数据库之redis篇(3)—— Python操作redis
虽然前面两篇已经说了redis的一些配置安装什么的,篇幅有点长,可能看完了也不知道怎么操作,这里再浓缩一下:
什么是redis
redis完全开源免费的,遵守BSD协议,是一个高性能的非关系型key-value数据库,
redis特点:
- redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用,相比memcache,redis可以持久化存储,这是memcache没有的。
- redis支持五种数据类型。
- redis支持数据库备份。
redis优势:
- redis性能极高,读的速度是110000次/s,写的速度是81000次/s。
- redis支持数据类型:String,Lists,Hashes,Sets以及Ordered Sets。
- redis的所有操作都是原子性的,多个操作支持事物,即MULTI和EXEC指令包起来,但是多个事物来说不是原子性的,mysql的多个事物是原子性的。
- redis支持publish/subscribe,通知,key过期等等特性。
redis 配置
可以通过redis-cli 进入交互模式,使用config命令查看或设置配置项。也可以进入配置文件用vim编辑器进行修改
redis简单使用
启动服务端:
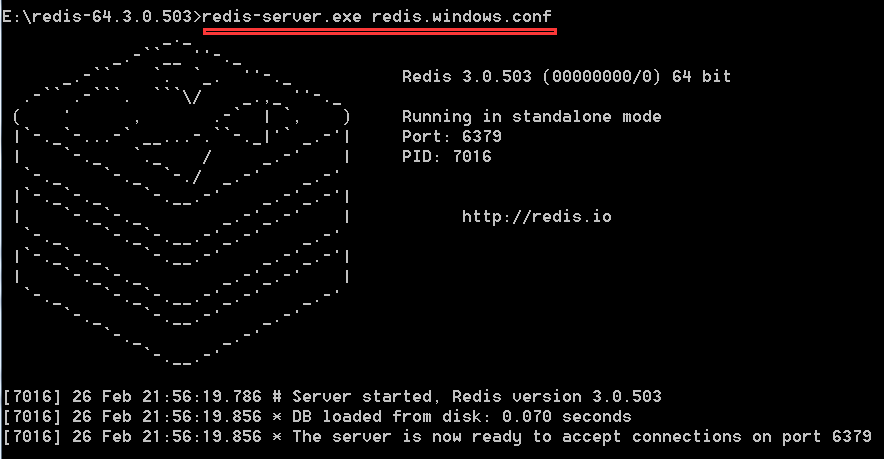
启动客户端,keys * 查看当前数据库里存储的key-value
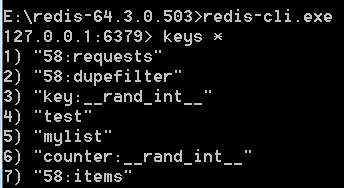
查看数据:lrange key名 0 -1

Python操作redis
安装redis库

连接redis,基本操作
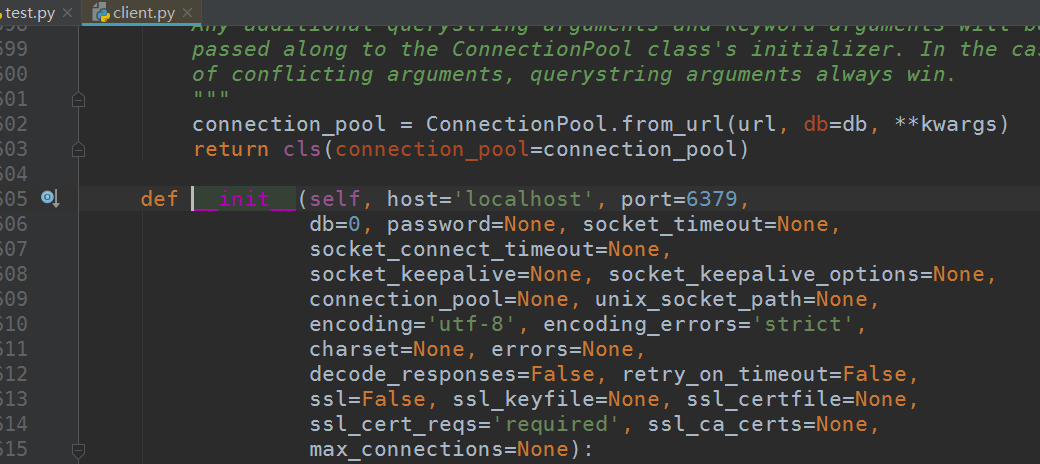
先看redis的源码,实例化Redis对象时,提供了以下的参数
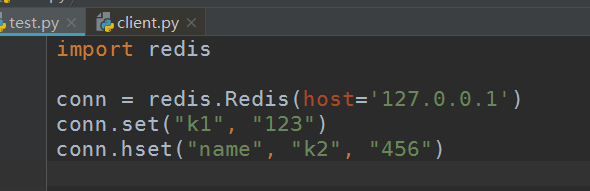
连接并添加数据
连接时根据当前的开发环境来设置参数,我这里的是127.0.0.1,端口就是6379,密码为空,由上面的源码得知,Redis默认就是这些参数,所以我只设置host就行了。自行根据自己的开发环境设置参数
set方法是两个参数,分别是key-value,hset是三个参数,第一个是数据库的key值,第二个和第三个是字典的key和value
在运行之前数据库的数据有这些:
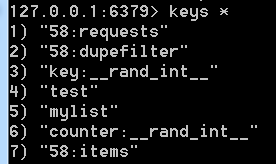
运行,然后在终端查看:

查询,利用get和hget获取值
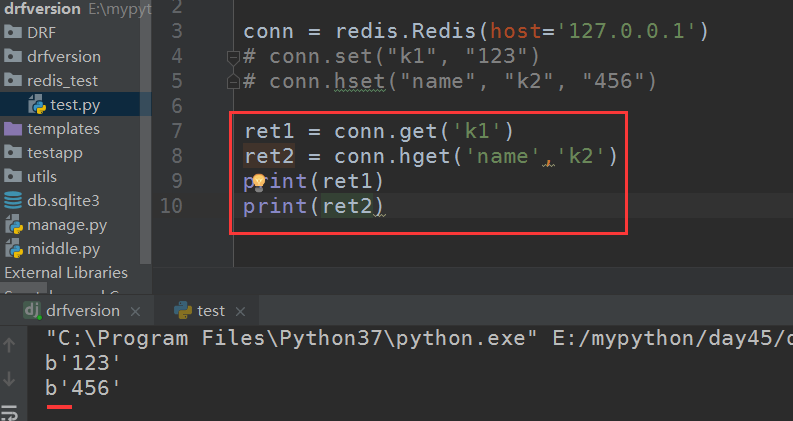
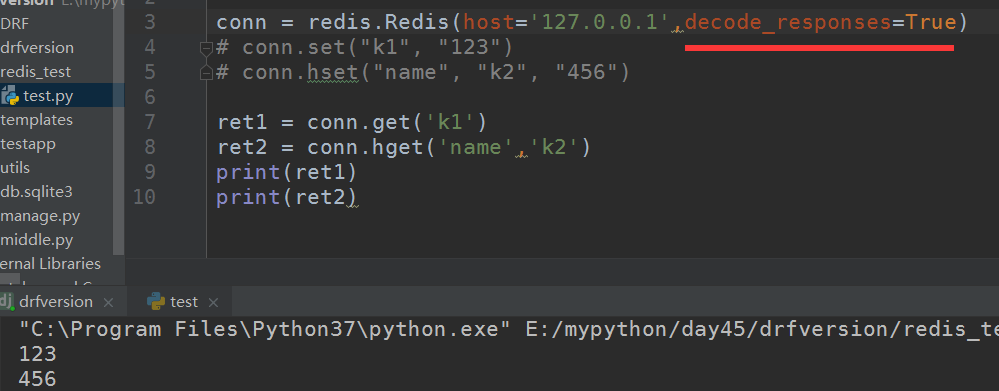
发现值是bytes格式,在连接的时候可以加个参数让取出来的值都是字符串:decode_responses=True
刚才的hset是可以再value那一层加个字典,如果还想套一层,可以用hmset:

取值,用hmget取出来是一个列表形式,内容时改字典的value值,hgetall就是全部拿出来了

redis连接池
使用connectionpool来管理对一个redis server的所有连接,避免每次建立、释放连接的资源开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数传给Redis实例,这样就可以实现多个Redis实例共享一个连接池
如下,后面的操作其实都是一样的了

当然你可以用max_connections设置最大连接数:

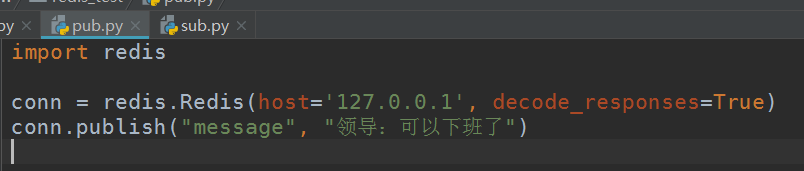
发布者订阅者模型
发布者:
订阅者:
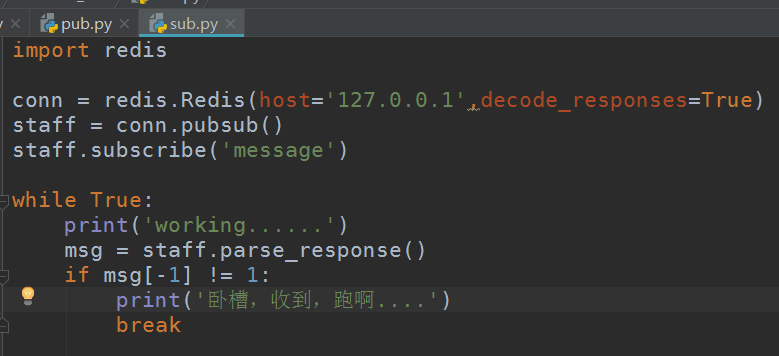
先启动多个订阅者:

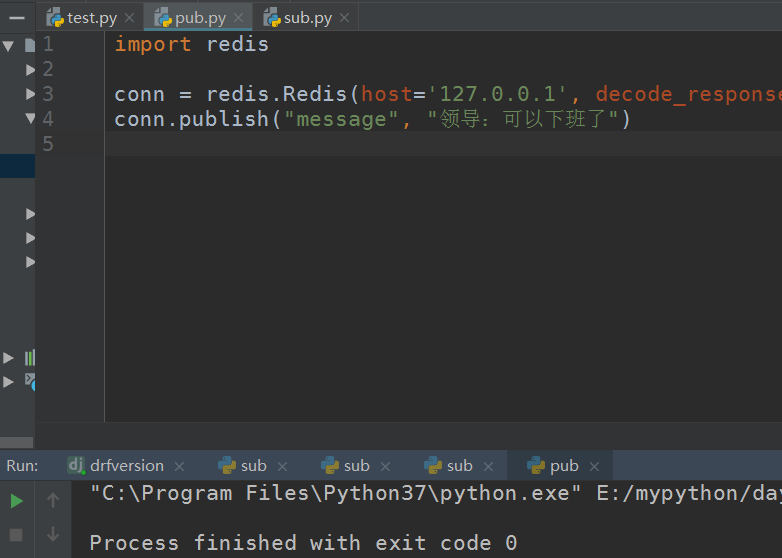
启动发布者:
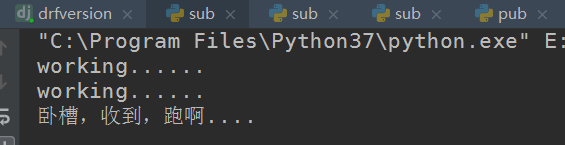
订阅者返回结果:
三个sub订阅者返回的结果都是如下:
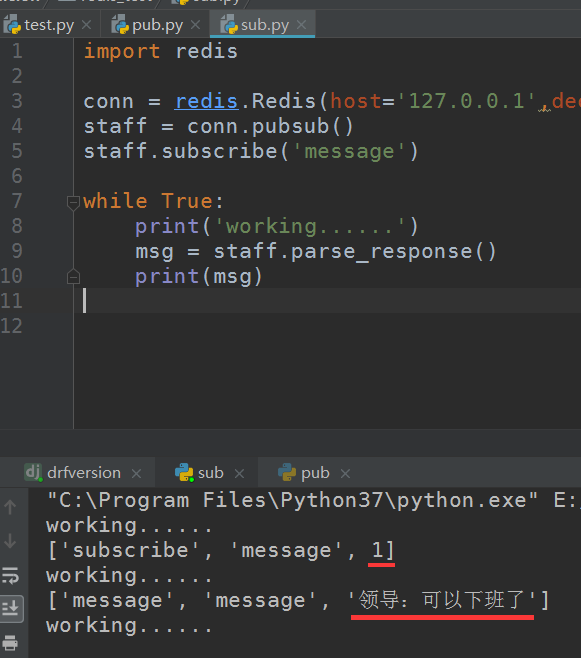
那么这parse_response到底是什么呢,打印看看,在未接受到数据之前,它默认是1,接收到数据之后就是接收的数据
有没有发现其实比mysql还简单很多
常用方法:
set(name, value, ex=None, px=None, nx=False, xx=False) #在Redis中设置值,默认是不存在则创建,存在则修改 参数: ex,过期时间(秒)过期后值None px,过期时间(毫秒) nx,如果设置为True,则只有name不存在时,当前set操作才执行 xx,如果设置为True,则只有name存在时,当前set操作才执行 # 注:ex,px,nx,xx可以跟在命令后面 eg: setnx 表示只能创建 hash命令一样适用 get(key) 获取key的值 mset(*args, **kwargs) 批量设置值 mget(key, *args) hset(name, key, value) 增加单个 不存在则创建 hget(name, key) 获取单个 hmset(name, mapping) 批量增加 mapping为字典 hgetall(name) 获取name对应hash的所有键值 hlen(name) 获取name对应的hash中键值对的个数 hkeys(name) 获取name对应的hash中所有的key的值 hvals(name) 获取name对应的hash中所有的value的值 hexists(name, key) 检查name对应的hash是否存在当前传入的key hdel(name,*keys) 将name对应的hash中指定key的键值对删除 hscan_iter(name, match=None, count=None) 利用yield封装hscan创建生成器,实现分批去redis中获取数据 参数: match,匹配指定key,默认None 表示所有的key count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 lpush(name,values) 在name对应的list中左边添加元素 没有就新建 llen(name) 获取name对应的列表长度 lrang(name, index1, index2)按照index切片取出name对应列表里值 lpushx(name, value) 只能添加不能新建 linsert(name, where, refvalue, value)) 在name对应的列表的某一个值前或后插入一个新值 参数: name,redis的name where,BEFORE或AFTER refvalue,标杆值,即:在它前后插入数据 value,要插入的数据 lset(name, index, value) 给指定索引修改值 lrem(name, value, num) 在name对应的list中删除指定的值 参数: name,redis的name value,要删除的值 num, num=0,删除列表中所有的指定值; num=2,从前到后,删除2个; num=1,从前到后,删除左边第1个 num=-2,从后向前,删除2个 lindex(name, index) 在name对应的列表中根据索引获取列表元素
当然redis还有支持django的数据库模块,pip install django-redis即可
数据库之redis篇(3)—— Python操作redis的更多相关文章
- [ecmagent][redis学习][1初识redis] redis安装+redis快速教程+python操作redis
# redis安装 # redis安装教程 -- 服务器(ubuntu)安装redis服务 sudo apt-get install redis-server -- 源码安装 -- $ wget ht ...
- Python操作Redis、Memcache、RabbitMQ、SQLAlchemy
Python操作 Redis.Memcache.RabbitMQ.SQLAlchemy redis介绍:redis是一个开源的,先进的KEY-VALUE存储,它通常被称为数据结构服务器,因为键可以包含 ...
- python操作redis数据
一.环境安装 1.redispy安装 (automatic) C:\Users\Administrator>pip install redis 2.检测是否安装成功 (automatic) C: ...
- python操作Redis安装、支持存储类型、普通连接、连接池
一.python操作redis安装和支持存储类型 安装redis模块 pip3 install redis 二.Python操作Redis之普通连接 redis-py提供两个类Redis和Strict ...
- Python 操作Redis 转载篇
Python操作Redis数据库 连接数据库 StrictRedis from redis import StrictRedis # 使用默认方式连接到数据库 redis = StrictRedis( ...
- Python之路【第十篇】Python操作Memcache、Redis、RabbitMQ、SQLAlchemy、
Memcached Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载.它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态.数据库驱动网站的速度 ...
- python操作三大主流数据库(14)python操作redis之新闻项目实战②新闻数据的展示及修改、删除操作
python操作三大主流数据库(14)python操作redis之新闻项目实战②新闻数据的展示及修改.删除操作 项目目录: ├── flask_redis_news.py ├── forms.py ├ ...
- python操作三大主流数据库(12)python操作redis的api框架redis-py简单使用
python操作三大主流数据库(12)python操作redis的api框架redis-py简单使用 redispy安装安装及简单使用:https://github.com/andymccurdy/r ...
- Python学习笔记(五)之Python操作Redis、mysql、mongodb数据库
操作数据库 一.数据库 数据库类型主要有关系型数据库和菲关系型数据库. 数据库:用来存储和管理数的仓库,数据库是通过依据“数据结构”将数据格式化,以记录->表->库的关系存储.因此数据查询 ...
随机推荐
- spring+jotm+ibatis+mysql实现JTA分布式事务
1 环境 1.1 软件环境 spring-framework-2.5.6.SEC01-with-dependencies.zip ibatis-2.3.4 ow2-jotm-dist-2.1.4-b ...
- Linux时间子系统之四:定时器的引擎:clock_event_device
早期的内核版本中,进程的调度基于一个称之为tick的时钟滴答,通常使用时钟中断来定时地产生tick信号,每次tick定时中断都会进行进程的统计和调度,并对tick进行计数,记录在一个jiffies变量 ...
- OAuth 2 开发人员指南
这是支持OAuth2.0的用户指南.对于OAuth1.0,一切都是不同的,所以看它的用户指南. 本用户指南分为两个部分,第一部分是OAuth2.0提供端(OAuth 2.0 Provider),第二部 ...
- app的安装与卸载测试点
安装 1)软件在不同操作系统(Palm OS.Symbian.Linux.Android.iOS.Black Berry OS .Windows Phone )下安装是否正常. 2)软件安装后的是否能 ...
- 关于bootstrap两个模态框的问题
今天不知道为什么,其中一个模态框无法正确触发,但是将两个模态框在body里的顺序调一下就都可以正确触发.
- JAVAEE——Mybatis第二天:输入和输出映射、动态sql、关联查询、Mybatis整合spring、Mybatis逆向工程
1. 学习计划 1.输入映射和输出映射 a) 输入参数映射 b) 返回值映射 2.动态sql a) If标签 b) Where标签 c) Sql片段 d) Foreach标签 3.关联查询 a) 一对 ...
- 求第n个丑数
参考http://www.cppblog.com/zenliang/articles/131094.html 什么是因子:因子*因子=乘积数如果一个数是丑数,那么这个数是2,3,5的乘积的结果.比如: ...
- 获取具有指定扩展数据的所有实体的Id,并存入Id数组中
AcDbObjectIdArray ObtainEntId(){ //获取块表 AcDbBlockTable *pBlkTbl; acdbHostApplicationServices()->w ...
- bzoj4904 [Ctsc2017]最长上升子序列
我们发现他让求的东西很奇怪,于是通过某D开头定理,我们转化为前m位的序列用k个不上升子序列最多能覆盖多少.数据范围小的时候可以网络流做,但是这道题显然不支持网络流的复杂度.然后有一个奇怪的东西叫杨氏矩 ...
- ZOJ_2314_Reactor Cooling_有上下界可行流模板
ZOJ_2314_Reactor Cooling_有上下界可行流模板 The terrorist group leaded by a well known international terroris ...