python爬虫之解析库正则表达式
上次说到了requests库的获取,然而这只是开始,你获取了网页的源代码,但是这并不是我们的目的,我们的目的是解析链接里面的信息,比如各种属性 @href @class span 抑或是p节点里面的文本内容,但是我们需要一种工具来帮我们寻找出这些节点,总不能让我们自己一个一个复制粘贴来完成吧,那样的话,还要程序员干嘛>>计算机是为了方便人们才被发明出来的.
这次我们使用一个非常好用的工具>>正则表达式,可能有的大佬已经听说过了,哦,就是那么一个东西,并说,不是用css选择器或者xpath,beautifulsoup来解析不是更好吗?当然,我开始的时候也是听大佬们这么说的,但是再一些简单的提取信息里,正则表达式的速度确实是最快的,而且有相同的结构的话,构造的表达式更快,关于正则表达式详解大家可以去百度一下>>正则表达式详解<<那里有更多的使用方法,我只是总结利用了一些我个人认为比较好用的正则表达式用法.
例如我们获取了以下的一个网页源代码:
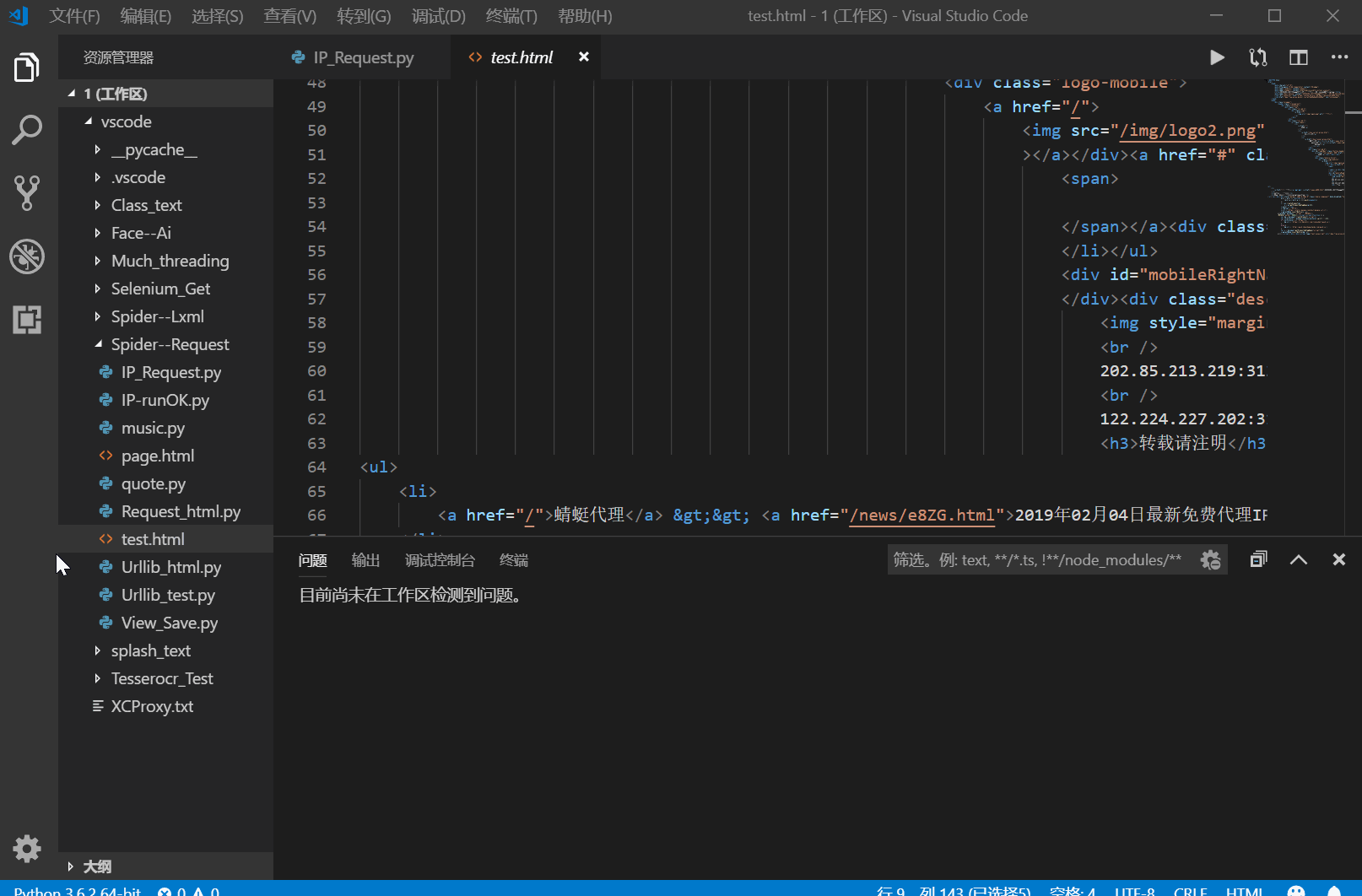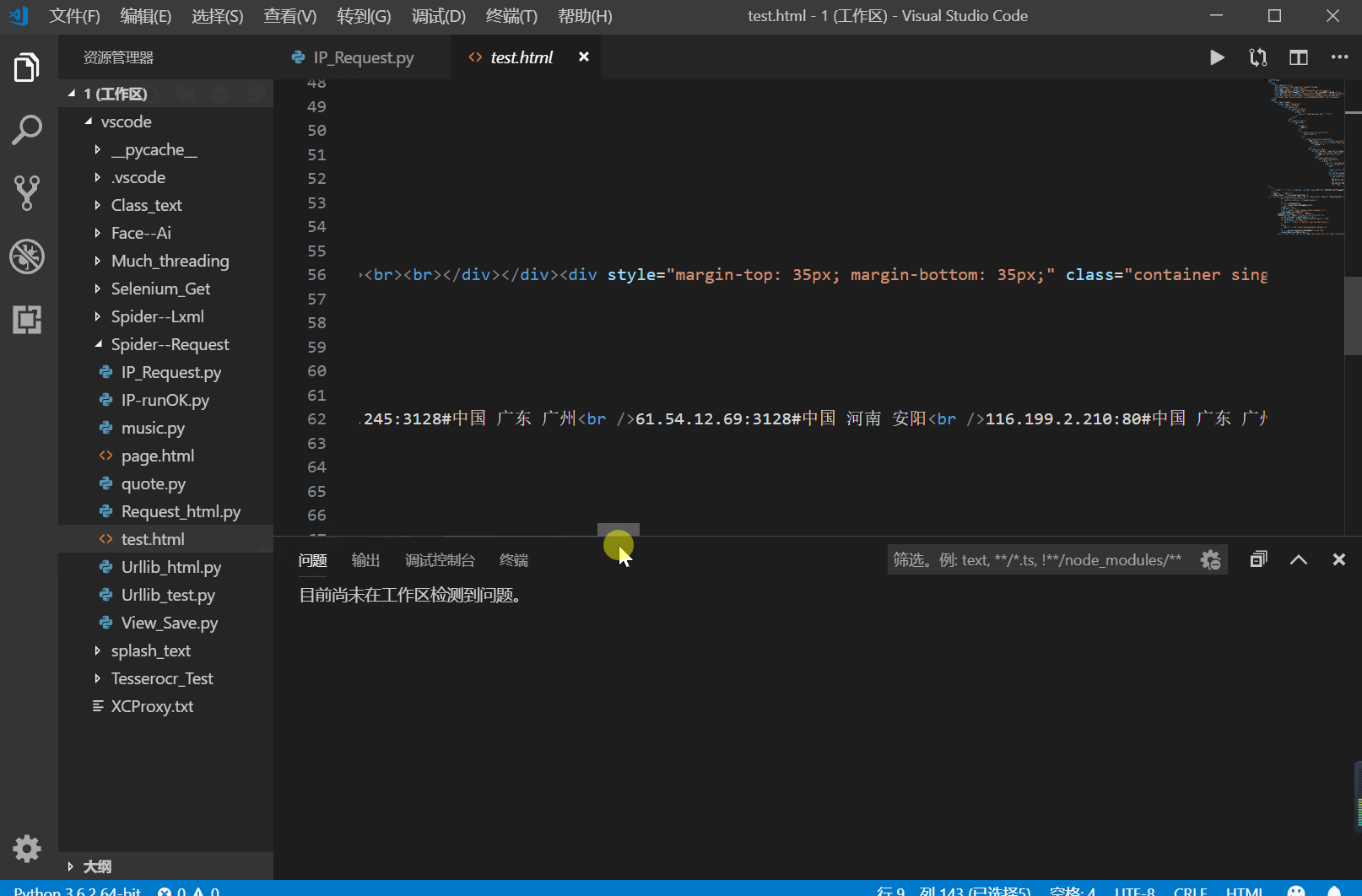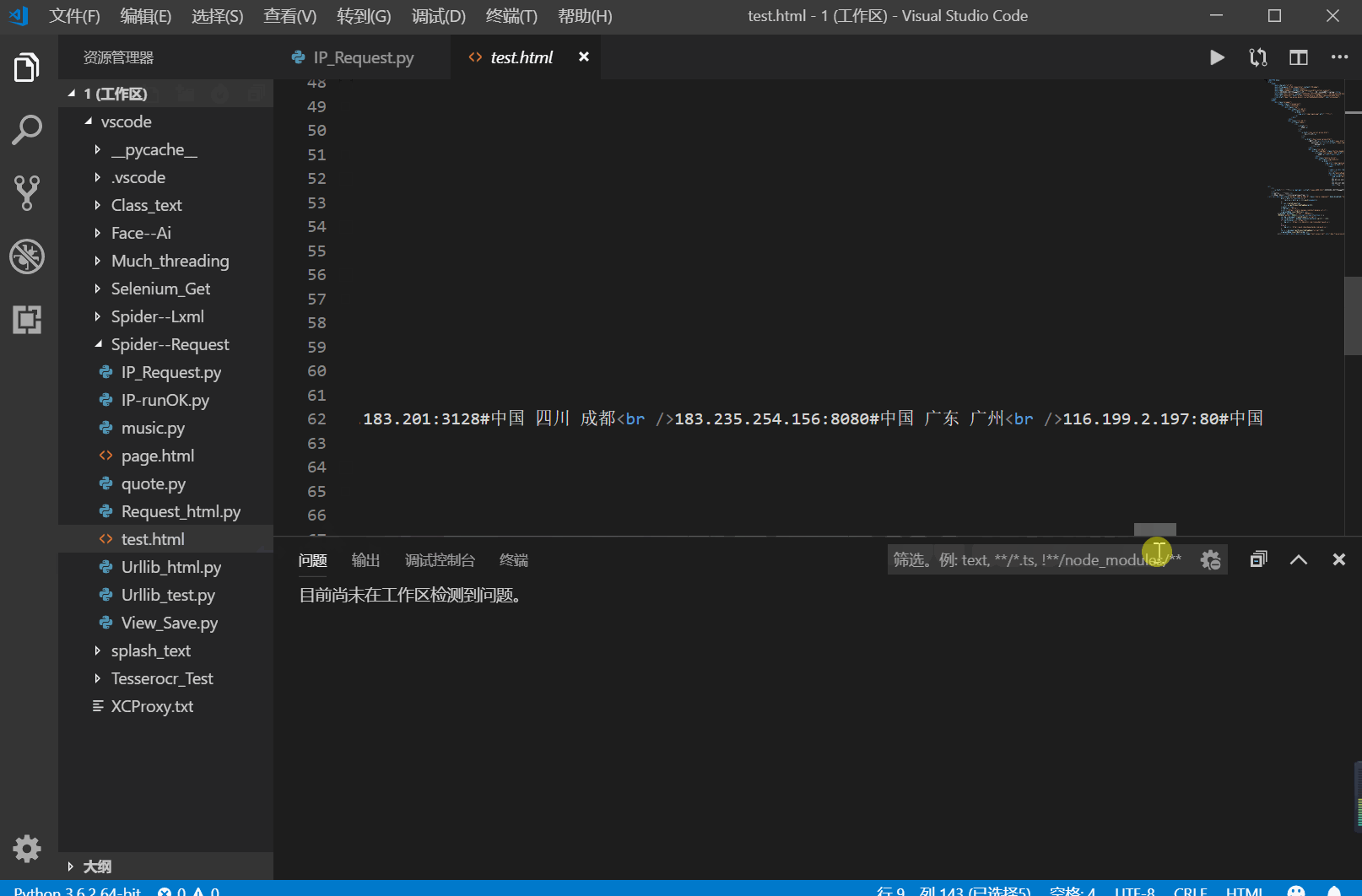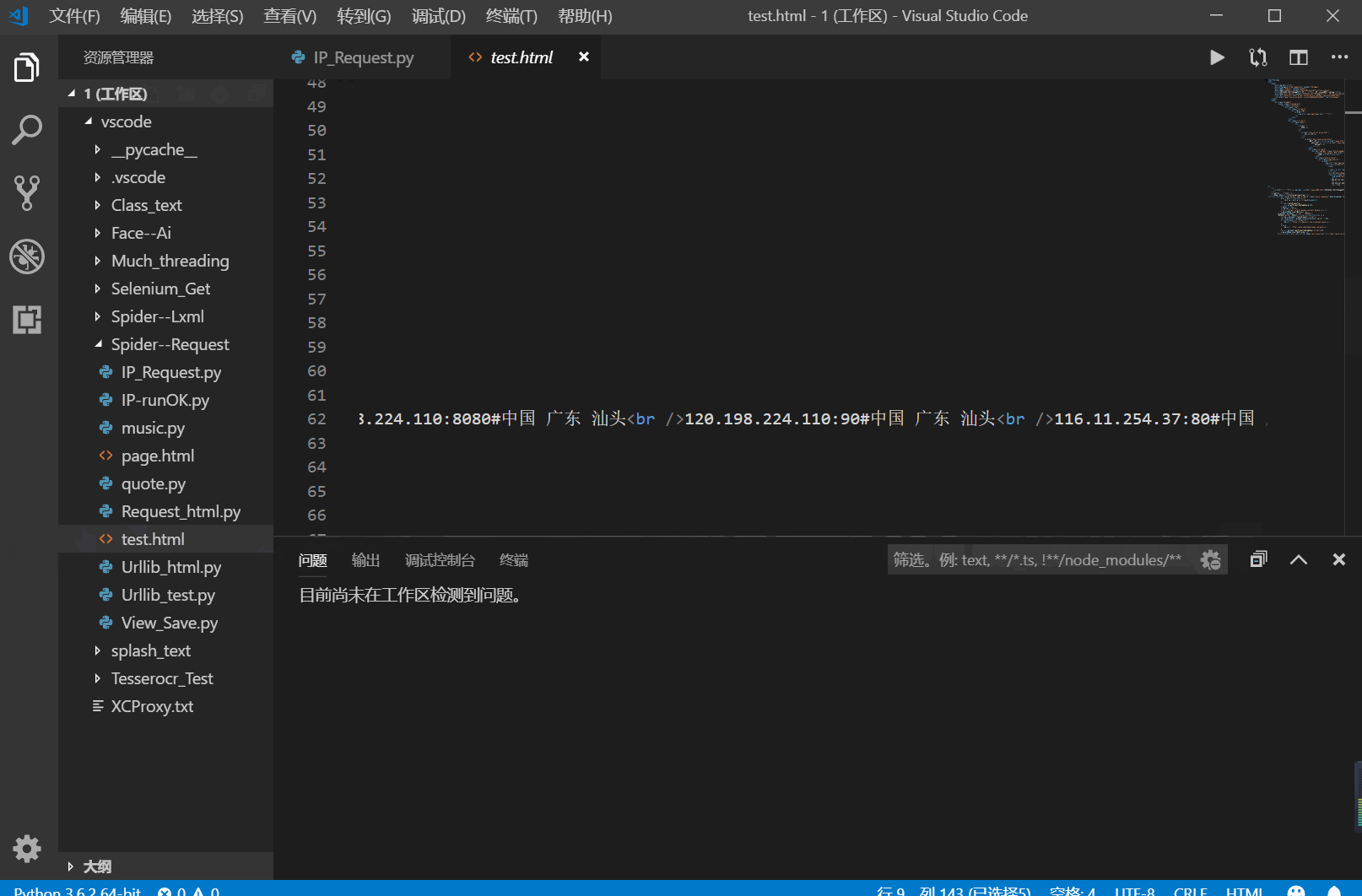
我们想要获取br节点里面的IP地址,怎么办呢/我们可以构造表达式 首先我们得了解一下元字符:
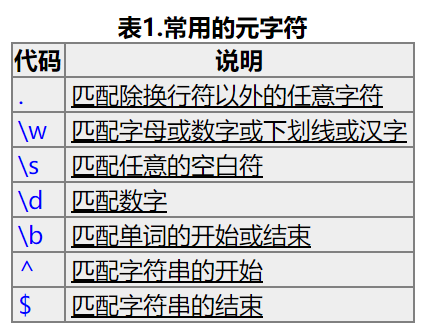
这里说明了匹配得用法,\w就是匹配除了非字符的,例如空格 , $%^.!@#这些全部别省略而过,因为不符合匹配规则,想要匹配空格,就要换成\s 这里我们再了解一下限定符的概念:
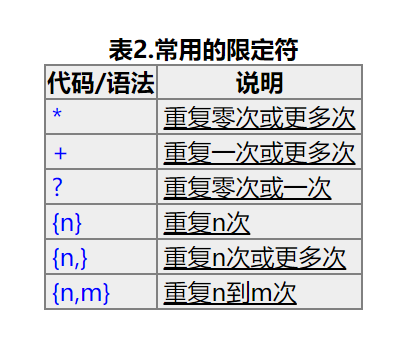
限定符的意思根据我的理解是匹配该符合匹配规则的次数,如果没有要求,它可能匹配出全部给你,也可能只匹配第一个结果给你,限定符就起到了匹配次数的效果,让你做到想使用匹配规则多少次就多少次.下面是一些常用的正则表达式:

可能大家看的有些疑惑,那是因为你之前没有接触过表达式,但是你参照一下上面的规则,再参悟一下,多尝试匹配,看看错在哪里,大概坚持一两天,你就会有一种豁然开朗的感觉,哦,原来是这么一回事啊,我理解一下一个规则用法,比如用户名的匹配规则:<< /^是匹配的开始 然后到[a-z0-9 是说匹配从a到z和0到9的所有字符,然后是_-,,它说明在里面可以匹配下划线_和字符- ,{3,16}是匹配从3次到16次,意思是说该用户可能限制在3到16字节,超过就没有意义了,多了就会导致提取信息的不纯洁性了>> 当然有时候我们想偷懒怎么办,这些规则有太复杂了,光是构造就得花费很多时间了,这时候,我最喜欢得懒惰限定符出现了,先看规则:

这里可以这样理解 (.*)是匹配尽可能多的字符串,(.*?)是匹配尽可能匹配少的字符 在python中()表示返回匹配得内容,内容为()里面得字符,如果你想获取@href的属性,直接构造为('.*?href="(.*?)" ,h.*?')就可以获取href的属性了,不过要记住,它返回的是一个列表的形式,所以你想要实现分行显示,还要对列表进行遍历,输入到文本中,继而实现简单的爬取信息.演示如下:
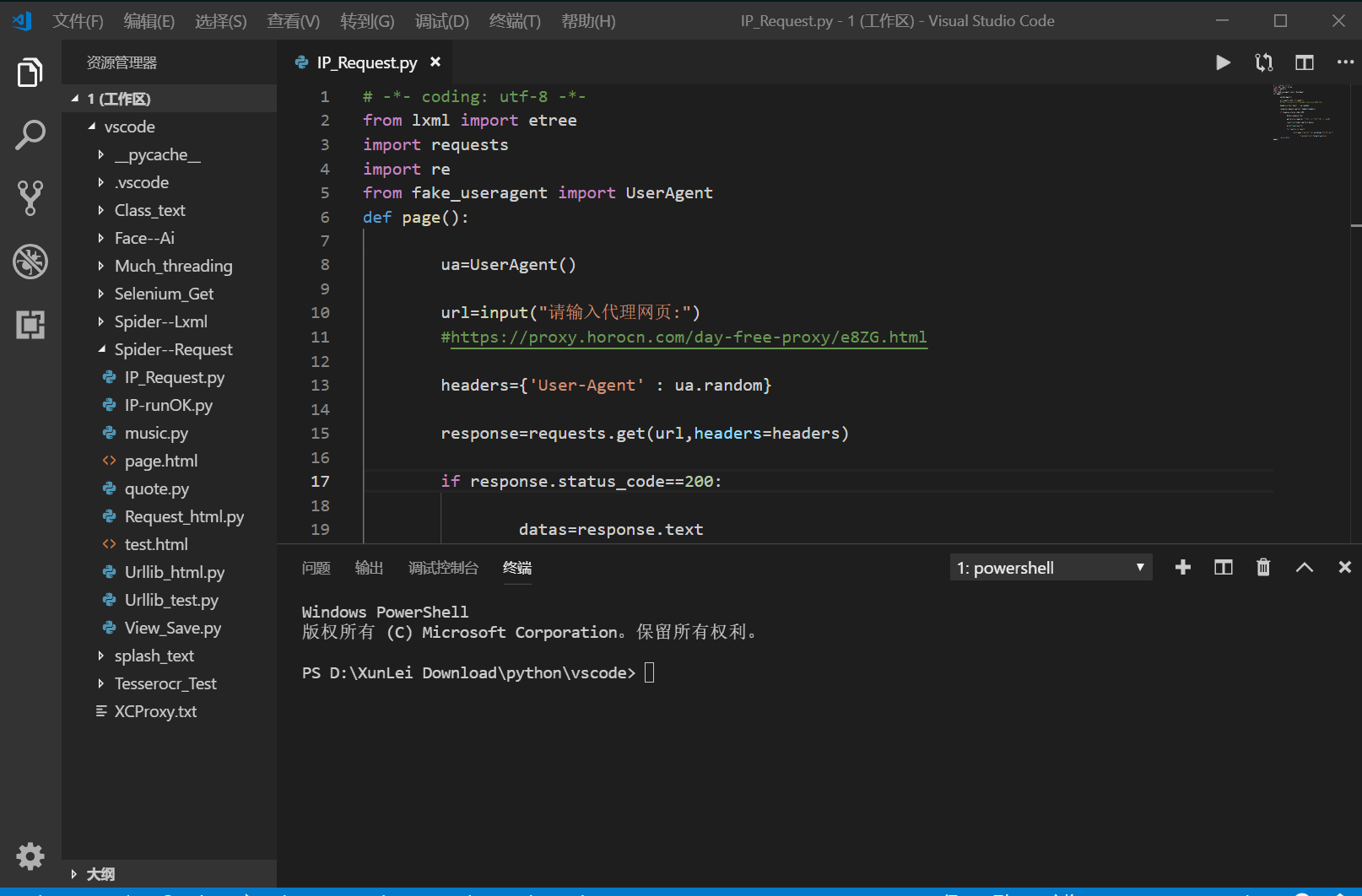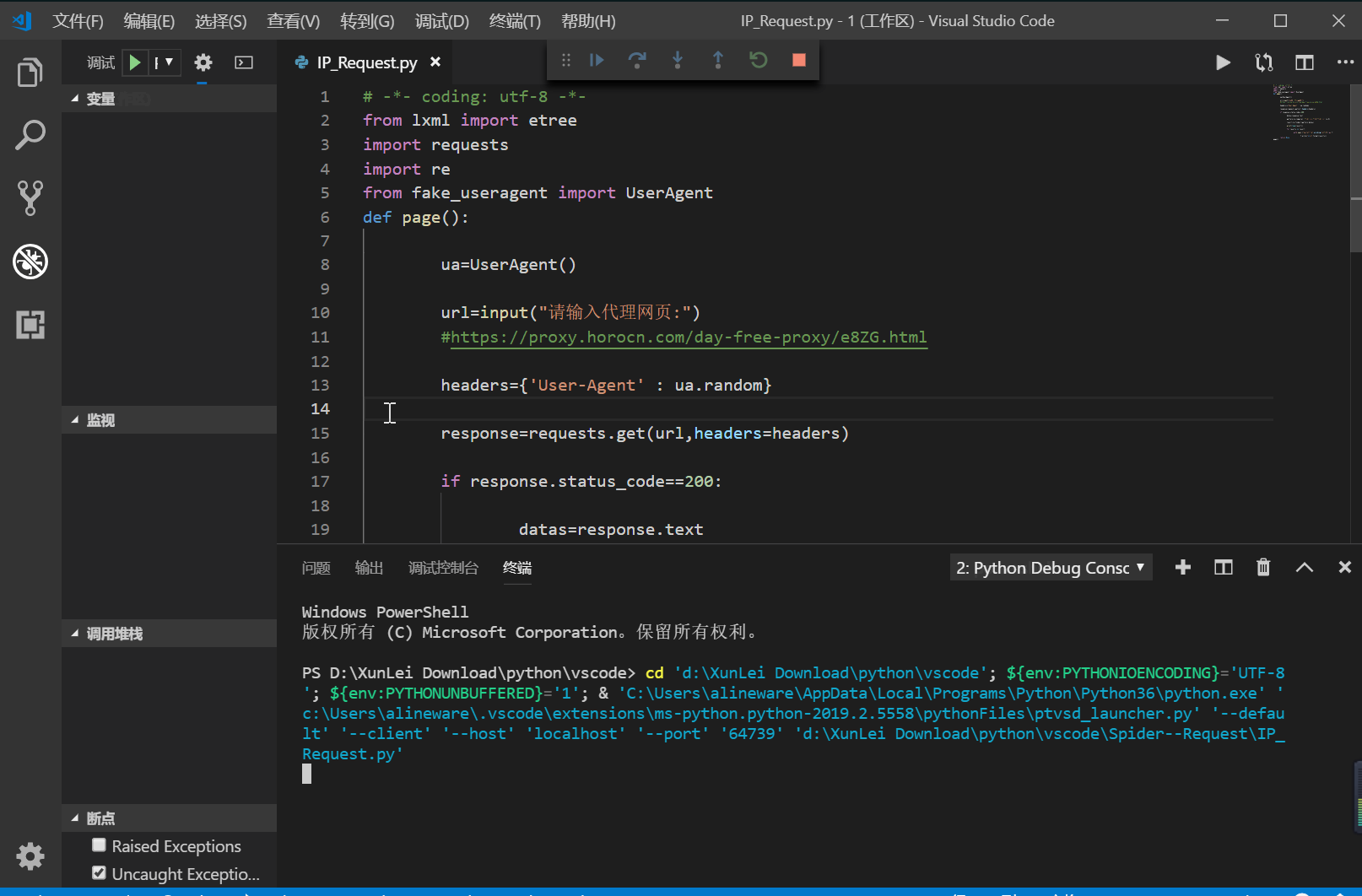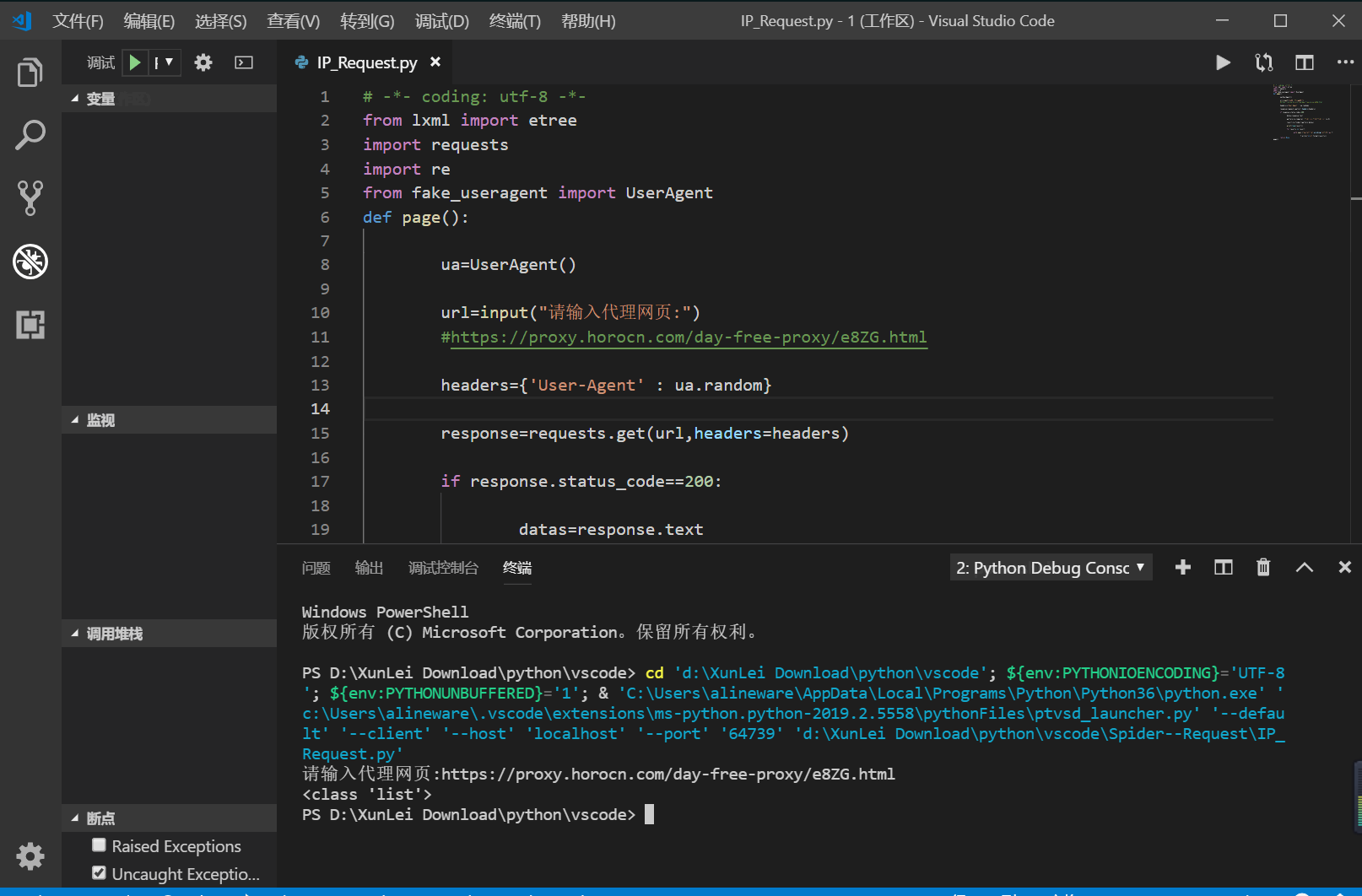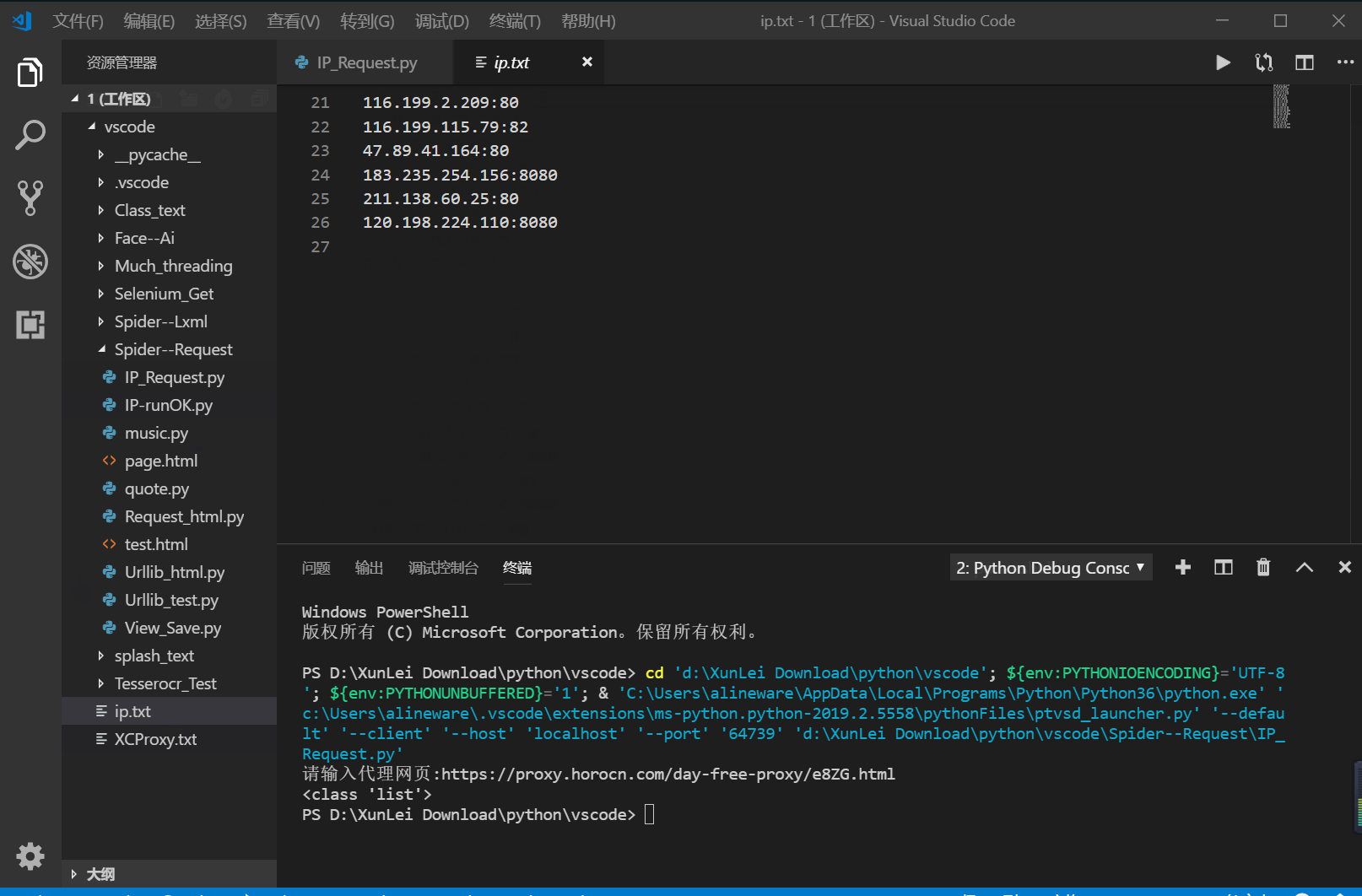
我把我自己写的源代码贴出来,可能不是很完善,只是一个很简单的函数,哪里有缺陷大佬们指出一下
# -*- coding: utf-8 -*-
# author :HXM
from lxml import etree
import requests
import re
from fake_useragent import UserAgent
def page(): ua=UserAgent() url=input("请输入代理网页:")
#https://proxy.horocn.com/day-free-proxy/e8ZG.html headers={'User-Agent' : ua.random} response=requests.get(url,headers=headers) if response.status_code==200: datas=response.text pattern=re.compile('.*?<br />(.*?)#.*?<br />',re.S)#re.S表示换行匹配,不受行数限制,python常用pattern来封装表达式规则,极大方便了调用 result=re.findall(pattern,datas) print(type(result)) for results in result: with open ("ip.txt","a",encoding="utf-8") as f: f.write("{}\n".format(results))
return None
page()
这里还要说一个重要的匹配方式,是python中独有的
import re #表示导入正则表达式
re.match表示是从第一字符开始匹配,如果规则没有从第一个字符开始表示,尽管你想要的信息就在HTML里面,你也匹配不出来
re.search表示只匹配符合规则的第一字符并返回结果,对匹配限定符规则是无效的,即不遵守限定匹配次数
re.findall表示匹配所有符合规则的字符,遵守限定次数规则,最常用的匹配re库函数
好了,正则表达式就介绍到这里,不过这只是皮毛而已,不过对我们目前应该是够用的,后面还有零断宽言等,大家有兴趣可以了解一下>
python爬虫之解析库正则表达式的更多相关文章
- python爬虫数据解析之正则表达式
爬虫的一般分为四步,第二个步骤就是对爬取的数据进行解析. python爬虫一般使用三种解析方式,一正则表达式,二xpath,三BeautifulSoup. 这篇博客主要记录下正则表达式的使用. 正则表 ...
- Python爬虫【解析库之beautifulsoup】
解析库的安装 pip3 install beautifulsoup4 初始化 BeautifulSoup(str,"解析库") from bs4 import BeautifulS ...
- python爬虫三大解析库之XPath解析库通俗易懂详讲
目录 使用XPath解析库 @(这里写自定义目录标题) 使用XPath解析库 1.简介 XPath(全称XML Path Languang),即XML路径语言,是一种在XML文档中查找信息的语言. ...
- Python爬虫【解析库之pyquery】
该库跟jQuery的使用方法基本一样 http://pyquery.readthedocs.io/ 官方文档 解析库的安装 pip3 install pyquery 初始化 1.字符串初始化 htm ...
- python爬虫之解析库Beautiful Soup
为何要用Beautiful Soup Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式, 是一个 ...
- python爬虫数据解析之BeautifulSoup
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. BeautfulSoup是python爬虫三 ...
- Mac os 下 python爬虫相关的库和软件的安装
由于最近正在放暑假,所以就自己开始学习python中有关爬虫的技术,因为发现其中需要安装许多库与软件所以就在这里记录一下以避免大家在安装时遇到一些不必要的坑. 一. 相关软件的安装: 1. h ...
- Python爬虫入门七之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
随机推荐
- SQLServer创建链接服务器
--SQLServer创建链接服务器----1.访问接口中Oracle接口 属性 选择 允许进程内-- --删除链接服务器EXEC master.dbo.sp_dropserver @server=N ...
- 20165318 预备作业3 Linux安装及学习
Linux安装及学习 一.VirtualBox和Ubuntu的安装 我安装的是VirtualBox 5.2.6和Ubuntu 16.04 LTS,安装过程按照老师博客中的步骤依次进行,出现了以下几个问 ...
- 【洛谷】【lca+结论】P3398 仓鼠找sugar
[题目描述:] 小仓鼠的和他的基(mei)友(zi)sugar住在地下洞穴中,每个节点的编号为1~n.地下洞穴是一个树形结构.这一天小仓鼠打算从从他的卧室(a)到餐厅(b),而他的基友同时要从他的卧室 ...
- 关于ssm框架使用mysql控制台出现警告问题
使用MySQL时,总会时不时出现这种警告信息 警告信息:WARN: Establishing SSL connection without server's identity verification ...
- JVM(二)GC算法和垃圾收集器
前言 垃圾收集器(Garbage Collection)通常被成为GC,诞生于1960年MIT的Lisp语言.上一篇介绍了Java运行时区域的各个部分,其中程序计数器.虚拟机栈.本地方法栈3个区域随线 ...
- Jmeter之断言
Jmeter中的断言类似于LR中的检查点,是在请求的返回层面上加的一个判断机制.因为请求成功了,不代表结果就一定是对的,还要看返回(LR中亦如此,脚本回放没报错,不代表你的业务成功了,需要自己去相应的 ...
- P1004 方格取数
题目描述 设有N*N的方格图(N<=9),我们将其中的某些方格中填入正整数,而其他的方格中则放 人数字0.如下图所示(见样例): A 0 0 0 0 0 0 0 0 0 0 13 0 0 6 0 ...
- P1569 [USACO11FEB]属牛的抗议
题目描述 Farmer John's N (1 <= N <= 100,000) cows are lined up in a row and numbered 1..N. The cow ...
- Blktrace原理简介及使用
Blktrace简介 Blktrace是一个用户态的工具,用来收集磁盘IO信息中当IO进行到块设备层(block层,所以叫blk trace)时的详细信息(如IO请求提交,入队,合并,完成等等一些列的 ...
- BZOJ4033 [HAOI2015]树上染色
本来是考虑, $ f[x][i][0/1] $ 表示 $ x $ 子树中有$i$个黑点,且 $ x $ 是白点/黑点.但是这里的答案是要统计不同的子树的贡献的.所以就gg了. 看了题解. 应该是要设$ ...