python——pandas基础
参考:
- 实验楼:https://www.shiyanlou.com/courses/1091/learning/?id=6138
- 《利用python进行数据分析》
- pandas简介
- Pandas 是基于 NumPy 的一种数据处理工具,该工具为了解决数据分析任务而创建。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的函数和方法。
- Pandas 的数据结构:Pandas 主要有 Series(一维数组),DataFrame(二维数组),Panel(三维数组),Panel4D(四维数组),PanelND(更多维数组)等数据结构。其中 Series 和 DataFrame 应用的最为广泛。
- Pandas经常和NumPy、SciPy、matplotlib工具一同使用。
2. Series
2.1 何谓Series
- Series是一种一维的数组型对象,它包含一个值序列(与NumPy类似)和相应的数据标签(索引(index))。
2.2 Series的创建方法
- 通过list创建
import pandas as pd
obj = pd.Series(list(''))
- 通过ndarray创建
import numpy as np arr = np.random.randn(5)
obj = pd.Series(arr)
- 通过dict创建
dic = {'a':1,'b':2,'c':3,'d':4}
obj = pd.Series(dic) #当把字典传入Series构造时,产生的Series的索引将是排序好的字典的键(key)
2.3 Series基本操作
- 自定义Series索引
index = [1,2,3,4] #自定义索引
obj = pd.Series(list('abcd'), index=index)
- 修改Series索引
obj.index = ['A','B','C','D']
- 通过index修改指定元素
obj[1] = 'A' #1是指索引,而不是切片,如果索引是字符串要记得加引号,如obj['a'] = A
- 通过指定index删除元素
obj = pd.Series([1,2,3,4], index=list('abcd'))
obj.drop('a')
- Series拼接
obj1 = pd.Series([1,2,3,4], index=list('abcd'))
obj2 = pd.Series([5,6,7,8], index=list('ABCD'))
obj3 = obj2.append(obj1) #将obj1拼接到obj2后
- Series查找元素
obj_find = obj1['a']
- Series切片操作
obj_slice = obj1[:3] #提取obj1前三个元素
- Series的name属性:Series对象自身和index均有name属性
>>>obj1.name = 'Series'
>>>obj1.index.name = 'obj1_index'
>>>obj1
obj1_index
a 1
b 2
c 3
d 4
Name: Series, dtype: int64
- NaN值检查
pd.isnull(obj1) #值为空则显示True,反之False
pd.notnull(obj1) #与isnull结果相反 #实例方法
obj1.isnull()
obj1.notnull()
- Series运算
#加法
obj1.add(obj2) #Series 的加法运算是按照索引计算,如果索引不同则填充为 `NaN`
#减法
obj1.sub(obj2) #Series的减法运算是按照索引对应计算,如果不同则填充为 `NaN`
#乘法
obj1.mul(obj2) #Series 的乘法运算是按照索引对应计算,如果索引不同则填充为 `NaN`
#除法
obj1.div(obj2) #Series 的除法运算是按照索引对应计算,如果索引不同则填充为 `NaN`
#中位数
obj1.median()
#求和
obj1.sum()
#最大值
obj1.max()
#最小值
obj1.min()
3.DataFrame
3.1 DataFrame简介
- DataFrame表示的是矩阵数据表,包含以排序的列集合,每一列可以是不同类型(数值,字符串,布尔值等)。DataFrame既有行索引(index)右有列索引(columns)。DataFrame可视为一个共享相同索引的Series字典。
3.2 创建DataFrame的部分方法
- 通过包含等长度列表创建
index = pd.date_range('today', periods=7) #定义时间序列作为index
columns = list('ABCDE') #定义列索引columns
arr = np.random.randn(7,5)
df = pd.DataFrame(arr, index=index, columns=columns)
df
- 通过字典数组创建
data = {'name': ['Bob', 'Howie', 'Davie', 'Lisa', 'John', 'June'],
'age': [20, 21, 22, 23, 24, 25],
'gender': ['boy', 'boy', 'boy', 'girl', 'boy', 'girl']}
index = list(range(1,7))
df = pd.DataFrame(data, index=index)
df
3.3 DataFrame基本操作
- 查看DataFrame数据类型
df.dtypes
- 预览DataFrame数据前X行,对于数据量特别大时很有帮助
df.head() #默认为前5行
- 预览DataFrame数据后X行
df.tail() #默认为后5行
- 查看DataFrame数据的行和列索引
df.index #行索引
df.columns #列索引
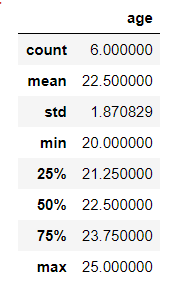
- 查看DataFrame数据的数值
df.values
- 查看DataFrame数据的统计数据
df.describe()
- DataFrame的name属性
df.index.name = 'df_index_name' #设置index名称
df.columns.name = 'de_columns_name' #设置columns名称
- DataFrame转置
df.T
- 按列排序
df.sort_values(by='age') #指定按 age大小进行排序,默认为升序
df.sort_values(by='age', ascending='False') #按age降序排列
- DataFrame切片,行级
df[1:4] #选取前3行元素
- DataFrame通过列标签查询,列级
df['age']
df.age #两者等价 #多列查询
df[['name', 'age']] #注意放在一个list中
- 对DataFrame通过iloc(整数标签)位置查询
df.iloc[1:3,1:2] #查询2.3行的第2列,注意和行查询有所不同,iloc前不包含,后包含.df[1:3]查询1.2行
- DataFrame特殊属性loc(轴标签)选取,列级
df.loc[1] #注意1代表index值,如果是字符需要加引号,如df.loc['one']
- 重新给某一列赋值
df['age'] = range(30,36) #将年龄改为30-35
df
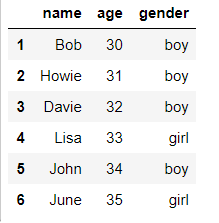
- 35. DataFrame 副本拷贝
df_copy = df.copy()
- 删除DataFrame的某一列,列级
del df_copy['name']
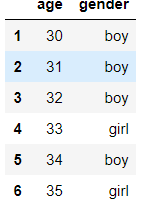
- 删除DataFrame行或列元素,可指定
#根据列删除
df_copy.drop(['gender', 'age'], axis=1) #同时删除gender和age列,axis=1代表按列处理 #根据行删除
df_copy.drop([1,2,3], axis=0) #同时删除第1.2.3行数据,axis=0代表按行处理
- 添加新的一列,列级
df['city'] = ['Beijing', 'Shanghai', 'Shenzhen', 'Guangzhou', 'Chengdu', 'HongKong'] #注意添加的列的行数要与原数据行数一致
df
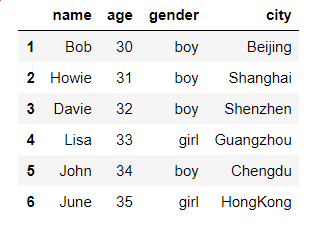
- 修改某一个数据
df[1, 'age'] = 18 #修改第index为1,column为'age'的值为18
- DataFrame运算
#求指定列的平均数
df['age'].mean() #求指定列的和
df['age'].sum() #求指定列的最大最小值
df['age'].max()
df['age'].min()
- 缺失值操作
#对缺失值进行填充
df.fillna(value=1) #删除存在缺失值的行
df.dropna('how'=any, axis=0) #只要某行有nan值即删除
df.dropna('how'=all, axis=0) #只有当某一行均为nan值时才删除此行
- DataFrame 按指定列对齐
left = pd.DataFrame({'key': ['foo1', 'foo2'], 'one': [1, 2]})
right = pd.DataFrame({'key': ['foo2', 'foo3'], 'two': [4, 5]})
print(left)
print(right)
# 按照 key 列对齐连接,只存在 foo2 相同,所以最后变成一行
pd.merge(left, right, on='key')

- DataFrame文件操作
#CSV文件写入
df.to_csv('df.csv')
print('写入成功') #CSV文件读取
df_csv_read = pd.read_csv('df.csv') #Excel文件写入
df.to_excel('df.xlsx', sheet_name='Sheet1') #Excel文件读取
df_excel_read = pd.read_excel('df.xlsx', 'Sheet1', index_col=None, na_values=['NA'])
2019-08-03
00:28:11
python——pandas基础的更多相关文章
- python pandas 基础理解
其实每一篇博客我都要用很多琐碎的时间片段来学完写完,每次一点点,用到了就学一点,学一点就记录一点,要用上好几天甚至一两个礼拜才感觉某一小类的知识结构学的差不多了. Pandas 是基于 NumPy 的 ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
第1节 pandas 回顾 第2节 读写文本格式的数据 第3节 使用 HTML 和 Web API 第4节 使用数据库 第5节 合并数据集 第6节 重塑和轴向旋转 第7节 数据转换 第8节 字符串操作 ...
- Pandas基础学习与Spark Python初探
摘要:pandas是一个强大的Python数据分析工具包,pandas的两个主要数据结构Series(一维)和DataFrame(二维)处理了金融,统计,社会中的绝大多数典型用例科学,以及许多工程领域 ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
- python学习笔记(四):pandas基础
pandas 基础 serise import pandas as pd from pandas import Series, DataFrame obj = Series([4, -7, 5, 3] ...
随机推荐
- docker部署一个简单的mian.py项目文件
安装docker yum install -y docker 启动docker systemctl start docker 查询可安装的Python版本,默认centos python 2.7 ...
- JavaScript跨域方式总结
1. jsonp请求 jsonp的原理是利用 script 标签的跨域特性,可以不受限制地从其他域中加载资源,类似的标签还有 img. 缺点:只支持GET请求而不支持POST等其他类型的HTTP请求. ...
- 使用sass
sass安装 compass安装 1.sass 需要安装ruby,然后通过gem安装sass. 2. less有想=两种安装方: 客户端安装: 引入less.js,然后就可以直接用.less文件 &l ...
- Shell内置命令 eval
- teb教程10 teb questions
http://wiki.ros.org/teb_local_planner/Tutorials/Frequently%20Asked%20Questions
- Vuex的管理员Module(实战篇)
Module按照官方来的话,对于新手可能有点难以接受,所以想了下,决定干脆多花点时间,用一个简单的例子来讲解,顺便也复习一下之前的知识点. 首先还是得先了解下 Module 的背景.我们知道,Vuex ...
- Comet Contest#11 F arewell(DAG计数+FWT子集卷积)
传送门. 题解: 4月YY集训时做过DAG计数,和这个基本上是一样的,但是当时好像直接暴力子集卷积,不然我省选时不至于不会,这个就多了个边不选的概率和子集卷积. DAG计数是个套路来的,利用的是DAG ...
- js 将字符串当作js表达式执行方法
听同事说了一个需求.他有一个数据对象obj,接口会给他返回一个索引key,这个key长度不固定,根据这个key去修改obj对应的值. 举个例子: let obj={"level1" ...
- BulkLoad加载本地文件到HBase表
BulkLoad加载文件到HBase表 1.功能 将本地数据导入到HBase中 2.原理 BulkLoad会将tsv/csv格式的文件编程hfile文件,然后再进行数据的导入,这样可以避免大量数据导入 ...
- SQL server 数据库安装
一.安装 1.点击setup双击 2.选择第一条-安装一个新的SQLserver 3.一路点击next 4.product Key-选择第一个:试用版 5.setup Role-选择所有 6.sell ...