使用 Docker 安装 Elastic Stack 8.0 并开始使用
文章转载自:https://mp.weixin.qq.com/s/fLnIzbbqYfILS6uCvGctXw
运行 Elasticsearch
docker network create elastic
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.0.0
docker run --name es-node01 --net elastic -p 9200:9200 -p 9300:9300 -it docker.elastic.co/elasticsearch/elasticsearch:8.0.0
当我们第一次启动 Elasticsearch 时,以下安全配置会自动发生:
- 为传输层和 HTTP 层生成证书和密钥。
- 传输层安全 (TLS) 配置设置写入 elasticsearch.yml。
- 为弹性用户生成密码。
- 为 Kibana 生成一个注册令牌。
--------------------------------------------------------------------------------
-> Elasticsearch security features have been automatically configured!
-> Authentication is enabled and cluster connections are encrypted.
-> Password for the elastic user (reset with `bin/elasticsearch-reset-password -u elastic`):
21=0VbI9nz+kjR69l1WT
-> HTTP CA certificate SHA-256 fingerprint:
05661cff7bef5f59ae84442e25d9f1821662f82ed958b1b1da6147950943ecc3
-> Configure Kibana to use this cluster:
* Run Kibana and click the configuration link in the terminal when Kibana starts.
* Copy the following enrollment token and paste it into Kibana in your browser (valid for the next 30 minutes):
eyJ2ZXIiOiI4LjAuMCIsImFkciI6WyIxNzIuMjQuMC4yOjkyMDAiXSwiZmdyIjoiMDU2NjFjZmY3YmVmNWY1OWFlODQ0NDJlMjVkOWYxODIxNjYyZjgyZWQ5NThiMWIxZGE2MTQ3OTUwOTQzZWNjMyIsImtleSI6Ilc5TWktMzRCTVZaSFJZRHZXc3piOmk5b1RXWkdFUV95VVoxeUFtU0N0bFEifQ==
-> Configure other nodes to join this cluster:
* Copy the following enrollment token and start new Elasticsearch nodes with `bin/elasticsearch --enrollment-token <token>` (valid for the next 30 minutes):
eyJ2ZXIiOiI4LjAuMCIsImFkciI6WyIxNzIuMjQuMC4yOjkyMDAiXSwiZmdyIjoiMDU2NjFjZmY3YmVmNWY1OWFlODQ0NDJlMjVkOWYxODIxNjYyZjgyZWQ5NThiMWIxZGE2MTQ3OTUwOTQzZWNjMyIsImtleSI6IlhkTWktMzRCTVZaSFJZRHZXc3pvOnRoQWxhcmxYU3Myb0ZHX2g5czA1Z1EifQ==
If you're running in Docker, copy the enrollment token and run:
`docker run -e "ENROLLMENT_TOKEN=<token>" docker.elastic.co/elasticsearch/elasticsearch:8.0.0`
--------------------------------------------------------------------------------
复制生成的密码和注册令牌并将其保存在安全位置。这些值仅在你第一次启动 Elasticsearch 时显示。你将使用这些将 Kibana 注册到你的 Elasticsearch 集群并登录。
注意:如果需要重置 elastic 用户或其他内置用户的密码,请运行 elasticsearch-reset-password 工具。要为 Kibana 或 Elasticsearch 节点生成新的注册令牌,请运行 elasticsearch-create-enrollment-token 工具。这些工具在 Elasticsearch bin 目录中可以找到。
安装及运行 Kibana
docker pull docker.elastic.co/kibana/kibana:8.0.0
docker run --name kib-01 --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.0.0
请注意在上面,我们使用了 --net 来定义 network。请使用和上面在 Elasticsearch 安装中一样的 network。
在上面,它让我到地址 http://0.0.0.0:5601/?code=915472 去配置 Kibana。在浏览器中打开上面的地址:
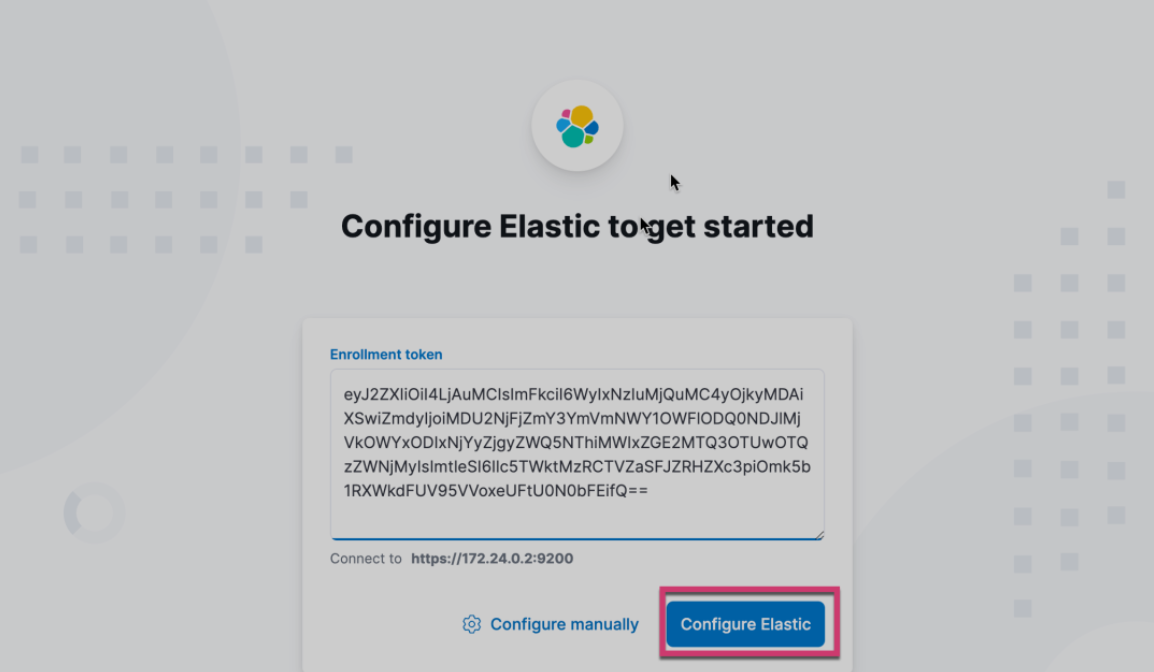
把在 Elasticsearch 启动时的 Kibana enrollment token 拷贝进上面的输入框,并点击 Configure Elastic:
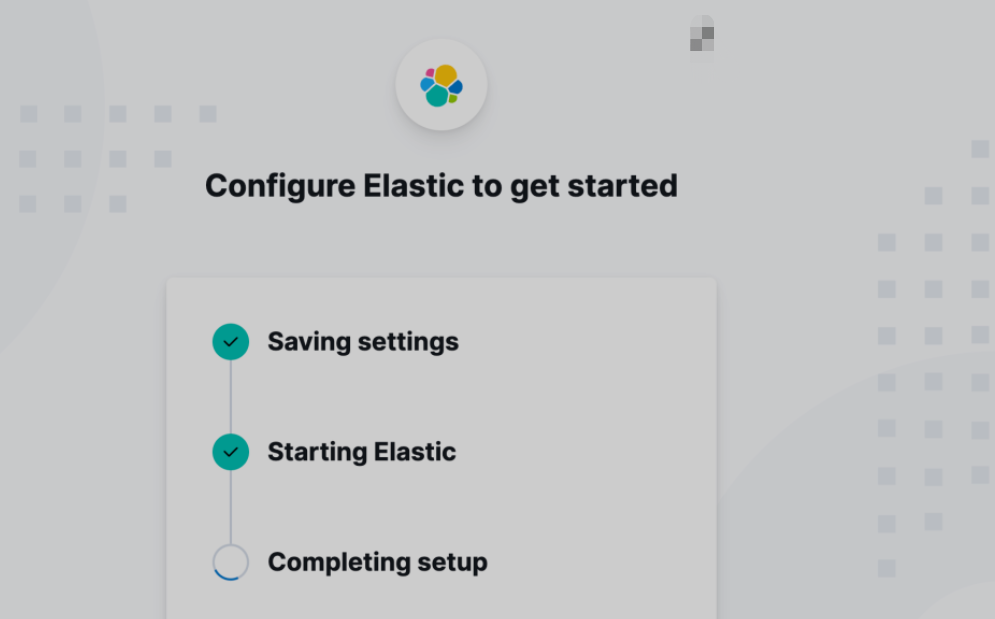
等配置完毕后,我们把之前生成的 elastic 超级用户的密码输入进如下的登录页面:

点击 Log in,这样我们就进行入到 Kibana 的界面:

在上面,默认的情况是添加 integrations。这个是用来摄入数据到 Elasticsearch 中的。在今天的展示中,我就先不进行展示了。我们点击 Explore on my own:
这样我们就成功地进入到 Kibana 界面了。
至此,我们已经成功地通过 docker 启动了 Elasticsearch 及 Kibana。
发送请求到 Elasticsearch
使用 REST API 向 Elasticsearch 发送数据和其他请求。这使你可以使用任何发送 HTTP 请求的客户端(例如 curl)与 Elasticsearch 交互。你还可以使用 Kibana 的控制台向 Elasticsearch 发送请求。
不能像之前的这种方法来获取数据:
curl -X GET http://localhost:9200/
这其中的原因是 Elasticsearch 由于启动了 https 连接,我们必须使用证书来访问 Elasticsearch。Elasticsearch 的访问地址为 https://localhost:9200,而不是 http://localhost:9200。那么我们该如何获取这个证书呢?
通过如下的命令来登录容器:
docker exec -it es-node01 /bin/bash
可以通过如下的方式来找到 Elasticsearch 在启动时生成的证书位置:

在上面,我们可以看到 Elasticsearch 所生成的证书。这个证书的名称叫做 http_ca.crt。我们可以通过如下的方式来把这个证书拷贝出来:
docker cp es-node01:/usr/share/elasticsearch/config/certs/http_ca.crt .
有了这个证书,我们可以使用如下的命令通过 curl 来访问 Elasticsearch:
curl -X GET --cacert ./http_ca.crt -u elastic:21=0VbI9nz+kjR69l1WT https://localhost:9200/
在上面的命令中,请记住需要替换上面的 -u 中的用户名及密码。另外注意的是我们访问的地址是 https://localhost:9200/ 而不是以前的 http://localhost:9200。
上面的命令执行的结果为:
$ curl -X GET --cacert ./http_ca.crt -u elastic:21=0VbI9nz+kjR69l1WT https://localhost:9200/
{
"name" : "438986615af6",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "STCnb4M6SMmvzEmFf6bwmw",
"version" : {
"number" : "8.0.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "1b6a7ece17463df5ff54a3e1302d825889aa1161",
"build_date" : "2022-02-03T16:47:57.507843096Z",
"build_snapshot" : false,
"lucene_version" : "9.0.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
添加数据
将数据作为称为文档的 JSON 对象添加到 Elasticsearch。Elasticsearch 将这些文档存储在可搜索的索引中。
对于时间序列数据,例如日志和指标,你通常将文档添加到由多个自动生成的支持索引组成的数据流中。
数据流需要与其名称匹配的索引模板。Elasticsearch 使用这个模板来配置流的后备索引。发送到数据流的文档必须具有 @timestamp 字段。
添加单个文档
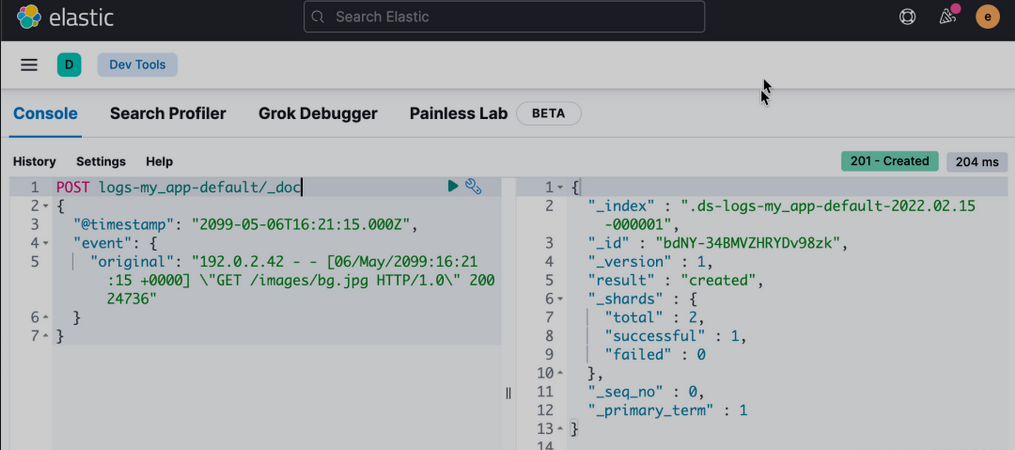
提交以下索引请求以将单个日志条目添加到 logs-my_app-default 数据流。由于 logs-my_app-default 不存在,请求会使用内置的 logs-*-* 索引模板自动创建它。
POST logs-my_app-default/_doc
{
"@timestamp": "2099-05-06T16:21:15.000Z",
"event": {
"original": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \"GET /images/bg.jpg HTTP/1.0\" 200 24736"
}
}
响应包括 Elasticsearch 为文档生成的元数据:
- 包含文档的支持
_index。Elasticsearch 会自动生成支持索引的名称。 - 索引中文档的唯一
_id。
添加多个文档
# 使用 _bulk 端点在一个请求中添加多个文档。批量数据必须是换行符分隔的 JSON (NDJSON)。每行必须以换行符 (\n) 结尾,包括最后一行。
PUT logs-my_app-default/_bulk
{ "create": { } }
{ "@timestamp": "2099-05-07T16:24:32.000Z", "event": { "original": "192.0.2.242 - - [07/May/2020:16:24:32 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0" } }
{ "create": { } }
{ "@timestamp": "2099-05-08T16:25:42.000Z", "event": { "original": "192.0.2.255 - - [08/May/2099:16:25:42 +0000] \"GET /favicon.ico HTTP/1.0\" 200 3638" } }
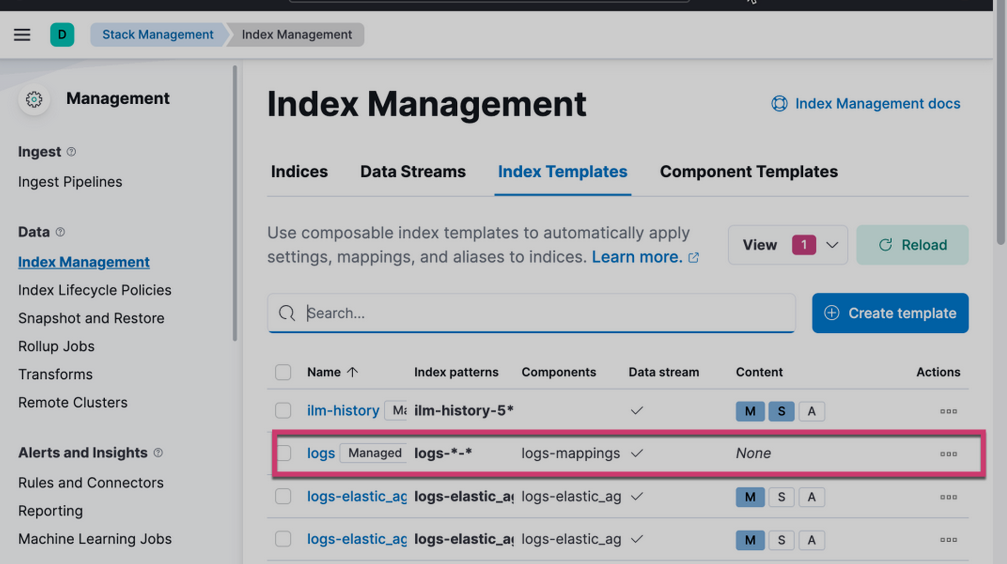
如果这个时候我们使用如下的命令来查看当前的索引:
GET _cat/indices
我们会发现:
yellow open .ds-logs-my_app-default-2022.02.15-000001 a4I6Rzj_S6yPC0Dww6OzTg 1 1 3 0 8.3kb 8.3kb
我们可以看到没有我们之前的那种我们想要的 logs-my_app-default 索引名,这是因为我们的索引名匹配内置的索引模板 logs-*-*:

使用 Docker 安装 Elastic Stack 8.0 并开始使用的更多相关文章
- docker安装elastic search和kibana
安装目标 使用docker安装elastic search和kibana,版本均为7.17.1 安装es 1. docker pull 去dockerhub看具体版本,这里用7.17.1 docker ...
- Elastic:用 Docker 部署 Elastic Stack
文章转载自:https://elasticstack.blog.csdn.net/article/details/100919273 前提条件 首选需要在主机上安装好docker和docker-com ...
- centos7用docker安装单节点redis4.0.11
[root@localhost conf]# docker search redisINDEX NAME DESCRIPTION STARS OFFICIAL AUTOMATEDdocker.io d ...
- 创建多个节点的集群 - Elastic Stack 8.0
文章转载自:https://mp.weixin.qq.com/s/k6u9Q2nebW9qgZMghQwJng 详述如何安装3个节点的 Elasticsearch 集群.我将使用 Docker 来进行 ...
- 2 ubuntu 16.04 安装Elastic Stack
一: 安装JAVA8 添加ppa sudo add-apt-repository ppa:webupd8team/java sudo apt-get update 安装oracle- ...
- CentOS7下Elastic Stack 5.0日志分析系统搭建
原文链接:http://www.2cto.com/net/201612/572296_3.html 在http://localhost:5601下新建索引页面输入“metricbeat-*”,之后ki ...
- Elastic Stack 8.0 再次创建enrollment token
enrollment token 在第一个 Elasticsearch 启动后的有效时间为30分钟.超过30分钟的时间上述 token 将会无效. enrollment token分两个,一个是kib ...
- Elastic Stack 安装
Elastic Stack 是一套支持数据采集.存储.分析.并可视化全面的分析工具,简称 ELK(Elasticsearch,Logstash,Kibana)的缩写. 安装Elastic Stack ...
- Elastic Stack学习
原文链接 Elastic Stack简称ELK,在本教程你将学习如何快速搭建并运行Elastic Stack. 首先你要安装核心开源产品: Elasticsearch: Kibana: Beats: ...
随机推荐
- C++ 模板和泛型编程(掌握Vector等容器的使用)
1. 泛型 泛型在我的理解里,就是可以泛化到多种基本的数据类型,例如整数.浮点数.字符和布尔类型以及自己定义的结构体.而容器就是提供能够填充任意类型的数据的数据结构.例如vector就很类似于pyth ...
- labview从入门到出家7(进阶篇)--队列的使用
本节简单讲解队列在Labview中的使用,队列你可以认为就是一组先进先出的数据列表,在Labview中常用来缓存和传递数据.用了这么久的队列,个人认为有个方便的地方在于数据传递的把控,不管是局部变量还 ...
- idea反编译jar包,jclasslib Bytecode Viewer
下载 jclasslib Bytecode Viewer https://plugins.jetbrains.com/plugin/9248-jclasslib-bytecode-viewer/ver ...
- 开发实践丨昇腾CANN的推理应用开发体验
摘要:这是关于一次 Ascend 在线实验的记录,主要内容是通过网络模型加载.推理.结果输出的部署全流程展示,从而快速熟悉并掌握 ACL(Ascend Computing Language)基本开发流 ...
- SQL基本概念和SQL通用语法
SQL 1.什么是SQL? Structured Query Language:结构化查询语句 其实就是定义了操作所有关系型数据库的规则.每一种数据库操作的方式存在不一样的地方称为"方言&q ...
- 项目开发中Maven的单向依赖-2022新项目
一.业务场景 工作多年,在真实的项目开发中经常会遇到将一个项目拆分成多个工程的情况,比如将一个真实的项目拆分成controller层,service层, dao层,common公共服务层等等.这样拆分 ...
- Apache DolphinScheduler 1.2.0 使用文档(1/8):架构及名词解释
本文章经授权转载,原文链接: https://blog.csdn.net/MiaoSO/article/details/104770720 目录 1. 架构及名词解释 1.1 DolphinSched ...
- ApacheCon 2020 参会指南
每年一度的 Apache 北美大会因为疫情的原因转到线上来举行了, 这次会议的主题是 ApacheCon@Home, 也就是说借助网络我们可以足不出户就可以参加 Apache 大会了.今年的会议为了针 ...
- Apache DolphinScheduler 使用文档(6/8):任务节点类型与任务参数设置
本文章经授权转载,原文链接: https://blog.csdn.net/MiaoSO/article/details/104770720 目录 6. 任务节点类型和参数设置 6.1 Shell节点 ...
- error setting certificate verify locations
描述 在使用 git clone 克隆 GitHub 或者 Gitee 上的项目时,报如下错误: error setting certificate verify locations: CAfile: ...