多表查询、Navicat软件、PyMySQL模块
多表查询、Navicat软件、PyMySQL模块
一、多表查询的两种方法
1.准备工作
1.创建数据库
create databases db4
2.使用数据库
use db4
3.表数据准备
create table dep(
id int primary key auto_increment,
name varchar(20)
);
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
4.插入数据
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营'),
(205,'财务');
insert into emp(name,sex,age,dep_id) values
('jason','male',18,200),
('dragon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
2.第一种:连表操作
*****1. inner join # 内链接 只链接两张表共有的部分
select * from emp inner join dep on emp.dep_id=dep.id
2. left join # 左链接 以左表为基准展示所有的数据若没有数据用NULL补充
select * from emp left join dep on emp.dep_id=dep.id
3. right jion # 右链接 以右表为基准展示所有的数据若没有数据用NULL补充
select * from emp right join dep on emp.dep_id=dep.id
4. union # 全链接 了解即可
select * from emp left join dep on emp.dep_id=dep.id union select * from emp right join dep on emp.dep_id=dep.id
3.第二种:子查询
将一条SQL语句用括号当成另一条SQL语句的查询条件 子查询类似于日常生活中的解决问题的思路
题目:求姓名是某某的员工部门名称
思路:
步骤一:先根据员工姓名获取部门编号
select dep_id from emp where name='jason'
步骤二:再根据部门编号获取部门名称
select name from dep where id=200
真正的步骤:
select name from dep where id=(select dep_id from emp where name='jason');
总结与结论:
连接表操作之后可以实现连续连接N多张表 大概思路就是将拼接之后的表起别名当成第一张表与其他表连接 以此类推
实际操作过程中 大部分情况下两种方法配合着使用可能性更多一些 但是具体用的时候根据实际需求再选择方法即可。
二、多表查询练习题
1.课堂多表查询练习题
1、查询所有的课程的名称以及对应的任课老师姓名
2、查询平均成绩大于八十分的同学的姓名和平均成绩
3、查询没有报李平老师课的学生姓名
4、查询没有同时选修物理课程和体育课程的学生姓名
5、查询没有同时选修物理课程和体育课程的学生姓名(报了两门或者一门不报的都不算)
2.以上练习题对应的SQL语句详细
1、查询所有的课程的名称以及对应的任课老师姓名
# 1.先确定需要用到几张表 课程表 分数表
# 2.预览表中的数据 做到心中有数
-- select * from course;
-- select * from teacher;
# 3.确定多表查询的思路 连表 子查询 混合操作
-- SELECT
-- teacher.tname,
-- course.cname
-- FROM
-- course
-- INNER JOIN teacher ON course.teacher_id = teacher.tid;
2、查询平均成绩大于八十分的同学的姓名和平均成绩
# 1.先确定需要用到几张表 学生表 分数表
# 2.预览表中的数据
-- select * from student;
-- select * from score;
# 3.根据已知条件80分 选择切入点 分数表
# 求每个学生的平均成绩 按照student_id分组 然后avg求num即可
-- select student_id,avg(num) as avg_num from score group by student_id having avg_num>80;
# 4.确定最终的结果需要几张表 需要两张表 采用连表更加合适
-- SELECT
-- student.sname,
-- t1.avg_num
-- FROM
-- student
-- INNER JOIN (
-- SELECT
-- student_id,
-- avg(num) AS avg_num
-- FROM
-- score
-- GROUP BY
-- student_id
-- HAVING
-- avg_num > 80
-- ) AS t1 ON student.sid = t1.student_id;
3.查询没有报李平老师课的学生姓名
# 1.先确定需要用到几张表 老师表 课程表 分数表 学生表
# 2.预览每张表的数据
# 3.确定思路 思路1:正向筛选 思路2:筛选所有报了李平老师课程的学生id 然后取反即可
# 步骤1 先获取李平老师教授的课程id
-- select tid from teacher where tname = '李平老师';
-- select cid from course where teacher_id = (select tid from teacher where tname = '李平老师');
# 步骤2 根据课程id筛选出所有报了李平老师的学生id
-- select distinct student_id from score where course_id in (select cid from course where teacher_id = (select tid from teacher where tname = '李平老师'))
# 步骤3 根据学生id去学生表中取反获取学生姓名
-- SELECT
-- sname
-- FROM
-- student
-- WHERE
-- sid NOT IN (
-- SELECT DISTINCT
-- student_id
-- FROM
-- score
-- WHERE
-- course_id IN (
-- SELECT
-- cid
-- FROM
-- course
-- WHERE
-- teacher_id = (
-- SELECT
-- tid
-- FROM
-- teacher
-- WHERE
-- tname = '李平老师'
-- )
-- )
-- )
4、查询没有同时选修物理课程和体育课程的学生姓名(报了两门或者一门不报的都不算)
# 1.先确定需要的表 学生表 分数表 课程表
# 2.预览表数据
# 3.根据给出的条件确定起手的表
# 4.根据物理和体育筛选课程id
-- select cid from course where cname in ('物理','体育');
# 5.根据课程id筛选出所有跟物理 体育相关的学生id
-- select * from score where course_id in (select cid from course where cname in ('物理','体育'))
# 6.统计每个学生报了的课程数 筛选出等于1的
-- select student_id from score where course_id in (select cid from course where cname in ('物理','体育'))
-- group by student_id
-- having count(course_id) = 1;
# 7.子查询获取学生姓名即可
-- SELECT
-- sname
-- FROM
-- student
-- WHERE
-- sid IN (
-- SELECT
-- student_id
-- FROM
-- score
-- WHERE
-- course_id IN (
-- SELECT
-- cid
-- FROM
-- course
-- WHERE
-- cname IN ('物理', '体育')
-- )
-- GROUP BY
-- student_id
-- HAVING
-- count(course_id) = 1
-- )
5、查询挂科超过两门(包括两门)的学生姓名和班级
# 1.先确定涉及到的表 分数表 学生表 班级表
# 2.预览表数据
-- select * from class
# 3.根据条件确定以分数表作为起手条件
# 步骤1 先筛选掉大于60的数据
-- select * from score where num < 60;
# 步骤2 统计每个学生挂科的次数
-- select student_id,count(course_id) from score where num < 60 group by student_id;
# 步骤3 筛选次数大于等于2的数据
-- select student_id from score where num < 60 group by student_id having count(course_id) >= 2;
# 步骤4 连接班级表与学生表 然后基于学生id筛选即可
SELECT
student.sname,
class.caption
FROM
student
INNER JOIN class ON student.class_id = class.cid
WHERE
student.sid IN (
SELECT
student_id
FROM
score
WHERE
num < 60
GROUP BY
student_id
HAVING
count(course_id) >= 2
);
三、小知识点补充说明
1.concat与cancat_ws
concat用于分组之前
select concat(name,'|',sex) from emp;
concat_ws拼接多个字段并且中间的连接符一致
select concat('|',name,sex,age,dep_id) from emp;
2.表相关SQL补充
alter table 表名 rename 新表名; # 修改表名
alter table 表名 add 字段名 字段类型(数字) 约束条件; # 添加字段
alter table 表名 add 字段名 字段类型(数字) 约束条件 after 已有字段;
alter table 表名 add 字段名 字段类型(数字) 约束条件 first; # 修改字段
alter table 表名 change 旧字段名 新字段名 字段类型(数字) 约束条件;
alter table 表名 modify 字段名 新字段类型(数字) 约束条件;
alter table 表名 drop 字段名; # 删除字段
四、可视化软件Navicat
第三方开发的用来充当数据库客户端的简单快捷的操作界面 底层的本质还是SQL 能够操作数据库对的第三方可视化软件有很多 其中针对MySQL最出名的就Navicat
1.软件下载
直接在浏览器下载即可 但是这款软件是收费的 要么花钱买 要么破解
当然会直接选择破解 哈哈哈哈
2.破解方式
详细破解过程 戳这里>>>https://www.bilibili.com/read/cv16884052
3.常用操作
有些功能可能需要自己修改SQL预览
创建库、表、记录、外键
逆向数据库到模型、模型创建
新建查询可以编写SQL语句并自带提示功能
SQL语句注释语法
--、#、\**\
运行、转储SQL文件
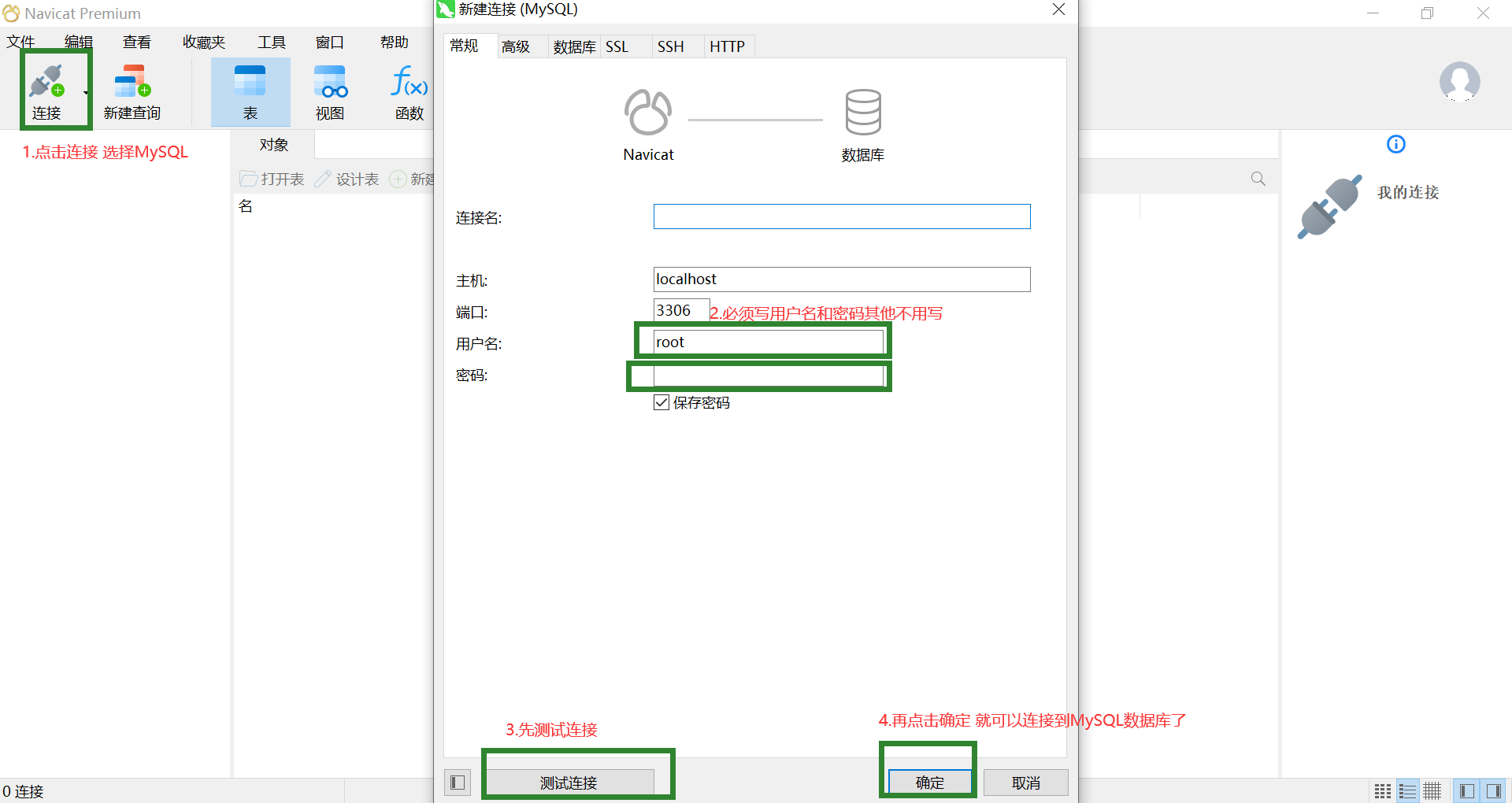
1.连接数据库操作
2.创建数据库操作

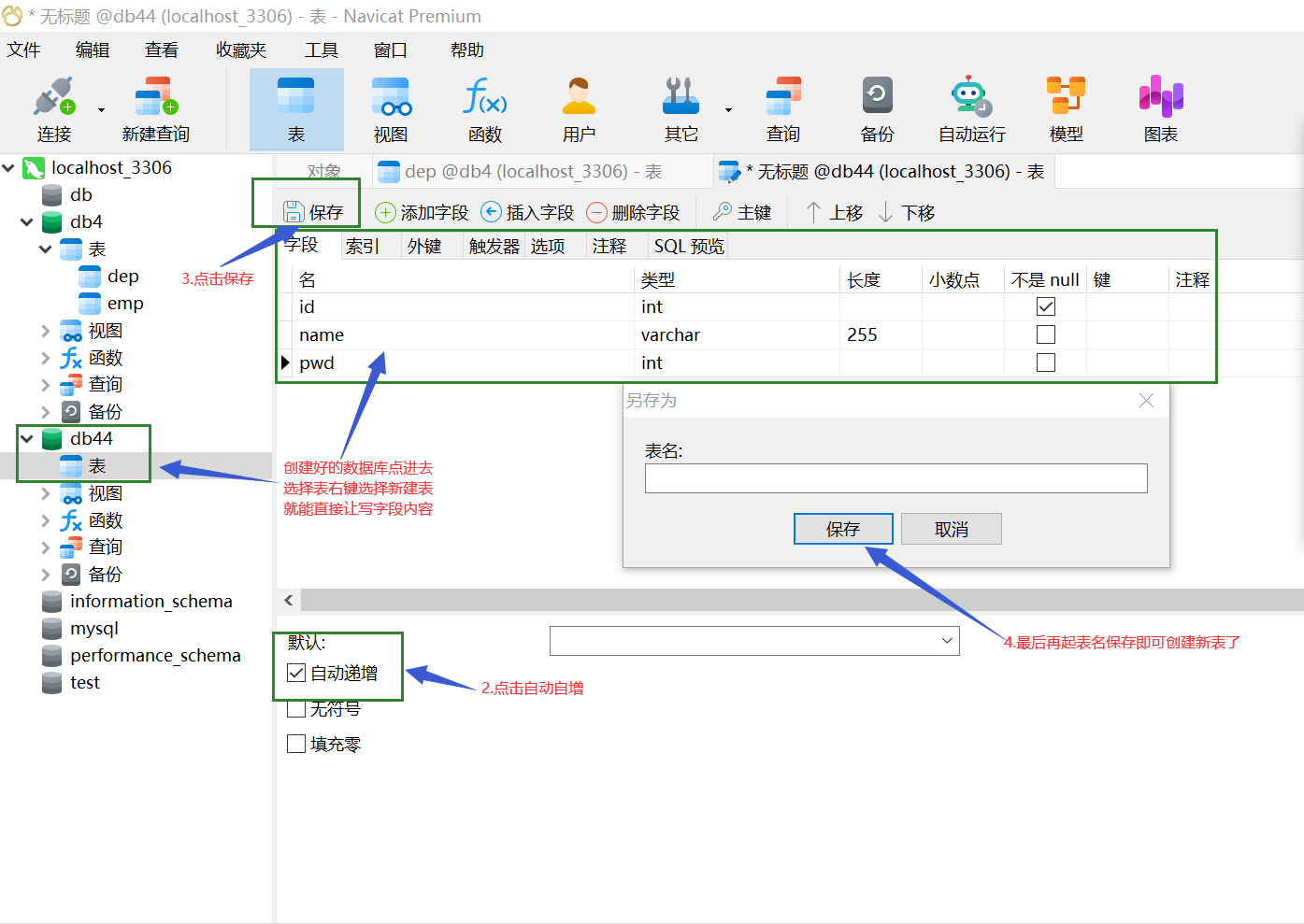
3.创建表操作
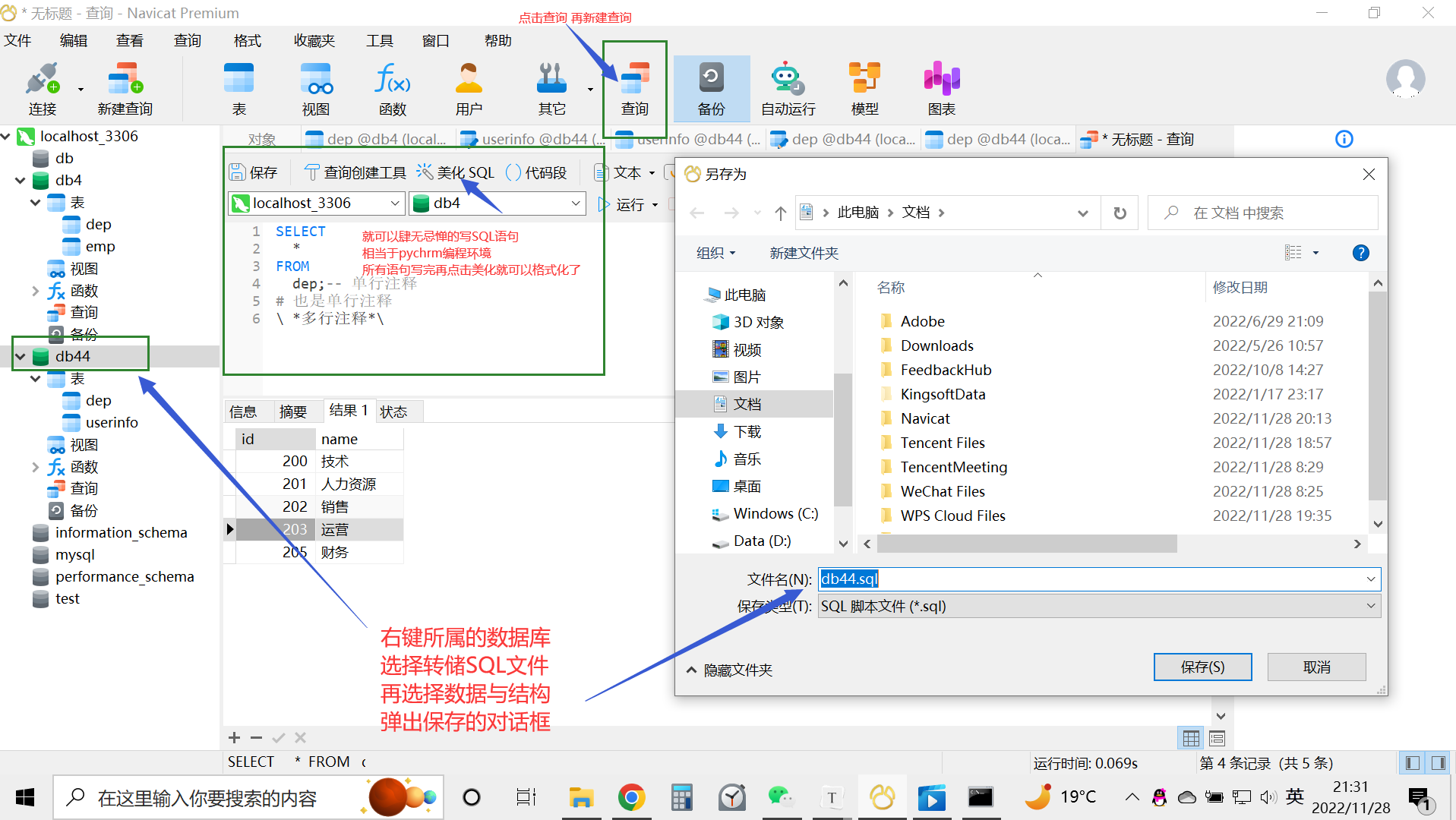
4.转储数据保存操作
五、python操作MySQL
1.pycharm安装第三方模块pymysql的详细步骤
1.先点击file 再点击settings
2.先点击project:项目名 再点击PythonInterpreter
3.左键双击第三方模块列表框调出模块搜索对话框
4.输入PyMySQL模块名
5.给Spscify version打对勾
6.点击 Install Package 就可以
2.python操作MySQL的基本操作
import pymysql
# 1.链接MySQL服务端
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='1998',
db='db4',
charset='utf8mb4',
autocommit=True
)
# 2.产生游标对象
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 括号内步写参数 结果是元组 写了之后[{},{}]
# 3.遍写SQL语句
sql = 'select * from emp;'
# 4.发送SQL语句
affect_rows = cursor.execute(sql)
print(affect_rows)
# 5.获取SQL语句执行之后的结果
res = cursor.fetchall()
print(res)
3.pymysql模块 知识点补充说明
1.获取数据
fetchall() # 获取所有的结果
fetchone() # 获取结果集的第一个数据
fetchmany(5) # 获取指定数量的结果集
cursor.scroll(1,'relative') # 基于当前位置往后移动
cursor.scroll(0,'absolute') # 基于数据的开头往后移动
2.增删改查
autocommit=True # 直接配置(自动确认) 强烈推荐 这样就安心进行增删改查了
conn.commit() # 需要写代码(二次确认) 不太推荐 因为容易忘记
多表查询、Navicat软件、PyMySQL模块的更多相关文章
- MySQL多表查询,Navicat使用,pymysql模块,sql注入问题
一.多表查询 #建表 create table dep( id int, name varchar(20) ); create table emp( id int primary key auto_i ...
- navicat工具 pymysql模块
目录 一 IDE工具介绍(Navicat) 二 pymysql模块 一 IDE工具介绍(Navicat) 生产环境还是推荐使用mysql命令行,但为了方便我们测试,可以使用IDE工具,我们使用Navi ...
- 数据库——可视化工具Navicat、pymysql模块、sql注入问题
数据库--可视化工具Navicat.pymysql模块.sql注入问题 Navicat可视化工具 Navicat是数据库的一个可视化工具,可直接在百度搜索下载安装,它可以通过鼠标"点点点&q ...
- 数据库 - Navicat与pymysql模块
一.Nabicat 在生产环境中操作MySQL数据库还是推荐使用命令行工具mysql,但在我们自己开发测试时, 可以使用可视化工具Navicat,以图形界面的形式操作MySQL数据库 官网下载:htt ...
- navicat 使用 pymysql模块
新健库 ,新增字段+类型+约束 设计表:外键(自增) 新建查询 建立表模型 /* 数据导入: Navicat Premium Data Transfer Source Server : localho ...
- day03 mysql外键 表的三种关系 单表查询 navicat
day03 mysql navicat 一.完整性约束之 外键 foreign key 一个表(关联表: 是从表)设置了外键字段的值, 对应的是另一个表的一条记录(被关联表: 是主 ...
- day43——多表查询、Navicat工具的使用、pymysql模块
day43 多表查询 笛卡尔积--不经常用 将两表所有的数据一一对应,生成一张大表 select * from dep,emp; # 两个表拼一起 select * from dep,emp wher ...
- 数据库 --- 4 多表查询 ,Navicat工具 , pymysql模块
一.多表查询 1.笛卡儿积 查询 2.连接 语法: ①inner 显示可构成连接的数据 mysql> select employee.id,employee.name,department ...
- python 全栈开发,Day63(子查询,MySQl创建用户和授权,可视化工具Navicat的使用,pymysql模块的使用)
昨日内容回顾 外键的变种三种关系: 多对一: 左表的多 对右表一 成立 左边的一 对右表多 不成立 foreign key(从表的id) refreences 主表的(id) 多对多 建立第三张表(f ...
- MySQL:记录的增删改查、单表查询、约束条件、多表查询、连表、子查询、pymysql模块、MySQL内置功能
数据操作 插入数据(记录): 用insert: 补充:插入查询结果: insert into 表名(字段1,字段2,...字段n) select (字段1,字段2,...字段n) where ...; ...
随机推荐
- 使用PBIS将Linux加入域
使用PBIS将Linux加入域 很多企业已经部署的微软的活动目录,为了方便管理,可以把Linux加入域.网上流传了很多把Linux加入域的方法,感觉比较复杂,并且似乎并没有真正的加入域.只是完成 ...
- 创建一个 autocomplete 输入系统 - 前端 + 后端
文章转载自:https://mp.weixin.qq.com/s/uqchdrkhdFsof0ZFtECujg 我们经常在网站搜索输入时,会帮我们提醒自动完成的功能,比如: 图片 当我们在百度上搜索 ...
- 【C++】从零开始的CS:GO逆向分析2——配置GLFW+IMGUI环境并创建透明窗口
[C++]从零开始的CS:GO逆向分析2--配置GLFW+IMGUI环境并创建透明窗口 使用的环境:Visual Studio 2017,创建一个控制台程序作为工程文件 1.配置glfw 在git ...
- 一个终端工具竟然有AI功能?使用了1天我立马把其他终端全卸载了!太香了!
前言 平常工作需要频繁使用终端工具,有一个好的命令行终端工具是非常重要的. 尤其是使用mac的小伙伴,估计不少人都觉得iterm2才是最好的终端工具. 其实起初我也是这么觉得的,但是最近直到我使用了这 ...
- Netty 学习(八):新连接接入源码说明
Netty 学习(八):新连接接入源码说明 作者: Grey 原文地址: 博客园:Netty 学习(八):新连接接入源码说明 CSDN:Netty 学习(八):新连接接入源码说明 新连接的接入分为3个 ...
- vivo互联网机器学习平台的建设与实践
vivo 互联网产品团队 - Wang xiao 随着广告和内容等推荐场景的扩展,算法模型也在不断演进迭代中.业务的不断增长,模型的训练.产出迫切需要进行平台化管理.vivo互联网机器学习平台主要业务 ...
- 非Navicat破解延长14天试用时间
延长Navicat使用时长 Navicat作为一套多连接数据库开发工具,十分好用,购买正版太过昂贵,破解版过于麻烦,有时候还会有安全问题,好在我们有14天的试用时间,我们可以从这个方面入手 对于有能力 ...
- List接口中的常用方法
void add(int index, Object ele):在index位置插入ele元素boolean addAll(int index, Collection eles):从index位置开始 ...
- JUC(8)JMM
文章目录 1.JMM 2.volatile 3.单例模式 1.JMM Volatile是java虚拟机提供轻量级的同步机制 1.保证可见性 2.不保证原子性 3.禁止指令重排 什么是JMM java内 ...
- 忘记了99乘法表啥样的了,python打印下看看
for i in range(1,10): for j in range(1, i+1): if i == j: print(j, "x", i, "=", i ...