PGM学习之一
一 课程基本信息
本课程是由Prof.Daphne Koller主讲,同时得到了Prof. Kevin Murphy的支持,在coursera上公开传播。在本课程中,你将学习到PGM(Probabilistic Graphical Models)表示的基本理论,以及如何利用人类自身的知识和机器学习技术来构建PGM;还将学习到使用PGM算法来对有限、带噪声的证据提取结论,在不确定条件下做出正确的抉择。该课程不仅包含PGM框架的理论基础,还有将这些技术应用于新问题的实际技巧。
本课程包含以下主题:
1.贝叶斯网络(Bayesian network)和马尔科夫网络(Markov network)的表示,包括随时间变换的域和可变数量的实体的域的推理;
2.推理和推断的方法,包括精确推断(变量消除(variable elimination),势团树(clique tree)),近似推断(信仰传播的消息传递,马尔科夫链(蒙特卡洛方法));
3.PGM中,参数和结构化的学习方法;
4.在不确定条件下使用PGM进行决策;
二 什么是PGM?
不确定性是现实世界应用中不可避免的问题:我们几乎从未肯定地预测将要发生的时间,即使我们对于过去和现在的信息都了如指掌。概率理论为我们提供了用以对我因时而异、因地而异的belief建模的基础。这些belief可以结合个人的喜好来指导行动,甚至在选择观测中也能用到。
概率论自17世纪以来就存在,但直到最近我们才具有有效使用概率论的知识解决涉及许多相互联系的变量的大问题,这主要归功于PGM模型框架的发展。该框架,主要包含例如贝叶斯网络和马尔科夫随机场(Markov random fields)等方法,使用的思想是计算机科学中的离散数据结构可以快速编码、在包含成千上万个变量的高维空间操作概率分布。这些方法已经广泛应用于许多领域:网页搜索,医疗和故障诊断,图像理解,生物网络重建,语音识别,自然语言处理,高噪声环境下编码信息传输,机器人导航,等等。PGM框架为任何希望通过有限、含噪的观测来正确推理提供了必要的工具。
三 PGM相关概述
3.1 为什么需要PGM?
PGM最开始出现在计算机科学和人工智能领域,主要应用于医学诊断。假设一个医生正在给一个病人看病。从医生的角度,他掌握着病人相当数量的信息-诱因、症状、各种测试结果等。并且,他应当判断出,病人的病情诊断是什么,不同的质量方案会有什么样的反应等等。PGM的另外一个典型应用是图像分割。比如,我们有一张可能包含成千上万个像素。图像分割,就是给图像中每个像素贴上标签。例如下图所示,每个像素应该给贴上诸如草地、天空、牛或马此类类别标签。

上述两个问题的共同点是:
1.它们都具有大量我们需要从中推理的变量。在图像分割问题中,不同的像素或者由像素构成的小区域的标签叫superpixels。
2.正确的结果具有不确定性,不管算法设计得如何清晰。
综上,PGM就是用来解决上述应用的框架。
3.2 什么是Model?
模型是一个我们理解世界的形象化表示(Declarative representation)。如下图所示:

简单的讲,一个模型是一种我们理解周围世界的声明或者表达方式。在计算机内,一个模型包含我们对若干变量的理解,比如,这些变量是什么含义,变量之间如何交互。模型的这种特性使得我们能够将新的算法加入模型内部,同时加入新的外界知识。比如用专家只是知道模型,通过学习的方法改善模型等。
3.3什么是Probabilistic?
首先解释下不确定性(Uncertainty)。产生不确定性的原因主要有:
1、对世界认知状态的不完整;2、含有噪声的观测(Noisy observations);3、模型未能覆盖所有实际现象;4、固有的随机性;
概率论,通常具有清晰的表达式,强推理模式,可建立的学习方法
3.4什么是Graphical?
Graphical(图)来自计算机科学,是一种复杂数据结构。通常包括顶点和连接顶点的边。
四 Graphical Models(图模型)
最简单的图模型是贝叶斯网络,通常贝叶斯网络使用有向无环图来表示,图中的顶点表示随机变量,图中的边沿表示随机变量之间的概率依赖关系;在机器学习和图像处理中(图像分割)还经常使用马尔科夫网络(Markov network),通常马尔科夫网络使用无向图来表示顶点与周围顶点之间的关系。

下面给出一个在图像分割中实际应用的例子:

五 分布(Distributions)
联合分布-在概率论中, 对两个随机变量X和Y,其联合分布是同时对于X和Y的概率分布.
对离散随机变量而言,联合分布概率密度函数为Pr(X = x & Y = y),即

因为是概率分布函数,所以必须有

以通过考试成绩评估学生学习情况为例。

I表示学生智力,可取值为0和1;D表示试卷难易程度,可取值为0和1;G代表最后的试卷结果等级,可取值为1,2,3。根据三个随机变量I,D,G的取值情况,我们知道三个随机变量一共有2*2*3种取值。联合分布P(I,D,G)的分布情况如上图右表所示。需要注意的一点是,I,D,G是相互独立的随机变量。
条件概率分布(条件分布)是现代概率论中的概念。已知两个相关的随机变量X 和Y,随机变量Y 在条件{X =x}下的条件概率分布是指当已知X 的取值为某个特定值x之时,Y 的概率分布。 如果Y 在条件{X =x}下的条件概率分布是连续分布,那么其密度函数称作Y 在条件{X =x}下的条件概率密度函数(条件分布密度、条件密度函数)。与条件分布有关的概念,常常以“条件”作为前缀,如条件期望、条件方差等等。
对于离散型的随机变量X 和Y(取值范围分别是 和
和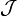 ),随机变量Y 在条件{X =x}下的条件概率分布是:
),随机变量Y 在条件{X =x}下的条件概率分布是:
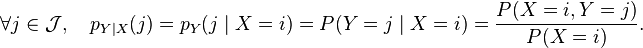 (
( )
)
同样的,X 在条件{Y=y}下的条件概率分布是:
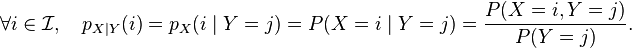 (
(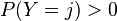 )
)
其中,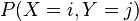 是X 和Y 联合分布概率,即“
是X 和Y 联合分布概率,即“ ,并且
,并且 发生的概率”。如果用
发生的概率”。如果用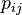 表示的值:
表示的值: 那么随机变量X 和Y 的边际分布就是:
那么随机变量X 和Y 的边际分布就是:

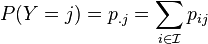
因此, 随机变量Y 在条件{X =x}下的条件概率分布也可以表达为:
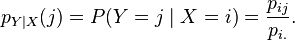 (
(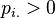 )
)
同样的,X 在条件{Y=y}下的条件概率分布也可以表达为:
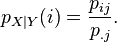 (
( )
)
继续前面的例子,例如我们要求当G取值为1的时候的条件概率,那么P(I,D,G=1)为所有I和D变换,而G固定为1的联合分布的取值之和。

由上图我们知道,P(I,D,G=1)的值为0.126+0.009+0.252+0.06=0.447。这里G=1的条件概率不唯一,在实际应用中,使用条件概率时,常常还需要进行条件概率的归一化。简单的讲,就是在G=1的时候,可以将概率空间单纯的之前的3维(I,D,G各自所在的空间为一维)看做2维(G固定,只剩下I,D)。因此可条件概率的归一化是指条件概率的每一个可能的取值与条件概率之和的商。如下图,P(I,D|g=1)的条件概率分布如右表所示。

最后,还需要明确的一个概念是边缘概率。边缘概率是某个事件发生的概率。边缘概率是这样得到的:在联合概率中,把最终结果中不需要的那些事件合并成其事件的全概率而消失(对离散随机变量用求和得全概率,对连续随机变量用积分得全概率)。这称为边缘化(marginalization)。A的边缘概率表示为P(A),B的边缘概率表示为P(B)。继续之前的例子,比如我们已经知道P(I,D|g=1),然后我们边缘化I,则我们可以得D的边缘分布,如下图所示:

PGM学习之一的更多相关文章
- PGM学习之二 PGM模型的分类与简介
废话:和上一次的文章确实隔了太久,希望趁暑期打酱油的时间,将之前学习的东西深入理解一下,同时尝试用Python写相关的机器学习代码. 一 PGM模型的分类 通过上一篇文章的介绍,相信大家对PGM的定义 ...
- PGM学习之七 MRF,马尔科夫随机场
之前自己做实验也用过MRF(Markov Random Filed,马尔科夫随机场),基本原理理解,但是很多细节的地方都不求甚解.恰好趁学习PGM的时间,整理一下在机器视觉与图像分析领域的MRF的相关 ...
- PGM学习之六 从有向无环图(DAG)到贝叶斯网络(Bayesian Networks)
本文的目的是记录一些在学习贝叶斯网络(Bayesian Networks)过程中遇到的基本问题.主要包括有向无环图(DAG),I-Maps,分解(Factorization),有向分割(d-Separ ...
- PGM学习之五 贝叶斯网络
本文的主题是“贝叶斯网络”(Bayesian Network) 贝叶斯网络是一个典型的图模型,它对感兴趣变量(variables of interest)及变量之间的关系(relationships) ...
- PGM学习之四 Factor,Reasoning
通过上一篇文章的介绍,我们已经基本了解了:Factor是组成PGM模型的基本要素:Factor之间的运算和推理是构建高维复杂PGM模型的基础.那么接下来,我们将重点理解,Factor之间的推理(Rea ...
- PGM学习之三 朴素贝叶斯分类器(Naive Bayes Classifier)
介绍朴素贝叶斯分类器的文章已经很多了.本文的目的是通过基本概念和微小实例的复述,巩固对于朴素贝叶斯分类器的理解. 一 朴素贝叶斯分类器基础回顾 朴素贝叶斯分类器基于贝叶斯定义,特别适用于输入数据维数较 ...
- 机器学习中的隐马尔科夫模型(HMM)详解
机器学习中的隐马尔科夫模型(HMM)详解 在之前介绍贝叶斯网络的博文中,我们已经讨论过概率图模型(PGM)的概念了.Russell等在文献[1]中指出:"在统计学中,图模型这个术语指包含贝叶 ...
- 机器学习&数据挖掘笔记_24(PGM练习八:结构学习)
前言: 本次实验包含了2部分:贝叶斯模型参数的学习以及贝叶斯模型结构的学习,在前面的博文PGM练习七:CRF中参数的学习 中我们已经知道怎样学习马尔科夫模型(CRF)的参数,那个实验采用的是优化方法, ...
- 机器学习&数据挖掘笔记_23(PGM练习七:CRF中参数的学习)
前言: 本次实验主要任务是学习CRF模型的参数,实验例子和PGM练习3中的一样,用CRF模型来预测多张图片所组成的单词,我们知道在graph model的推理中,使用较多的是factor,而在grap ...
随机推荐
- C语言 知识点总结完美版
本文采用思维导图的方式撰写,更好的表述了各知识点之间的关系,方便大家理解和记忆.这个总结尚未包含C语言数据结构与算法部分,后续会陆续更新出来,文中有漏掉的知识点,还请大家多多指正. 总体上必须清楚的: ...
- [PLC]ST语言五:STL/RET/CMP/ZCP
一:STL/RET/CMP/ZCP 说明:简单的顺控指令不做其他说明. 控制要求:无 编程梯形图: 结构化编程ST语言: (*步进指令STL(EN,s);*) SET(M8002,S3); STL(T ...
- hdu2544最短路(dijkstra)
传送门 dijkstra #include<bits/stdc++.h> using namespace std; const int INF=0x3f3f3f3f; ; int dist ...
- Eclipse Photon没有Server选项的问题
安装Eclipse Photon版本的时候选择了Java开发,导致最后需要本地tomcat调试的时候找不到Server配置选项. ①在软件eclipse下的Help->InstallNew So ...
- MYSQL 数据库结构优化
数据库结构优化 优化数据大小 使表占用尽量少的磁盘空间.减少磁盘I/O次数及读取数据量是提升性能的基础原则.表越小,数据读写处理时则需要更少的内存,同时,小表的索引占用也相对小,索引处理也更加快速. ...
- 关于Maven的一点理解
maven是一个项目管理工具,主要作用是: 1.依赖管理(jar包,工程之间); 2.统一开发规范和工具.完成项目的一步构建 3.工程聚合.继承.依赖 其核心配置文件就是pom.xml:pom即Pro ...
- Daily Srum 10.21
到目前为止,我们组处在学习阶段,很多知识点都还不太清楚,所以现在我们还在看相关书籍和博客,任务. 而我们此间主要是在阅读一些材料: 陈谋一直在看学长的代码,其中C#的很多方式我都不太明白(尽管和Jav ...
- java实验1实验报告(20135232王玥)
实验一 Java开发环境的熟悉 一.实验内容 1. 使用JDK编译.运行简单的Java程序 2.使用Eclipse 编辑.编译.运行.调试Java程序 二.实验要求 1.没有Linux基础的同学建议先 ...
- 【每日scrum】第一次冲刺day3
学习安卓,和小伙伴讨论百度API调用的问题,最后决定自己写地图
- 手机连接wifi 访问本地服务器网站
手机连本地wifi后访问 http://192.168.155.1:8001/loc 版权声明:本文为博主原创文章,未经博主允许不得转载.