import operator from os import listdir def classify0(inX, dataSet, labels, k): d ...
- 12、K最近邻算法(KNN算法)
一.如何创建推荐系统? 找到与用户相似的其他用户,然后把其他用户喜欢的东西推荐给用户.这就是K最近邻算法的分类作用. 二.抽取特征 推荐系统最重要的工作是:将用户的特征抽取出来并转化为度量的数字,然后 ...
- PCB 加投率计算实现基本原理--K最近邻算法(KNN)
PCB行业中,客户订购5000pcs,在投料时不会直接投5000pcs,因为实际在生产过程不可避免的造成PCB报废, 所以在生产前需计划多投一定比例的板板, 例:订单 量是5000pcs,加投3%,那 ...
随机推荐
- 在 Angularjs 中$state.go 如何传递参数
在目标页面规定接受的参数: .state('app.AttendanceEditFixed', { url: '/AttendanceEditFixed', params: {'id': null,' ...
- Shell 语法之用户输入
bash shell 提供了一些不同的方法从用户处获取数据,这些方法包括命令行参数.命令行选项和直接读取键盘输入. 命令行参数 bash shell 将在命令行中输入的所有参数赋值给一些特殊变量,称为 ...
- N!中素因子p的个数 【数论】
求N!中素因子p的个数,也就是N!中p的幂次 公式为:cnt=[n/p]+[n/p^2]+[n/p^3]+...+[n/p^k]; 例如:N=12,p=2 12/2=6,表示1~12中有6个数是2的倍 ...
- eureka添加security验证之后,client注册失败
高版本,以下配置已弃用 security: basic: enabled: true 所以需要自定义security配置开启basic认证,参考我的配置类 @Configuration @Enable ...
- javascript基础:事件
事件: 概念:某些组件被执行了某些操作后,触发某些代码的执行 * 事件:某些操作,如:单击,双击,键盘按下了,鼠标移动了 * 事件源:组件.如:按钮 文本输入框.... * 监听器:代码 * ...
- Layui表格数据重新载入_表格搜索
- useradd -M -s /sbin/nologin mysql -g mysql 报错 Creating mailbox file
由于之前使用以下命令删除了mysql账户 userdel mysql groupdel mysql #如果删除了mysql用户,对应的组也会被删除(只有一个用户的情况下) 执行以下命令时报错 ...
- canvas用2d渲染出3d的感觉
好久没有写博客了,深究动画其实也就是setTimeout setInterval requestAnimationFrame很多人可能不熟悉requestAnimationFrame但是事实上和set ...
- 学习JDK1.8集合源码之--LinkedHashMap
1. LinkedHashMap简介 LinkedHashMap继承自HashMap,实现了Map接口. LinkedHashMap是HashMap的一种有序实现(多态,HashMap的有序态),可以 ...
- Vue. 之 Element table 高度自适应
Vue. 之 Element table 高度自适应 使用vue创建table后,其高度自适应浏览器高度. 在创建的 el-table 中添加:height属性,其值为一个变量(tableHeight ...