K-means聚类算法MATLAB
以K-means算法为例,实现了如下功能
- 自动生成符合高斯分布的数据,函数名为gaussianSample.m
- 实现多次随机初始化聚类中心,以找到指定聚类数目的最优聚类。函数名myKmeans.m
- 自动寻找最佳聚类数目,函数名称besKmeans.m,并绘制了拐点图(L图)
gaussianSample.m
function [data] = gaussianSample(n,m,mu,sigma,sigma1)
% 生成n个符合多元高斯分布的样本
% data = gaussianSample(n,m,mu,sigma,mu1,sigma1)
% 生成一个符合高斯分布的数据集data
% n表示生成的数量,m表示每个簇的点的数量
% 先通过mu与sigma生成簇中心的分布情况
% 在通过簇中心分布mu1与sigma1生成每个簇的的分布情况
% mu与mu1为均值,sigma与sigma1为协方差矩阵。 % % 默认值生成2维数据
% m = 100;
% mu = [5,5];
% sigma = [16 0;0 16];
% sigma1 = [0.5,0;0,0.5]; % 生成中心点分布
mu1 = mvnrnd(mu,sigma,n);
% 生成数据
data = [];
for i = 1:n
temp = mvnrnd(mu1(i,:),sigma1,m);
data = [data;temp];
end % % 可视化样本,以二维数据为例
% hold on;
% plot(data(:,1),data(:,2),'ko','MarkerFaceColor','y');
% plot(mu1(:,1),mu1(:,2),'r+','LineWidth',2,'MarkerSize',7);
% hold off;
myKmeans.m
function [cx,cost] = myKmeans(K,data,num)
% 生成将data聚成K类的最佳聚类
[cx,cost] = kmeans1(K,data);
for i = 2:num
[cx1,min] = kmeans1(K,data);
if min<cost
cost = min;
cx = cx1;
end
end
% plotMeans(data,cx,K);
end function [cx,cost] = kmeans1(K,data)
%KMEANS 把数据集data聚成K类
% [cx,cost] = kmeans(K,data)
% K为聚类数目,data为数据集
% cx为样本所属聚类,cost为此聚类的代价值
% 选择需要聚类的数目 % 随机选择聚类中心
centroids = data(randperm(size(data,1),K),:);
% 迭代聚类
centroids_temp = zeros(size(centroids));
num = 0;
while (~isequal(centroids_temp,centroids)&&num<20)
centroids_temp = centroids;
[cx,cost] = findClosest(data,centroids,K);
centroids = compueCentroids(data,cx,K);
num = num+1;
end
cost = cost/size(data,1); end function [cx,cost] = findClosest(data,centroids,K)
% 将样本划分到最近的聚类中心
cost = 0;
n = size(data,1);
cx = zeros(n,1);
for i = 1:n
[M,I] = min(sum((centroids-data(i,:))'.^2));
cx(i) = I;
cost = cost+M;
end end function centroids = compueCentroids(data,cx,K)
% 计算新的聚类中心
centroids = zeros(K,size(data,2));
for i = 1:K
centroids(i,:) = mean(data(cx==i,:));
end
end
bestKmeans.m
function [num,cx] = bestKmeans(data,m,n)
% 返回数据集的最佳聚类数目与聚类结果
% data为数据集,m为寻找的最大聚类数量,n为每次聚类寻找次数
% 返回num最佳聚类数量,cx聚类结果。
costs = zeros(m,1)';
for i = 1:m
[~,cost] = myKmeans(i,data,n);
costs(i) = cost;
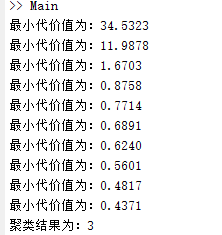
fprintf('最小代价值为:%.4f\n',cost);
end
costs = costs./costs(2)*m;
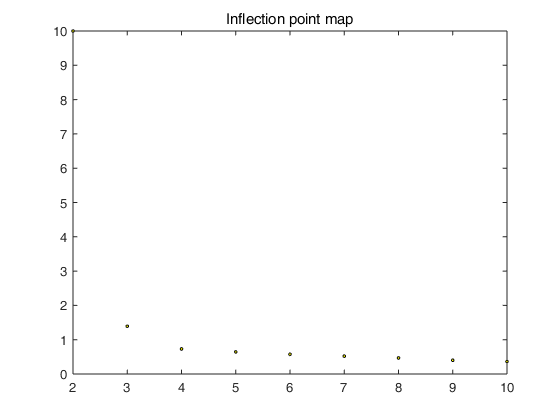
% 绘制拐点图
X = (1:m)';
X = [X,costs']; plot(X(2:m,1),X(2:m,2),'ko','MarkerFaceColor','y','MarkerSize',2);
title('Inflection point map');
% 寻找最佳聚类
min = -1;
for i = 3:m
x1 = X(2,:)-X(i,:);
x2 = X(m,:)-X(i,:);
k = x1*x2'/((x1*x1')*(x2*x2'));
if k>min&&k<0
num = i;
min = k;
end
end
% fprintf('聚类结果为:%d\n',num);
[cx,~] = myKmeans(num,data,n);
end
plotMeans.m
function [] = plotMeans(data,cx,K)
% 可视化数据聚类效果
figure;
color='cbygmkr';
hold on;
for i = 1:K
px = find(cx==i);
plot(data(px,1),data(px,2),'ko','MarkerFaceColor',color(i),'MarkerSize',5);
end
title('K-means')
hold off;
end
Main.m
% 主函数 % 生成符合高斯分布的数据
mu = [5,5];
sigma = [16,0;0,16];
sigma1 = [0.5,0;0,0.5];
data = gaussianSample(4,50,mu,sigma,sigma1); % 计算最佳聚类数量与结果
[num,cx] = bestKmeans(data,10,10);
fprintf('聚类结果为:%d\n',num);
plotMeans(data,cx,num);
执行Main.m代码,自动检测最佳聚类数目。结果如图

K-means聚类算法MATLAB的更多相关文章
- 密度峰值聚类算法MATLAB程序
密度峰值聚类算法MATLAB程序 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 密度峰值聚类算法简介见:[转] 密度峰值聚类算法(DPC) 数据见:MATL ...
- k均值聚类算法原理和(TensorFlow)实现
顾名思义,k均值聚类是一种对数据进行聚类的技术,即将数据分割成指定数量的几个类,揭示数据的内在性质及规律. 我们知道,在机器学习中,有三种不同的学习模式:监督学习.无监督学习和强化学习: 监督学习,也 ...
- K均值聚类算法
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个 ...
- 机器学习实战---K均值聚类算法
一:一般K均值聚类算法实现 (一)导入数据 import numpy as np import matplotlib.pyplot as plt def loadDataSet(filename): ...
- K均值聚类算法的MATLAB实现
1.K-均值聚类法的概述 之前在参加数学建模的过程中用到过这种聚类方法,但是当时只是简单知道了在matlab中如何调用工具箱进行聚类,并不是特别清楚它的原理.最近因为在学模式识别,又重新接触了这 ...
- 基于改进人工蜂群算法的K均值聚类算法(附MATLAB版源代码)
其实一直以来也没有准备在园子里发这样的文章,相对来说,算法改进放在园子里还是会稍稍显得格格不入.但是最近邮箱收到的几封邮件让我觉得有必要通过我的博客把过去做过的东西分享出去更给更多需要的人.从论文刊登 ...
- K-medodis聚类算法MATLAB
国内博客,上介绍实现的K-medodis方法为: 与K-means算法类似.只是距离选择与聚类中心选择不同. 距离为曼哈顿距离 聚类中心选择为:依次把一个聚类中的每一个点当作当前类的聚类中心,求出代价 ...
- K-modes聚类算法MATLAB
K-modes算法主要用于分类数据,如 国籍,性别等特征. 距离使用汉明距离,即有多少对应特征不同则距离为几. 中心点计算为,选择众数作为中心点. 主要功能: 随机初始化聚类中心,计算聚类. 选择每次 ...
- 谱聚类算法—Matlab代码
% ========================================================================= % 算 法 名 称: Spectral Clus ...
随机推荐
- Linux快速定位并且杀掉占用端口的进程
1.定位 lsof -i:8811(端口号) 2.杀掉进程 kill -9 63924
- golang :连接数据库闲置断线的问题
golang在进行数据库操作,一般来说我们使用Open函数创建一个数据库(操作)句柄:func Open(driverName, dataSourceName string) (*DB, error) ...
- Laravel 5.1 中创建自定义 Artisan 控制台命令实例教程
1.入门 Laravel通过Artisan提供了强大的控制台命令来处理非浏览器业务逻辑.要查看Laravel中所有的Artisan命令,可以通过在项目根目录运行: php artisan list 对 ...
- 后缀数组LCP + 二分 - UVa 11107 Life Forms
Life Forms Problem's Link Mean: 给你n个串,让你找出出现次数大于n/2的最长公共子串.如果有多个,按字典序排列输出. analyse: 经典题. 直接二分判断答案. 判 ...
- chrome显示小于12号字体的方法
我现在做一个支持英文的网站,但是字体要设置小于12号字体,我百度方法是-webkit-text-size-adjust:none; 但是谷歌为什么不支持啊, 有没有解决办法 让谷歌浏览器 支持小于 ...
- Mybatis实现了接口绑定,使用更加方便。
1.Mybatis实现了接口绑定,使用更加方便. 在ibatis2.x中我们需要在DAO的实现类中指定具体对应哪个xml映射文件, 而Mybatis实现了DAO接口与xml映射文件的绑定,自动为我们生 ...
- PHP中strlen和mb_strlen函数的区别
strlen strlen — 获取字符串长度 int strlen ( string $string ) 返回给定的字符串 string 的长度. mb_strlen int mb_strlen ( ...
- nginx php文件上传的大小配置问题
- css 动画
CSS3动画相关的几个属性是:transition, transform, animation:我分别理解为过渡,变换,动画.虽意义相近,但具体角色不一.就像是SHE组合,虽然都是三个女生,都唱同一首 ...
- Objective-C Runtime初探:self super
题目 上题目,已知A是爷爷,B是爸爸,C是孙子. @interface A : NSObject - (void)f; @end @interface B : A - (void)f; - (void ...