理解滑动平均(exponential moving average)
1. 用滑动平均估计局部均值
滑动平均(exponential moving average),或者叫做指数加权平均(exponentially weighted moving average),可以用来估计变量的局部均值,使得变量的更新与一段时间内的历史取值有关。
变量$v$在$t$时刻记为$v_t$,$\theta_t$为变量$v$在$t$时刻的取值,即在不使用滑动平均模型时$v_t = \theta_t$,在使用滑动平均模型后,$v_t$的更新公式如下:
\begin{equation} v_t = \beta*v_{t-1} + (1 - \beta) * \theta_t \end{equation}
上式中,$\beta \in [0,1)$。$\beta = 0$ 相当于没有使用滑动平均。
假设起始$v_0= 0$,$\beta = 0.9$,之后每个时刻,依次对变量$v$进行赋值,不使用滑动平均和使用滑动平均结果如下:
表 1
| t |
不使用滑动平均模型,即给$v$直接赋值$\theta$ |
使用滑动平均模型,按照公式(1)更新$v$ |
使用滑动平均模型,按照公式(2)更新$v$ |
| 0 | 0 | / | / |
| 1 | 10 | 1 | 10 |
| 2 | 20 | 2.9 | 13.6842 |
| 3 | 10 | 3.61 | 13.3210 |
| 4 | 0 | 3.249 | 9.4475 |
| 5 | 10 | 3.9241 | 9.5824 |
| 6 | 20 | 5.53169 | 11.8057 |
| 7 | 30 | 7.978521 | 15.2932 |
| 8 | 5 | 7.6806689 | 13.4859 |
| 9 | 0 | 6.91260201 | 11.2844 |
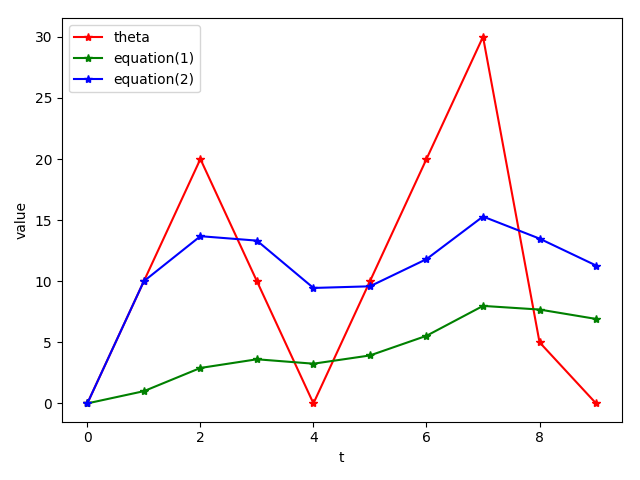
图 1:三种变量更新方式
Andrew Ng在Course 2 Improving Deep Neural Networks中讲到,$t$时刻变量$v$的滑动平均值大致等于过去$1/(1 - \beta)$个时刻$\theta$值的平均。这个结论在滑动平均起始时相差比较大,所以有了Bias correction,将$v_t$除以$(1 - \beta^t)$修正对均值的估计。
加入了Bias correction后,$v_t$更新公式如下:
\begin{equation} v_t = \frac{\beta*v_{t-1} + (1 - \beta) * \theta_t}{1 - \beta^t} \end{equation}
$t$越大,$1-\beta^t$越接近1,则公式(1)和(2)得到的结果将越来越近。
当$\beta$越大时,滑动平均得到的值越和$\theta$的历史值相关。如果$\beta = 0.9$,则大致等于过去10个$\theta$值的平均;如果$\beta = 0.99$,则大致等于过去100个$\theta$值的平均。
滑动平均的好处:
占内存少,不需要保存过去10个或者100个历史$\theta$值,就能够估计其均值。(当然,滑动平均不如将历史值全保存下来计算均值准确,但后者占用更多内存和计算成本更高)
2. TensorFlow中使用滑动平均来更新变量(参数)
滑动平均可以看作是变量的过去一段时间取值的均值,相比对变量直接赋值而言,滑动平均得到的值在图像上更加平缓光滑,抖动性更小,不会因为某次的异常取值而使得滑动平均值波动很大,如图 1所示。
TensorFlow 提供了 tf.train.ExponentialMovingAverage 来实现滑动平均。在初始化 ExponentialMovingAverage 时,需要提供一个衰减率(decay),即公式(1)(2)中的$\beta$。这个衰减率将用于控制模型的更新速度。ExponentialMovingAverage 对每一个变量(variable)会维护一个影子变量(shadow_variable),这个影子变量的初始值就是相应变量的初始值,而每次运行变量更新时,影子变量的值会更新为:
\begin{equation} \mbox{shadow_variable} = \mbox{decay} * \mbox{shadow_variable} + (1 - \mbox{decay}) * \mbox{variable} \end{equation}
公式(3)中的 shadow_variable 就是公式(1)中的$v_t$,公式(3)中的 variable 就是公式(1)中的$\theta_t$,公式(3)中的 decay 就是公式(1)中的$\beta$。
公式(3)中,decay 决定了影子变量的更新速度,decay 越大影子变量越趋于稳定。在实际运用中,decay一般会设成非常接近1的数(比如0.999或0.9999)。为了使得影子变量在训练前期可以更新更快,ExponentialMovingAverage 还提供了 num_updates 参数动态设置 decay 的大小。如果在初始化 ExponentialMovingAverage 时提供了 num_updates 参数,那么每次使用的衰减率将是:
\begin{equation} min\{\mbox{decay}, \frac{1 + \mbox{num_updates}}{10 + \mbox{num_updates}}\} \end{equation}
这一点其实和Bias correction很像。
TensorFlow 中使用 ExponentialMovingAverage 的例子:code
3. 滑动平均为什么在测试过程中被使用?
滑动平均可以使模型在测试数据上更健壮(robust)。“采用随机梯度下降算法训练神经网络时,使用滑动平均在很多应用中都可以在一定程度上提高最终模型在测试数据上的表现。”
对神经网络边的权重 weights 使用滑动平均,得到对应的影子变量 shadow_weights。在训练过程仍然使用原来不带滑动平均的权重 weights,不然无法得到 weights 下一步更新的值,又怎么求下一步 weights 的影子变量 shadow_weights。之后在测试过程中使用 shadow_weights 来代替 weights 作为神经网络边的权重,这样在测试数据上效果更好。因为 shadow_weights 的更新更加平滑,对于随机梯度下降而言,更平滑的更新说明不会偏离最优点很远;对于梯度下降 batch gradient decent,我感觉影子变量作用不大,因为梯度下降的方向已经是最优的了,loss 一定减小;对于 mini-batch gradient decent,可以尝试滑动平均,毕竟 mini-batch gradient decent 对参数的更新也存在抖动。
设$\mbox{decay} = 0.999$,一个更直观的理解,在最后的1000次训练过程中,模型早已经训练完成,正处于抖动阶段,而滑动平均相当于将最后的1000次抖动进行了平均,这样得到的权重会更加robust。
References
Course 2 Improving Deep Neural Networks by Andrew Ng
《TensorFlow实战Google深度学习框架》 4.4.3
理解滑动平均(exponential moving average)的更多相关文章
- (转)理解滑动平均(exponential moving average)
转自:理解滑动平均(exponential moving average) 1. 用滑动平均估计局部均值 滑动平均(exponential moving average),或者叫做指数加权平均(exp ...
- EMA计算的C#实现(c# Exponential Moving Average (EMA) indicator )
原来国外有个源码(TechnicalAnalysisEngine src 1.25)内部对EMA的计算是: var copyInputValues = input.ToList(); for (int ...
- (转)滑动平均法、滑动平均模型算法(Moving average,MA)
原文链接:https://blog.csdn.net/qq_39521554/article/details/79028012 什么是移动平均法? 移动平均法是用一组最近的实际数据值来预测未来一期或几 ...
- 一文详解滑动平均法、滑动平均模型法(Moving average,MA)
任何关于算法.编程.AI行业知识或博客内容的问题,可以随时扫码关注公众号「图灵的猫」,加入”学习小组“,沙雕博主在线答疑~此外,公众号内还有更多AI.算法.编程和大数据知识分享,以及免费的SSR节点和 ...
- [leetcode]346. Moving Average from Data Stream滑动窗口平均值
Given a stream of integers and a window size, calculate the moving average of all integers in the sl ...
- Tensorflow滑动平均模型tf.train.ExponentialMovingAverage解析
觉得有用的话,欢迎一起讨论相互学习~Follow Me 移动平均法相关知识 移动平均法又称滑动平均法.滑动平均模型法(Moving average,MA) 什么是移动平均法 移动平均法是用一组最近的实 ...
- 『TensorFlow』滑动平均
滑动平均会为目标变量维护一个影子变量,影子变量不影响原变量的更新维护,但是在测试或者实际预测过程中(非训练时),使用影子变量代替原变量. 1.滑动平均求解对象初始化 ema = tf.train.Ex ...
- tensorflow入门笔记(二) 滑动平均模型
tensorflow提供的tf.train.ExponentialMovingAverage 类利用指数衰减维持变量的滑动平均. 当训练模型的时候,保持训练参数的滑动平均是非常有益的.评估时使用取平均 ...
- deep_learning_Function_tf.train.ExponentialMovingAverage()滑动平均
近来看batch normalization的代码时,遇到tf.train.ExponentialMovingAverage()函数,特此记录. tf.train.ExponentialMovingA ...
随机推荐
- 连接Redis后执行命令错误 MISCONF Redis is configured to save RDB snapshots
今天在redis中执行setrange name 1 chun 命令时报了如下错误提示: (error) MISCONF Redis is configured to save RDB snapsho ...
- Ubuntu配置SecureCRT登录
1. 命令行切换到root用户 备注:ubuntu默认root用户没有设置密码,切换需要首先设置密码 sudo passwd root 按照提示输入当前用户密码 按照提示输入要设置的root用户密码 ...
- Python 函数式编程和面向对象编程
函数式编程 函数:function.函数式:functional,一种编程范式.函数式编程是一种抽象计算机的编程模式.函数!= 函数式(如计算!=计算机) 如下是不同语言的抽象 层次不同 高阶函数 ...
- HTTP引流神器Goreplay详解【官译】
0.背景 校验系统的正确性和可靠性时,仅靠用例场景无法覆盖全生产环境下的所有场景,需要一套引流工具,在系统正式上线前,用线上的请求测试待上线系统,在正常请求下,是否有报错:在数倍请求下,系统的性能瓶颈 ...
- Java 读书笔记 (十六) Java 继承
例: 开发动物类,其中动物分别为企鹅以及老鼠,要求如下: 企鹅: 属性(姓名,id), 方法(吃,睡,自我介绍) 老鼠: 属性(姓名,id), 方法(吃,睡,自我介绍) 企鹅类: public cla ...
- bzoj5249 [2018多省省队联测]IIIDX
转化一下问题变成给定一棵树,一个序列,求父亲的权值小于子树的最大方案. 直接贪心会在有重复权值时出现错误,我们考虑用线段树优化贪心. 将序列从小到大排序,线段树上每个点记录他和他右边当前还可用的权值, ...
- BZOJ_1180_[CROATIAN2009]OTOCI_LCT
BZOJ_1180_[CROATIAN2009]OTOCI_LCT Description 给出n个结点以及每个点初始时对应的权值wi.起始时点与点之间没有连边.有3类操作: 1.bridge A ...
- Angular2+ 使用 Protractor 与 Modify Header Value (HTTP Headers) 插件 完成 Windows Authorization 验证
入职新公司第二周,接到了一个E2E测试的任务,两天的时间把所有的测试条件都写完了,结果剩下三天都卡在了Windows Authorization验证这里. 先说一下公司项目Authorize的逻辑 第 ...
- mysql服务设置远程连接 解决1251 client does not support ..问题
在docker里面创建mysql容器后设置的密码在远程主机连接时候出现错误: 一.如果是在docker里面安装的mysql镜像则需要先进入mysql里面:参考上一篇:https://www.cnblo ...
- 网络协议 终章 - GTP 协议:复杂的移动网络
前面都是讲电脑上网的情景,今天我们就来认识下使用最多的移动网络上网场景. 移动网络的发展历程 你一定知道手机上网有 2G.3G.4G 的说法,究竟这都是什么意思呢?有一个通俗的说法就是 ...