caffe使用finetume
训练时, solver.prototxt中使用的是train_val.prototxt
./build/tools/caffe/train -solver ./models/bvlc_reference_caffenet/solver.prototxt
使用上面训练的网络提取特征,使用的网络模型是deploy.prototxt
./build/tools/extract_features.bin models/bvlc_refrence_caffenet.caffemodel models/bvlc_refrence_caffenet/deploy.prototxt

Caffe finetune
1、准备finetune的数据
image文件夹子里面放好来finetune的图片
train.txt中放上finetune的训练图片绝对路径,及其对应的类别
test.txt中放上finetune的测试图片绝对路径,及其对应的类别
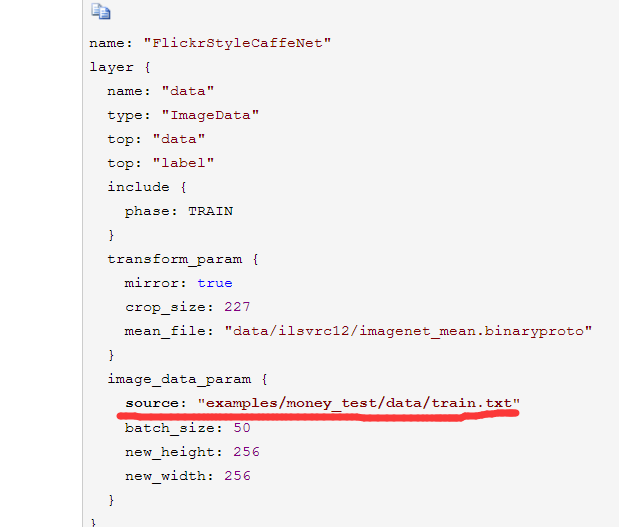
2、更改train_val.prototxt
更改最后一层

a)输出个数改变
b)最后一层学习率变大,由2变成20
3、更改solver.prototxt
a)stepsize变小:由100000变成20000
b)max_iter变小:450000变成50000
c)base_lr变小:0.01变成0.001
d)test_iter变小:1000变成100
4、调用命令finetune
caffe % ./build/tools/caffe train -solver models/finetune_flickr_style/solver.prototxt -weights models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel -gpu 0
注意:学习率有两个是一个是weight,一个是bias的学习率,一般bias的学习率是weight的两倍
decay是权值衰减,是加了正则项目,防止overfitting
the global weight_decay multiplies the parameter-specific decay_mult
solver.prototxt具体设置解释:

rmsprop:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
#The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.0
weight_decay: 0.0005
#The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
display: 100
max_iter: 10000
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet_rmsprop"
solver_mode: GPU
type: "RMSProp"
rms_decay: 0.98 Adam:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
#All parameters are from the cited paper above
base_lr: 0.001
momentum: 0.9
momentum2: 0.999
#since Adam dynamically changes the learning rate, we set the base learning
#rate to a fixed value
lr_policy: "fixed"
display: 100
#The maximum number of iterations
max_iter: 10000
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
type: "Adam"
solver_mode: GPU multistep:
net: "examples/mnist/lenet_train_test.prototxt"
test_iter: 100
test_interval: 500
#The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
#The learning rate policy
lr_policy: "multistep"
gamma: 0.9
stepvalue: 5000
stepvalue: 7000
stepvalue: 8000
stepvalue: 9000
stepvalue: 9500
# Display every 100 iterations
display: 100
#The maximum number of iterations
max_iter: 10000
#snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet_multistep"
#solver mode: CPU or GPU
solver_mode: GPU
卷积层的group参数,可以实现channel-wise的卷积操作
caffe使用finetume的更多相关文章
- 基于window7+caffe实现图像艺术风格转换style-transfer
这个是在去年微博里面非常流行的,在git_hub上的代码是https://github.com/fzliu/style-transfer 比如这是梵高的画 这是你自己的照片 然后你想生成这样 怎么实现 ...
- caffe的python接口学习(7):绘制loss和accuracy曲线
使用python接口来运行caffe程序,主要的原因是python非常容易可视化.所以不推荐大家在命令行下面运行python程序.如果非要在命令行下面运行,还不如直接用 c++算了. 推荐使用jupy ...
- 基于Caffe的Large Margin Softmax Loss的实现(中)
小喵的唠叨话:前一篇博客,我们做完了L-Softmax的准备工作.而这一章,我们开始进行前馈的研究. 小喵博客: http://miaoerduo.com 博客原文: http://www.miao ...
- 基于Caffe的Large Margin Softmax Loss的实现(上)
小喵的唠叨话:在写完上一次的博客之后,已经过去了2个月的时间,小喵在此期间,做了大量的实验工作,最终在使用的DeepID2的方法之后,取得了很不错的结果.这次呢,主要讲述一个比较新的论文中的方法,L- ...
- 基于Caffe的DeepID2实现(下)
小喵的唠叨话:这次的博客,真心累伤了小喵的心.但考虑到知识需要巩固和分享,小喵决定这次把剩下的内容都写完. 小喵的博客:http://www.miaoerduo.com 博客原文: http://ww ...
- 基于Caffe的DeepID2实现(中)
小喵的唠叨话:我们在上一篇博客里面,介绍了Caffe的Data层的编写.有了Data层,下一步则是如何去使用生成好的训练数据.也就是这一篇的内容. 小喵的博客:http://www.miaoerduo ...
- 基于Caffe的DeepID2实现(上)
小喵的唠叨话:小喵最近在做人脸识别的工作,打算将汤晓鸥前辈的DeepID,DeepID2等算法进行实验和复现.DeepID的方法最简单,而DeepID2的实现却略微复杂,并且互联网上也没有比较好的资源 ...
- 基于英特尔® 至强™ 处理器 E5 产品家族的多节点分布式内存系统上的 Caffe* 培训
原文链接 深度神经网络 (DNN) 培训属于计算密集型项目,需要在现代计算平台上花费数日或数周的时间方可完成. 在最近的一篇文章<基于英特尔® 至强™ E5 产品家族的单节点 Caffe 评分和 ...
- 基于英特尔® 至强 E5 系列处理器的单节点 Caffe 评分和训练
原文链接 在互联网搜索引擎和医疗成像等诸多领域,深度神经网络 (DNN) 应用的重要性正在不断提升. Pradeep Dubey 在其博文中概述了英特尔® 架构机器学习愿景. 英特尔正在实现 Prad ...
随机推荐
- MySQL5.7初始配置
MySQL5.7初始配置 Windows7 环境安装MySQL5.7配置命令 <<<<<<<<<<<<<<<& ...
- 【刷题】洛谷 P3806【模板】点分治1
题目背景 感谢hzwer的点分治互测. 题目描述 给定一棵有n个点的树 询问树上距离为k的点对是否存在. 输入输出格式 输入格式: n,m 接下来n-1条边a,b,c描述a到b有一条长度为c的路径 接 ...
- 洛谷P3933 Chtholly Nota Seniorious 【二分 + 贪心 + 矩阵旋转】
威廉需要调整圣剑的状态,因此他将瑟尼欧尼斯拆分护符,组成了一个nnn行mmm列的矩阵. 每一个护符都有自己的魔力值.现在为了测试圣剑,你需要将这些护符分成 A,B两部分. 要求如下: 圣剑的所有护符, ...
- bzoj3143: [Hnoi2013]游走(贪心+高斯消元)
考虑让总期望最小,那么就是期望经过次数越多的边贪心地给它越小的编号. 怎么求每条边的期望经过次数呢?边不大好算,我们考虑计算每个点的期望经过次数f[x],那么一条边的期望经过次数就是f[x]/d[x] ...
- 【翻译】InterlockedIncrement内部是如何实现的?
Interlocked系列函数可以对内存进行原子操作,它是如何实现的? 它的实现依赖于底层的CPU架构.对于某些CPU来说,这很简单,例如x86可以通过LOCK前缀直接支持Interl ...
- 图像格式转换之BMP格式转换为JPG格式
// bmp2jpg.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include "jpeglib.h" #inc ...
- 洛谷P1199 三国游戏
题目描述 小涵很喜欢电脑游戏,这些天他正在玩一个叫做<三国>的游戏. 在游戏中,小涵和计算机各执一方,组建各自的军队进行对战.游戏中共有 N 位武将(N为偶数且不小于 4),任意两个武将之 ...
- PHP_INT_SIZE
PHP_INT_SIZE:表示整数integer值的字长 PHP_INT_MAX:表示整数integer值的最大值 注: 输出下32位中PHP_INT_SIZE:4,PHP_INT_MAX:21474 ...
- wx.showToast 延时跳转~~~
//提交预约订单 wx.request({ url: 'http://www.pusonglin.cn/app/index.php?i=2&c=entry&do=api&op= ...
- Python --Redis Hash操作
一.Redis Hash操作 Redis 数据库hash数据类型是一个string类型的key和value的映射表,适用于存储对象.Redis 中每个 hash 可以存储 232 - 1 键值对(40 ...