调整的R方_如何选择回归模型
python风控建模实战lendingClub(博主录制,catboost,lightgbm建模,2K超清分辨率)
https://study.163.com/course/courseMain.htm?courseId=1005988013&share=2&shareId=400000000398149

1.选择最简单模型
如果不能满足:
增加参数,增加R**2
判断是否overfittiing
调整R方,BIC,AIC(选择较小BIC或AIC值)
R方不能比较参数不同模型,但调整后R方可以比较不同参数模型
如果添加一个新的变量,但调整R方变小,这个变量就是多余的
如果添加一个新的变量,但调整R方变大,这个变量就是有用的
R^2很小得谨慎,说明你选的解释变量解释能力不足,有可能有其他重要变量被纳入到误差项。可尝试寻找其他相关变量进行多元回归
这个问题在伍德里奇的书里有说明,可绝系数只是判断模型优劣的指标之一,而不是全部,特别是当使用微观数据,样本量比较大的时候,可绝系数可以很小,但这并不能表示模型就差。
显著但是R值小,要考虑不同的专业背景。
有的专业确实比较小,楼主的例子,我觉得这个大小就能接受了。
态度与行为之间的影响因素非常多,态度能解释行为11-15%已经不小了。
F检验是对整个模型而已的,看是不是自变量系数不全为0,而t检验则是分别针对某个自变量的,看每个自变量是否有显著预测效力。
调整R方VS样本量VS变量数量
样本量越大,调整的R方惩罚机制越小,调整的R方越大
样本量越小,调整的R方惩罚机制越大,调整的R方越小
变量越多,惩罚机制越严重,调整R方越小
变量越少,惩罚机制越严小,调整R方越大
n=13 样本
p=2 变量数量
adjR2=rSquared-(1-rSquared)*((p-1)/(n-p))=0.63-(1-0.63)
rSquared=0.63109603807606962
rSquared_adj=0.59755931426480324
n=13 样本
n越大,(n-p)大,(p-1)/(n-p)越小,(1-rSquared)*((p-1)/(n-p))越小,rSquared-(1-rSquared)*((p-1)/(n-p))越大,即样本量越大,调整R方越大,变量解释力度越大。
p=2 变量数量
参数多,p大,(P-1)越大,(n-p)越小
,(p-1)/(n-p)越大,
rSquared-(1-rSquared)*((p-1)/(n-p)) 越小,即adjR2越小。所以变量越多,惩罚机制越严重,调整R方越小
测试Python脚本
导入excel数据
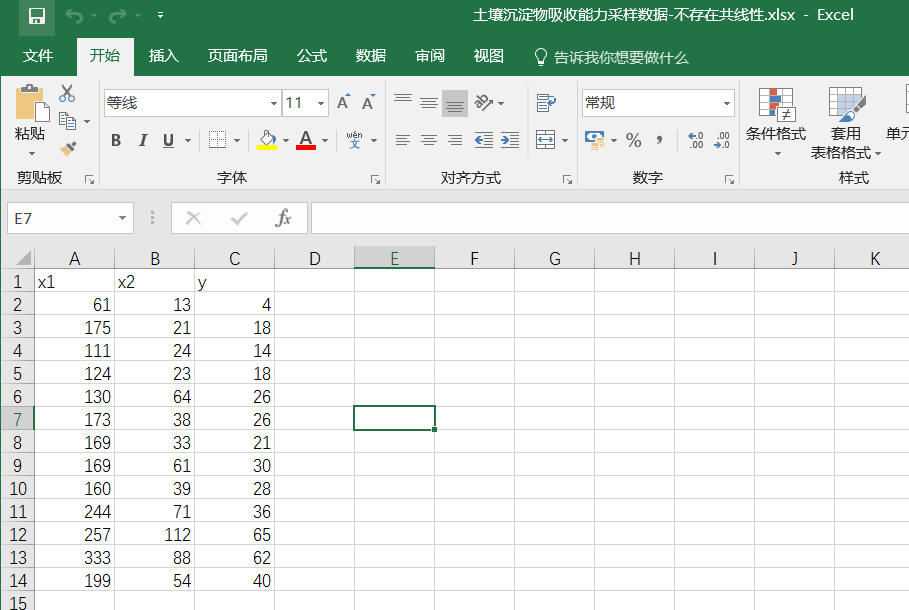
import pandas as pd
df=pd.read_excel("土壤沉淀物吸收能力采样数据-不存在共线性.xlsx")
array_values=df.values
x1=[i[0] for i in array_values]
x2=[i[1] for i in array_values] df = pd.DataFrame({'x':x1, 'y':x2})
# Fit the model
model = ols("y~x", df).fit()
rSquared_adj=model.rsquared_adj
rSquared=model.rsquared n=13 #样本
p=2 #变量数量
adjR2=rSquared-(1-rSquared)*((p-1)/(n-p)) #最终adjR2和rSquared_adj是相等的

n为样本个数,p为变量数





python信用评分卡建模(附代码,博主录制)

微信扫二维码,免费学习更多python资源

调整的R方_如何选择回归模型的更多相关文章
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- R in action读书笔记(11)-第八章:回归-- 选择“最佳”的回归模型
8.6 选择“最佳”的回归模型 8.6.1 模型比较 用基础安装中的anova()函数可以比较两个嵌套模型的拟合优度.所谓嵌套模型,即它的一 些项完全包含在另一个模型中 用anova()函数比较 &g ...
- 【机器学习与R语言】6-线性回归
目录 1.理解回归 1)简单线性回归 2)普通最小二乘估计 3)相关系数 4)多元线性回归 2.线性回归应用示例 1)收集数据 2)探索和准备数据 3)训练数据 4)评估模型 5)提高模型性能 1.理 ...
- 数据挖掘-diabetes数据集分析-糖尿病病情预测_线性回归_最小平方回归
# coding: utf-8 # 利用 diabetes数据集来学习线性回归 # diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况. # 数据 ...
- R 读取回归模型的信息
参考博客: http://blog.sina.com.cn/s/blog_8f5b2a2e0101fmiq.html https://blog.csdn.net/huangyouyu523/artic ...
- R语言 我要如何开始R语言_数据分析师
R语言 我要如何开始R语言_数据分析师 我要如何开始R语言? 很多时候,我们的老板跟我们说,这个东西你用R语言去算吧,Oh,My god!什么是R语言?我要怎么开始呢? 其实回答这个问题很简单,首先, ...
- 吴裕雄 python 机器学习——模型选择回归问题性能度量
from sklearn.metrics import mean_absolute_error,mean_squared_error #模型选择回归问题性能度量mean_absolute_error模 ...
- SPSS分析技术:无序多元Logistic回归模型;美国总统大选的预测历史及预测模型
SPSS分析技术:无序多元Logistic回归模型:美国总统大选的预测历史及预测模型 在介绍有序多元Logistic回归分析的理论基础时,介绍过该模型公式有一个非常重要的假设,就是自变量对因变量多个类 ...
- SPSS数据分析—配对Logistic回归模型
Lofistic回归模型也可以用于配对资料,但是其分析方法和操作方法均与之前介绍的不同,具体表现 在以下几个方面1.每个配对组共有同一个回归参数,也就是说协变量在不同配对组中的作用相同2.常数项随着配 ...
随机推荐
- Python Tkinter-Event
1.点击 from tkinter import * root=Tk() def printCoords(event): print(event.x,event.y) bt1=Button(root, ...
- Javascript中Generator(生成器)
阅读目录 Generator的使用: yield yield* next()方法 next()方法的参数 throw方法() return()方法: Generator中的this和他的原型 实际使用 ...
- Python爬虫入门(6):Cookie的使用
为什么要使用Cookie呢? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密) 比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓 ...
- ES6的新特性(8)——数组的扩展
数组的扩展 扩展运算符 含义 扩展运算符(spread)是三个点(...).它好比 rest 参数的逆运算,将一个数组转为用逗号分隔的参数序列. console.log(...[1, 2, 3]) / ...
- Scrum立会报告+燃尽图(十月十七日总第八次):分配Alpha阶段任务
此作业要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2246 项目地址:https://git.coding.net/zhang ...
- P4语法(4)Control block
Control block Control block之中用于放置设计好的Table和Action. 可以把control block认为是pipeline的一个模板,之前用的v1model中就是in ...
- eclipse中jsp页面Invalid location of tag 解决办法分析小结
在jsp页面使用标签过程中有时候不注意规则的话,eclipse会提示一些错误,下面针对这些错误提出相应的解决办法: <form></form>标签 1. Invalid loc ...
- PHP内置标准类
PHP内置标准类 php语言内部,有“很多现成的类”,其中有一个,被称为“内置标准类”. 这个类“内部”可以认为什么都没有,类似这样: class stdclass{ } 其作用,可以用于存储一些临 ...
- FZU2127_养鸡场
题目的意思为要你求出满足三边范围条件且周长为n的三角形的数目. 其实做法是直接枚举最短边,然后就可以知道第二条边的取值范围,同时根据给定的范围缩小范围. 同时根据第二条边的范围推出第三条边的范围,再次 ...
- MachineLearning ---- lesson 1
该博文系列是Andrew NG教授的课程笔记,有兴趣的朋友可以在Coursera或者网易公开课上找到该课程. Supervised Learning 下图是一个监督学习回归分析的例子.该图旨在预测房价 ...