UNDERSTANDING THE GAUSSIAN DISTRIBUTION
UNDERSTANDING THE GAUSSIAN DISTRIBUTION
Randomness is so present in our reality that we are used to take it for granted. Most of the phenomena which surround us have been generated by random processes. Hence, our brain is very good at recognise these random patterns. And is even better at spotting phenomena that should be random but they are actually aren’t. And this is when problems arise. Most software such as Unity or GameMaker simply lack the tools to generate realistic random numbers. This tutorial will introduce the Gaussian distribution, which plays a fundamental role in statistics since it is at the heart of many random phenomena in our everyday life.
Introduction
Let’s imagine you want to generate some random points on a plane. They can be enemies, trees, or whichever other entity you might thing of. The easiest way to do it in Unity is:
|
1
2
3
4
|
Vector3 position = new Vector3();
position.x = Random.Range(min,max),
position.y = Random.Range(min,max);
transform.position = position;
|
Using Random.Range will produce points distributed like in the blue box below. Some points might be closer than others, but globally they are all spread all over the place with the same density. We find approximately as many points on the left as there are on the right.
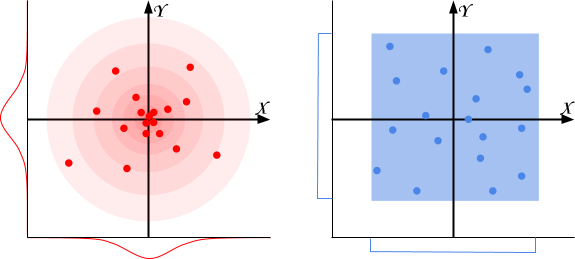
Many natural behaviours don’t follow this distribution. They are, instead, similar to the diagram on the left: these phenomena are Gaussian distributed. Thumb rule: when you have a natural phenomenon which should be around a certain value, the Gaussian distribution could be the way to go. For instance:
- Damage: the amount of damage an enemy or a weapon inflicts;
- Particle density: the amount of particles (sparkles, dust, …) around a particular object;
- Grass and trees: how grass and trees are distributed in a biome; for instance, the position of plants near a lake, or the scatter or rocks around a mountain;
- Enemy generation: if you want to generate enemies with random stats, you can design an “average” enemy and use the Gaussian distribution to get natural variations out of it.
This tutorial will explain what a Gaussian distribution exactly is, and why it appears in all the above mentioned phenomena.
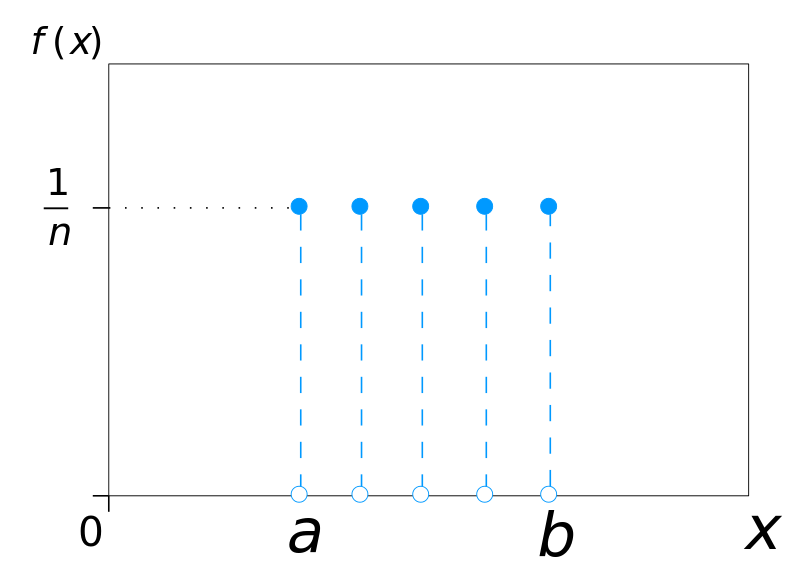
Understanding uniform distributions
When you’re throwing a dice, there is one chance out of six to get a 6. Incidentally, every face of the dice also has the same chance. Statistically speaking, throwing a dice samples from a uniform discrete distribution (left). Every uniform distribution can be intuitively represented with a dice with  faces. Each face
faces. Each face  has the same probability of being chosen
has the same probability of being chosen  . A function such as Random.Range, instead, returns values which are continuously uniformly distributed (right) over a particular range (typically, between 0 and 1).
. A function such as Random.Range, instead, returns values which are continuously uniformly distributed (right) over a particular range (typically, between 0 and 1).
 |
 |
In many cases, uniform distributions are a good choice. Choosing a random card from a deck, for instance, can be modelled perfectly with Random.Range.
What is a Gaussian distribution
There are other phenomena in the natural domain which don’t follow a uniform distribution. If you measure the height of all the people in a room, you’ll find that certain ranges occur more often than others. The majority of people will have a similar height, while extreme tall or short people are rare to find. If you randomly choose a person from that room, his height is likely to be close to the average height. These phenomena typically follow a distribution called the Gaussian (or normal) distribution. In a Gaussian distribution the probability of a given value to occur is given by:

If a uniform distribution is fully defined with its parameter , a Gaussian distribution is defined by two parameters  and
and  , namely the mean and the variance. The mean translates the curve left or right, centring it on the value which is expected to occur most frequently. The standard deviation, as the name suggests, indicates how easy is to deviate from the mean.
, namely the mean and the variance. The mean translates the curve left or right, centring it on the value which is expected to occur most frequently. The standard deviation, as the name suggests, indicates how easy is to deviate from the mean.

When a variable  is generated by a phenomenon which is Gaussian distributed, it is usually indicated as:
is generated by a phenomenon which is Gaussian distributed, it is usually indicated as:

Converging to a Gaussian distribution
Surprisingly enough, the equation for a Gaussian distribution can be derived from a uniform distribution. Despite looking quite different, they are deeply connected. Now let’s imagine a scenario in which a drunk man has to walk straight down a line. At every step, he has a 50% chance of moving left, and another 50% chance of moving right. Where is most likely to find the drunk man after 5 step? And after 100?
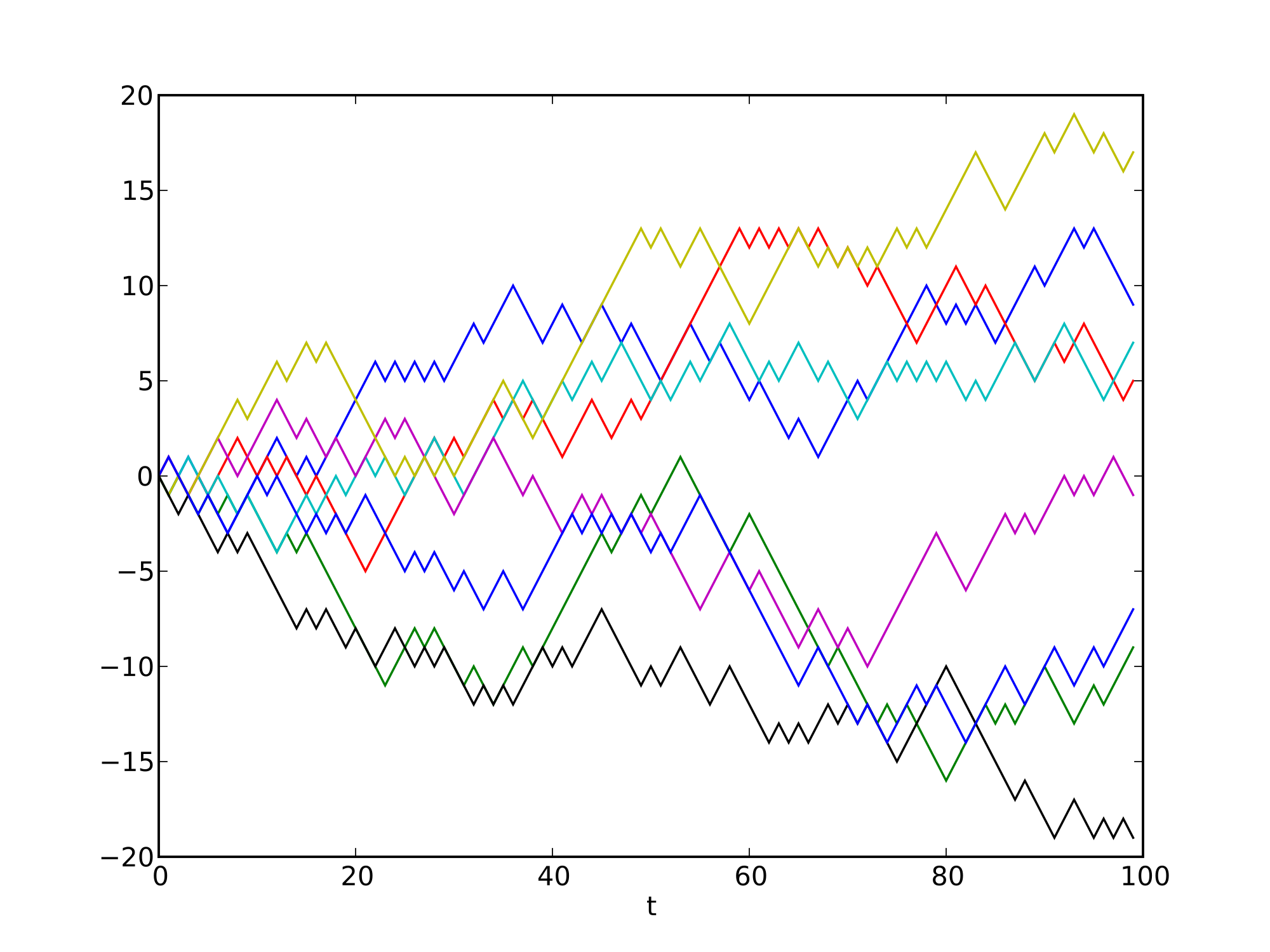
Since every step has the same probability, all of the above paths are equally likely to occur. Always going left is as likely as alternating left and right for the entire time. However, there is only one path which leads to his extreme left, while there are many more paths leading to the centre (more details here). For this reason, the drunk man is expected to stay closer to the centre. Having enough drunk men and enough time to walk, their final positions always approximate a Gaussian curve.

This concept can be explored without using actual drunk men. In the 19th century, Francis Galton came up with a device called bean machine: an old fashionedpachinko which allows for balls to naturally arrange themselves into the typical Gaussian bell.
This is related with the idea behind the central limit theorem; after a sufficiently large number of independent, well defined trials, results should approximate a Gaussian curve, regardless the underlying distribution of the original experiment.
Deriving the Gaussian distribution
If we look back at the bean machine, we can ask a very simple question: what is the probability for a ball to end up in a certain column? The answer depends on the number of right (or left) turns the ball makes. It is important to notice that the order doesn’t really matter: both (left, left, right) and (right, left, left) lead to the same column. And since there is a 50% change of going left or right at every turn, the question becomes: how many left turns  is the ball making over iterations (in the example above:
is the ball making over iterations (in the example above:  left turns over
left turns over  , iterations)? This can be calculated considering the chance of turning left times, with the chance of turning right
, iterations)? This can be calculated considering the chance of turning left times, with the chance of turning right  times:
times:  . This form, however, accounts for only a single path: the one with left turns followed by right turns. We need to take into account all the possible permutations since they all lead to the same result. Without going too much into details, the number of permutations is described by the expression
. This form, however, accounts for only a single path: the one with left turns followed by right turns. We need to take into account all the possible permutations since they all lead to the same result. Without going too much into details, the number of permutations is described by the expression  :
:

This is known as the binominal distribution and it answers the question of how likely is to obtain successes out of independent experiments, each one with the same probability  .
.
Even so, it still doesn’t look very Gaussian at all. The idea is to bring to the infinity, switching from a discrete to a continuous distribution. In order to do that, we first need to expand the binomial coefficient using its factorial form:

then, factorial terms should be approximated using the Stirling’s formula:

The rest of the derivation is mostly mechanic and incredibly tedious; if you are interested, you can find it here. As a result we obtain:

with  and
and  .
.
Conclusion
This loosely explains why the majority of recurring, independent “natural” phenomena are, indeed, normally distributed. We are so surrounded by this distribution that our brain is incredibly good at recognise patterns which don’t follow it. This is the reason why, especially in games, is important to understand that some aspects must follow a normal distribution in order to be believable.
In the next post I’ll explore how to generate Gaussian distributed numbers, and how they can be used safely in your game.
- Part 1: Understanding the Gaussian distribution
- Part 2: How to generate Gaussian distributed numbers
Ways to Support
In the past months I've been dedicating more and more of my time to the creation of quality tutorials, mainly about game development and machine learning. If you think these posts have either helped or inspired you, please consider supporting me.
UNDERSTANDING THE GAUSSIAN DISTRIBUTION的更多相关文章
- 一起啃PRML - 1.2.4 The Gaussian distribution 高斯分布 正态分布
一起啃PRML - 1.2.4 The Gaussian distribution 高斯分布 正态分布 @copyright 转载请注明出处 http://www.cnblogs.com/chxer/ ...
- 正态分布(Normal distribution)又名高斯分布(Gaussian distribution)
正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学.物理及project等领域都很重要的概率分布,在统计学的很多方面有着重大的影 ...
- 高斯分布(Gaussian Distribution)的概率密度函数(probability density function)
高斯分布(Gaussian Distribution)的概率密度函数(probability density function) 对应于numpy中: numpy.random.normal(loc= ...
- 广义逆高斯分布(Generalized Inverse Gaussian Distribution)及修正贝塞尔函数
1. PDF generalized inverse Gaussian distribution (GIG) 是一个三参数的连续型概率分布: f(x)=(a/b)p/22Kp(ab−−√)xp−1e− ...
- 【翻译】拟合与高斯分布 [Curve fitting and the Gaussian distribution]
参考与前言 英文原版 Original English Version:https://fabiandablander.com/r/Curve-Fitting-Gaussian.html 如何通俗易懂 ...
- [Bayes] Why we prefer Gaussian Distribution
最后还是选取一个朴素直接的名字,在此通过手算体会高斯的便捷和神奇. Ref: The Matrix Cookbook 注意,这里的所有变量默认都为多元变量,不是向量就是矩阵.多元高斯密度函数如下: 高 ...
- 吴恩达机器学习笔记56-多元高斯分布及其在误差检测中的应用(Multivariate Gaussian Distribution & Anomaly Detection using the Multivariate Gaussian Distribution)
一.多元高斯分布简介 假使我们有两个相关的特征,而且这两个特征的值域范围比较宽,这种情况下,一般的高斯分布模型可能不能很好地识别异常数据.其原因在于,一般的高斯分布模型尝试的是去同时抓住两个特征的偏差 ...
- 吴恩达机器学习笔记53-高斯分布的算法(Algorithm of Gaussian Distribution)
如何应用高斯分布开发异常检测算法呢? 异常检测算法: 对于给定的数据集
- 吴恩达机器学习笔记52-异常检测的问题动机与高斯分布(Problem Motivation of Anomaly Detection& Gaussian Distribution)
一.问题动机 异常检测(Anomaly detection)问题是机器学习算法的一个常见应用.这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题. 给 ...
随机推荐
- 结对项目-四则运算出题程序(GUI版)
目录: 一.致搭档(含项目地址) 二.PSP(planning) 三.结对编程中对接口的设计 四.计算模块接口的设计与实现过程 五.计算模块接口部分的性能改进 六.计算模块部分单元测试展示 七.计算模 ...
- 复利计算测试(C语言)
对我们和复利计算程序,写单元测试. 有哪些场景? 期待的返回值 写测试程序. 运行测试. 测试模块 测试输入 预期结果 运行结果 bug跟踪 计算终值 (本金,年限,利率) 终值 1 (100 ...
- Delphi控件-复合控件【转】
复合控件复合控件是Delphi控件中非常重要的一种控件,复合控件就是将两个或两个以上的控件重新组合成一个新的控件.例如TspinEdit.TlabeledEdit.TDBNavigator等就是复合控 ...
- Error: Unable to access jarfile D:\Apache\apache-jmeter-3.0\bin\ApacheJMete.jar
双击jmeter.bat后,在cmd窗口显示Error: Unable to access jarfile D:\Apache\apache-jmeter-3.0\bin\ApacheJMete.ja ...
- strtr、str_replace()、substr_replace、preg_replace之间的区别
strtr(string, from, to): 逐个字符开始替换,以from跟to中长度较较短的一个为准,例如: strtr("aidengni","ai", ...
- [日常工作] SQLSERVER 数据库出问题..搜索到的有用的网页信息
Finding a table name from a page ID By: Paul Randal Posted on: September 25, 2014 1:42 am (Check o ...
- 3 vue-router 的默认hash 改mode:history去除#号 传参
npm install vue-router --save //安装 传参
- Python Matplotlib绘图库 安装
一般我们在做科学计算的时候,首先会想到的是matlab,但是呢,一想到matlab安装包那么大,我就有点不想说什么了. Matplotlib 是python最著名的绘图库,它提供了一整套和matlab ...
- CentOS 6.5以上版本安装mysql 5.7 完整版教程(修订版)
转载自:https://codeday.me/collect/20170524/21861.html 1: 检测系统是否自带安装mysql # yum list installed | grep my ...
- VMware 三种网络模式的区别
VMware 三种网络模式的区别 VMware 三种网络模式的区别 我们首先说一下VMware的几个虚拟设备 VMnet0:用于虚拟桥接网络下的虚拟交换机 VMnet1:用于虚拟Host-Only网络 ...