跟我一起数据挖掘(22)——spark入门
Spark简介
Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
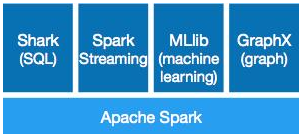
Spark优点
Spark是基于内存,是云计算领域的继Hadoop之后的下一代的最热门的通用的并行计算框架开源项目,尤其出色的支持Interactive Query、流计算、图计算等。
Spark在机器学习方面有着无与伦比的优势,特别适合需要多次迭代计算的算法。同时Spark的拥有非常出色的容错和调度机制,确保系统的稳定运行,Spark目前的发展理念是通过一个计算框架集合SQL、Machine Learning、Graph Computing、Streaming Computing等多种功能于一个项目中,具有非常好的易用性。目前SPARK已经构建了自己的整个大数据处理生态系统,如流处理、图技术、机器学习、NoSQL查询等方面都有自己的技术,并且是Apache顶级Project,可以预计的是2014年下半年在社区和商业应用上会有爆发式的增长。Spark最大的优势在于速度,在迭代处理计算方面比Hadoop快100倍以上;Spark另外一个无可取代的优势是:“One Stack to rule them all”,Spark采用一个统一的技术堆栈解决了云计算大数据的所有核心问题,这直接奠定了其一统云计算大数据领域的霸主地位;
下图是使用逻辑回归算法的使用时间:
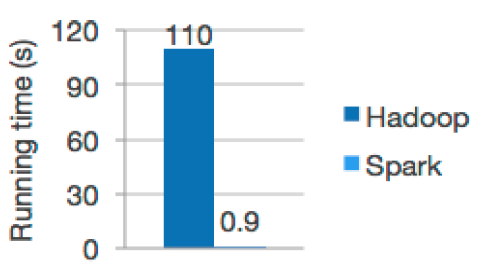
Spark目前支持scala、python、JAVA编程。
作为Spark的原生语言,scala是开发Spark应用程序的首选,其优雅简洁的代码,令开发过mapreduce代码的码农感觉象是上了天堂。
可以架构在hadoop之上,读取hadoop、hbase数据。
spark的部署方式
1、standalone模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。
2、Spark On Mesos模式。这是很多公司采用的模式,官方推荐这种模式(当然,原因之一是血缘关系)。
3、Spark On YARN模式。这是一种最有前景的部署模式。

spark本机安装
流程:进入linux->安装JDK->安装scala->安装spark。
JDK的安装和配置(略)。
安装scala,进入http://www.scala-lang.org/download/下载。

下载后解压缩。
tar zxvf scala-2.11.6.tgz
//改名
mv scala-2.11.6 scala
//设置配置
export SCALA_HOME=/home/hadoop/software/scala
export PATH=$SCALA_HOME/bin;$PATH
source /etc/profile
scala -version
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
scala设置成功。
从http://spark.apache.org/downloads.html下载spark并安装。
下载后解压缩。
进入$SPARK_HOME/bin,运行
./run-example SparkPi
运行结果
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/03/14 23:41:40 INFO SparkContext: Running Spark version 1.3.0
15/03/14 23:41:40 WARN Utils: Your hostname, localhost.localdomain resolves to a loopback address: 127.0.0.1; using 192.168.126.147 instead (on interface eth0)
15/03/14 23:41:40 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
15/03/14 23:41:41 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/03/14 23:41:41 INFO SecurityManager: Changing view acls to: hadoop
15/03/14 23:41:41 INFO SecurityManager: Changing modify acls to: hadoop
15/03/14 23:41:41 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/03/14 23:41:42 INFO Slf4jLogger: Slf4jLogger started
15/03/14 23:41:42 INFO Remoting: Starting remoting
15/03/14 23:41:42 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.126.147:60926]
15/03/14 23:41:42 INFO Utils: Successfully started service 'sparkDriver' on port 60926.
15/03/14 23:41:42 INFO SparkEnv: Registering MapOutputTracker
15/03/14 23:41:43 INFO SparkEnv: Registering BlockManagerMaster
15/03/14 23:41:43 INFO DiskBlockManager: Created local directory at /tmp/spark-285a6144-217c-442c-bfde-4b282378ac1e/blockmgr-f6cb0d15-d68d-4079-a0fe-9ec0bf8297a4
15/03/14 23:41:43 INFO MemoryStore: MemoryStore started with capacity 265.1 MB
15/03/14 23:41:43 INFO HttpFileServer: HTTP File server directory is /tmp/spark-96b3f754-9cad-4ef8-9da7-2a2c5029c42a/httpd-b28f3f6d-73f7-46d7-9078-7ba7ea84ca5b
15/03/14 23:41:43 INFO HttpServer: Starting HTTP Server
15/03/14 23:41:43 INFO Server: jetty-8.y.z-SNAPSHOT
15/03/14 23:41:43 INFO AbstractConnector: Started SocketConnector@0.0.0.0:42548
15/03/14 23:41:43 INFO Utils: Successfully started service 'HTTP file server' on port 42548.
15/03/14 23:41:43 INFO SparkEnv: Registering OutputCommitCoordinator
15/03/14 23:41:43 INFO Server: jetty-8.y.z-SNAPSHOT
15/03/14 23:41:43 INFO AbstractConnector: Started SelectChannelConnector@0.0.0.0:4040
15/03/14 23:41:43 INFO Utils: Successfully started service 'SparkUI' on port 4040.
15/03/14 23:41:43 INFO SparkUI: Started SparkUI at http://192.168.126.147:4040
15/03/14 23:41:44 INFO SparkContext: Added JAR file:/home/hadoop/software/spark-1.3.0-bin-hadoop2.4/lib/spark-examples-1.3.0-hadoop2.4.0.jar at http://192.168.126.147:42548/jars/spark-examples-1.3.0-hadoop2.4.0.jar with timestamp 1426347704488
15/03/14 23:41:44 INFO Executor: Starting executor ID <driver> on host localhost
15/03/14 23:41:44 INFO AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@192.168.126.147:60926/user/HeartbeatReceiver
15/03/14 23:41:44 INFO NettyBlockTransferService: Server created on 39408
15/03/14 23:41:44 INFO BlockManagerMaster: Trying to register BlockManager
15/03/14 23:41:44 INFO BlockManagerMasterActor: Registering block manager localhost:39408 with 265.1 MB RAM, BlockManagerId(<driver>, localhost, 39408)
15/03/14 23:41:44 INFO BlockManagerMaster: Registered BlockManager
15/03/14 23:41:45 INFO SparkContext: Starting job: reduce at SparkPi.scala:35
15/03/14 23:41:45 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:35) with 2 output partitions (allowLocal=false)
15/03/14 23:41:45 INFO DAGScheduler: Final stage: Stage 0(reduce at SparkPi.scala:35)
15/03/14 23:41:45 INFO DAGScheduler: Parents of final stage: List()
15/03/14 23:41:45 INFO DAGScheduler: Missing parents: List()
15/03/14 23:41:45 INFO DAGScheduler: Submitting Stage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:31), which has no missing parents
15/03/14 23:41:45 INFO MemoryStore: ensureFreeSpace(1848) called with curMem=0, maxMem=278019440
15/03/14 23:41:45 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1848.0 B, free 265.1 MB)
15/03/14 23:41:45 INFO MemoryStore: ensureFreeSpace(1296) called with curMem=1848, maxMem=278019440
15/03/14 23:41:45 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1296.0 B, free 265.1 MB)
15/03/14 23:41:45 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:39408 (size: 1296.0 B, free: 265.1 MB)
15/03/14 23:41:45 INFO BlockManagerMaster: Updated info of block broadcast_0_piece0
15/03/14 23:41:45 INFO SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:839
15/03/14 23:41:45 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:31)
15/03/14 23:41:45 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
15/03/14 23:41:45 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, PROCESS_LOCAL, 1340 bytes)
15/03/14 23:41:45 INFO TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, PROCESS_LOCAL, 1340 bytes)
15/03/14 23:41:45 INFO Executor: Running task 1.0 in stage 0.0 (TID 1)
15/03/14 23:41:45 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
15/03/14 23:41:45 INFO Executor: Fetching http://192.168.126.147:42548/jars/spark-examples-1.3.0-hadoop2.4.0.jar with timestamp 1426347704488
15/03/14 23:41:45 INFO Utils: Fetching http://192.168.126.147:42548/jars/spark-examples-1.3.0-hadoop2.4.0.jar to /tmp/spark-db1e742b-020f-4db1-9ee3-f3e2d90e1bc2/userFiles-96c6db61-e95e-4f9e-a6c4-0db892583854/fetchFileTemp5600234414438914634.tmp
15/03/14 23:41:46 INFO Executor: Adding file:/tmp/spark-db1e742b-020f-4db1-9ee3-f3e2d90e1bc2/userFiles-96c6db61-e95e-4f9e-a6c4-0db892583854/spark-examples-1.3.0-hadoop2.4.0.jar to class loader
15/03/14 23:41:47 INFO Executor: Finished task 1.0 in stage 0.0 (TID 1). 736 bytes result sent to driver
15/03/14 23:41:47 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 736 bytes result sent to driver
15/03/14 23:41:47 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 1560 ms on localhost (1/2)
15/03/14 23:41:47 INFO TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 1540 ms on localhost (2/2)
15/03/14 23:41:47 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/03/14 23:41:47 INFO DAGScheduler: Stage 0 (reduce at SparkPi.scala:35) finished in 1.578 s
15/03/14 23:41:47 INFO DAGScheduler: Job 0 finished: reduce at SparkPi.scala:35, took 2.099817 s
Pi is roughly 3.14438
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/kill,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/static,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/threadDump,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/executors,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/environment,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/rdd,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/storage,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/pool,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/stage,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/stages,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/job,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs/json,null}
15/03/14 23:41:47 INFO ContextHandler: stopped o.s.j.s.ServletContextHandler{/jobs,null}
15/03/14 23:41:47 INFO SparkUI: Stopped Spark web UI at http://192.168.126.147:4040
15/03/14 23:41:47 INFO DAGScheduler: Stopping DAGScheduler
15/03/14 23:41:47 INFO MapOutputTrackerMasterActor: MapOutputTrackerActor stopped!
15/03/14 23:41:47 INFO MemoryStore: MemoryStore cleared
15/03/14 23:41:47 INFO BlockManager: BlockManager stopped
15/03/14 23:41:47 INFO BlockManagerMaster: BlockManagerMaster stopped
15/03/14 23:41:47 INFO OutputCommitCoordinator$OutputCommitCoordinatorActor: OutputCommitCoordinator stopped!
15/03/14 23:41:47 INFO SparkContext: Successfully stopped SparkContext
15/03/14 23:41:47 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
15/03/14 23:41:47 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
可以看到输出结果为3.14438。
跟我一起数据挖掘(22)——spark入门的更多相关文章
- Spark入门实战系列--8.Spark MLlib(下)--机器学习库SparkMLlib实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .MLlib实例 1.1 聚类实例 1.1.1 算法说明 聚类(Cluster analys ...
- 使用scala开发spark入门总结
使用scala开发spark入门总结 一.spark简单介绍 关于spark的介绍网上有很多,可以自行百度和google,这里只做简单介绍.推荐简单介绍连接:http://blog.jobbole.c ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--2.Spark编译与部署(中)--Hadoop编译安装
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .编译Hadooop 1.1 搭建环境 1.1.1 安装并设置maven 1. 下载mave ...
- Spark入门实战系列--3.Spark编程模型(上)--编程模型及SparkShell实战
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .Spark编程模型 1.1 术语定义 l应用程序(Application): 基于Spar ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark入门——什么是Hadoop,为什么是Spark?
#Spark入门#这个系列课程,是综合于我从2017年3月分到今年7月份为止学习并使用Spark的使用心得感悟,暂定于每周更新,以后可能会上传讲课视频和PPT,目前先在博客园把稿子打好.注意:这只是一 ...
- 热门数据挖掘模型应用入门(一): LASSO回归
热门数据挖掘模型应用入门(一): LASSO回归 2016-10-10 20:46 作者简介: 侯澄钧,毕业于俄亥俄州立大学运筹学博士项目, 目前在美国从事个人保险产品(Personal Line)相 ...
- Spark入门(Python版)
Hadoop是对大数据集进行分布式计算的标准工具,这也是为什么当你穿过机场时能看到”大数据(Big Data)”广告的原因.它已经成为大数据的操作系统,提供了包括工具和技巧在内的丰富生态系统,允许使用 ...
- spark 入门学习 核心api
spark入门教程(3)--Spark 核心API开发 原创 2016年04月13日 20:52:28 标签: spark / 分布式 / 大数据 / 教程 / 应用 4999 本教程源于2016年3 ...
随机推荐
- 大家都在用PDA条码扫描枪管理企业仓库 PDA无线数据采集程序
PDA数据采集器又称之为手持终端,这些都是用于扫描货物条码统计数据用的,PDA扫描枪有效提高企业仓库管理,在仓库管理中引入条码技术,对仓库的到货检验.入库.出库.调拨.移库移位.库存盘点等各个作业环节 ...
- 打包如何打包额外文件,比如Sqlite数据库的db文件
http://aigo.iteye.com/blog/2278224 Project Settings -> packaging -> Packaging选项中,有多个设置项来设置打包时要 ...
- Git小记
Git简~介 Git是一个分布式版本控制系统,其他的版本控制系统我只用过SVN,但用的时间不长.大家都知道,分布式的好处多多,而且分布式已经包含了集中式的几乎所有功能.Linus创造Git的传奇经历就 ...
- 从零开始山寨Caffe·拾:IO系统(三)
数据变形 IO(二)中,我们已经将原始数据缓冲至Datum,Datum又存入了生产者缓冲区,不过,这离消费,还早得很呢. 在消费(使用)之前,最重要的一步,就是数据变形. ImageNet Image ...
- 弱省互测#0 t1
题意 给一个\(N \times M\)的01网格,1不能走,从起点\((1, 1)\)走到\((N, M)\),每次只能向下或向右走一格,问两条不相交的路径的方案数.(n, m<=1000) ...
- ssm简单配置
MyBatis 是一个可以自定义SQL.存储过程和高级映射的持久层框架. MyBatis 摒除了大部分的JDBC代码.手工设置参数和结果集重获. MyBatis 只使用简单的XML 和注解来配置和映射 ...
- 用VB实现SmartQQ机器人
这里为了便于介绍程序设计的流程,更多以代码形式给出,具体可用火狐浏览器的firebug插件来抓包分析,或者用谷歌浏览器的开发者工具进行抓包.抓包地址是:http://w.qq.com 第一步,是二维码 ...
- overflow:hidden清除浮动原理
overflow:hidden的意思是超出部分去掉,如果父元素height为auto,内部元素浮动,势必会将内部元素全部隐藏,故计算出内部浮动高度顺便清除浮动.
- Mysql远程访问
命令行: mysql -h 192.168.1.145 -u root -p 1.初始化root密码 进入mysql数据库 1mysql>update user set password=PAS ...
- 网站中使用中文个性字库字体--@font-face解决方案探索 l(转)
最近的项目有用到特别中文字体,最终效果如下图: 红线标记处均为字体,可选中,交互起来,比图片方便太多了. 解决思路就是将体积巨大的中文字库,取子集,只包涵要使用的那部分文字,因此体积就很小了(包含10 ...