hashlib加密、subprocess、logging日志模块
1.hashlib加密模块
1.加密:将明文数据处理成密文数据,让人无法看懂
2.为什么加密:保证数据的安全
3.如何判断数据是否加密:如果是一长串没有规律的字符串(数字、字母、符号)那么数据被加密
4.密文的长短又和讲究:秘闻越长表示使用的加密算法(数据的处理过程)越复杂
5.常见的加密算法:md5、base64、hmac、sha系列
6.加密算法基本操作
import hashlib
# 1.选择加密算法
md5 = hashlib.md5()
# 2.传入明文数据
md5.update(b'123qwe')
"""
加密上传文本时,数字、英文一般用update(b'明文'), 汉语一般用变量名替代,用字符串内置方法update(s.encode('utf8'))
eg:
import hashlib
md5 = hashlib.md5()
md5.update(b'jksdhf12')
res = md5.hexdigest()
print(res) # 54ea00f1c784e860baf0bf6a68810070
s = '哈哈哈呵呵呵'
import hashlib
md5 = hashlib.md5()
md5.update(s.encode('utf8'))
res = md5.hexdigest()
print(res) # e3b3165fdfaf155ad01a9849db7b23d5
"""
# 3.获取加密密文
res = md5.hexdigest()
print(res) # 46f94c8de14fb36680850768ff1b7f2a
2.加密补充说明
1.加密算法不变,如果内容相同,那么结果一定相同
import hashlib
md5 = hashlib.md5()
md5.update(b'hello~world~python')
res = md5.hexdigest()
print(res) # 5045c7522021858df55ff9a27b7cdc46、
import hashlib
md5 = hashlib.md5()
md5.update(b'hello')
md5.update(b'~world')
md5.update(b'~python')
res = md5.hexdigest()
print(res) # 393f30266b770278539d8fd96ff521c0
2.加密之后的那结果是无法反解密的
只能从明文到暗文正向推导,无法从密文到明文反向推导,常见的解密过程其实是提前保存了很多种明文的密文,如果明文过于复杂,无法反推找到明文。
3.加盐处理:在明文里面加一些额外的干扰项
import hashlib
md5 = hashlib.md5()
md5.update('其他的干扰项'.encode('utf8'))
md5.update(b'123321')
res = md5.hexdigest()
print(res) # e092bc9d7aaa814c51958f95237d27bd
““
结合获取用户输入使用:
import hashlib
user_pwd = input('请输入密码:')
md5 = hashlib.md5()
md5.update(user_pwd.encode('utf8'))
res = md5.hexdigest()
print(res)
””
4.动态加盐
干扰项是随机变化的
eg:当前时间、用户名部分...
5.加密实战操作
1.用户密码加密
2.文件安全性校验
3.文件内容一致性校验
4.大文件内容加密
截取部分内容加密即可
3.subprocess模块
模拟操作系统终端 执行命令并获取结果
import subprocess
res = subprocess.Popen(
'asdas', # 操作系统要执行的命令
shell=True, # 固定配置
stdin=subprocess.PIPE, # 输入命令
stdout=subprocess.PIPE, # 输出结果
)
print('正确结果', res.stdout.read().decode('gbk')) # 获取操作系统执行命令之后的正确结果
print('错误结果', res.stderr) # 获取操作系统执行命令之后的错误结果
4.logging日志模块
1.如何理解日志
简单的理解为是记录行为举止的操作(历史史官)
2.日志的级别
五种级别(debug、info、warning、error、critical)
3.日志模块要求
代码无需掌握 但是得会CV并稍作修改
import logging
# logging.debug('debug message')
# logging.info('info message')
# logging.warning('warning message')
# logging.error('error message')
# logging.critical('critical message')
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf8',)
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
level=logging.ERROR
)
logging.error('你好')
5.日志的组成
1.产生日志
2.过滤日志
基本不用 因为在日志产生阶段就可以控制想要的日志内容
3.输出日志
4.日志格式
import logging
# 1.日志的产生(准备原材料) logger对象
logger = logging.getLogger('购物车记录')
# 2.日志的过滤(剔除不良品) filter对象>>>:可以忽略 不用使用
# 3.日志的产出(成品) handler对象
hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 输出到文件中
hd2 = logging.FileHandler('a2.log', encoding='utf-8') # 输出到文件中
hd3 = logging.StreamHandler() # 输出到终端
# 4.日志的格式(包装) format对象
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s: %(message)s',
datefmt='%Y-%m-%d',
)
# 5.给logger对象绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
# 6.给handler绑定formmate对象
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
# 7.设置日志等级
logger.setLevel(10) # debug
# 8.记录日志
logger.debug('写了半天 好累啊 好热啊')
6.日志配置字典
import logging
import logging.config
# 定义日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定义文件路径
logfile_path = 'a3.log'
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '购物车记录': {
# 'handlers': ['default','console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
# logger1 = logging.getLogger('购物车记录')
# logger1.warning('尊敬的VIP客户 晚上好 您又来啦')
# logger1 = logging.getLogger('注册记录')
# logger1.debug('jason注册成功')
logger1 = logging.getLogger('红浪漫顾客消费记录')
logger1.debug('慢男 猛男 骚男')
7.日志实战应用
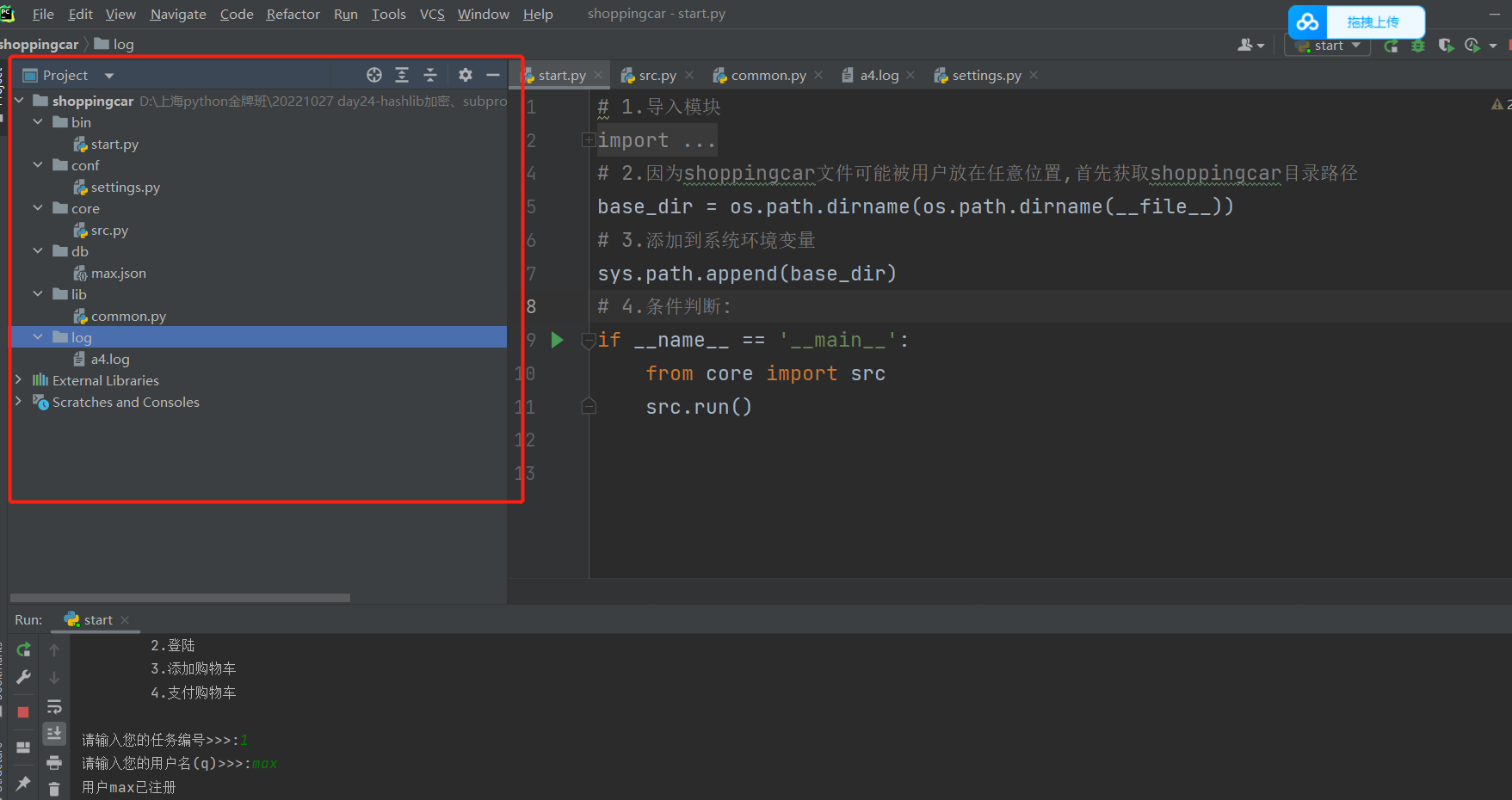
start.py代码:
# 1.导入模块
import os
import sys
# 2.因为ATM文件可能被用户放在任意位置,首先动态获取ATM目录路径
base_dir = os.path.dirname(os.path.dirname(__file__))
# 3.添加到系统环境变量,这样通过ATM根目录就可以找其他文件
sys.path.append(base_dir)
# 4.条件判断:
if __name__ == '__main__':
from ATM.core import src
src.run()
src.py代码:
from ATM.lib import common
def register():
lg = common.get_my_logger('注册') # 括号内是task_id,根据需要修改
lg.info('注册成功') # 括号内是登录信息,根据需要修改
def login():
lg = common.get_my_logger('登陆')
lg.info('登陆成功')
def add_shop_car():
lg = common.get_my_logger('添加购物车')
lg.warning('添加购物车成功')
def pay_shop_car():
lg = common.get_my_logger('结算购物车')
lg.error('结算购物车成功')
func_dict = {
'1': register,
'2': login,
'3': add_shop_car,
'4': pay_shop_car
}
def run():
while True:
print("""
1.注册
2.购物
3.添加购物车
4.结算购物车
""")
choice_num = input('请输入任务编号>>>:').strip()
if choice_num in func_dict:
func_dict.get(choice_num)()
else:
print('请输入正确任务编号')
setting.py:
import os
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
BASE_PATH = os.path.dirname(os.path.dirname(__file__))
DB_DIR = os.path.join(BASE_PATH, 'log')
if not os.path.exists(DB_DIR):
os.mkdir(DB_DIR)
logfile_path = os.path.join(DB_DIR, 'a4.log')
# 自定义文件路径
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '购物车记录': {
# 'handlers': ['default','console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
common.py代码:
import logging
import logging.config
from conf import settings
def get_my_logger(name):
logging.config.dictConfig(settings.LOGGING_DIC)
logger1 = logging.getLogger(name) # 括号内需要填task_id(任务编号)
# logger1.info('用户Jason注册成功') # 括号内改备注,括号前改错误级别
return logger1
文件结构展示:
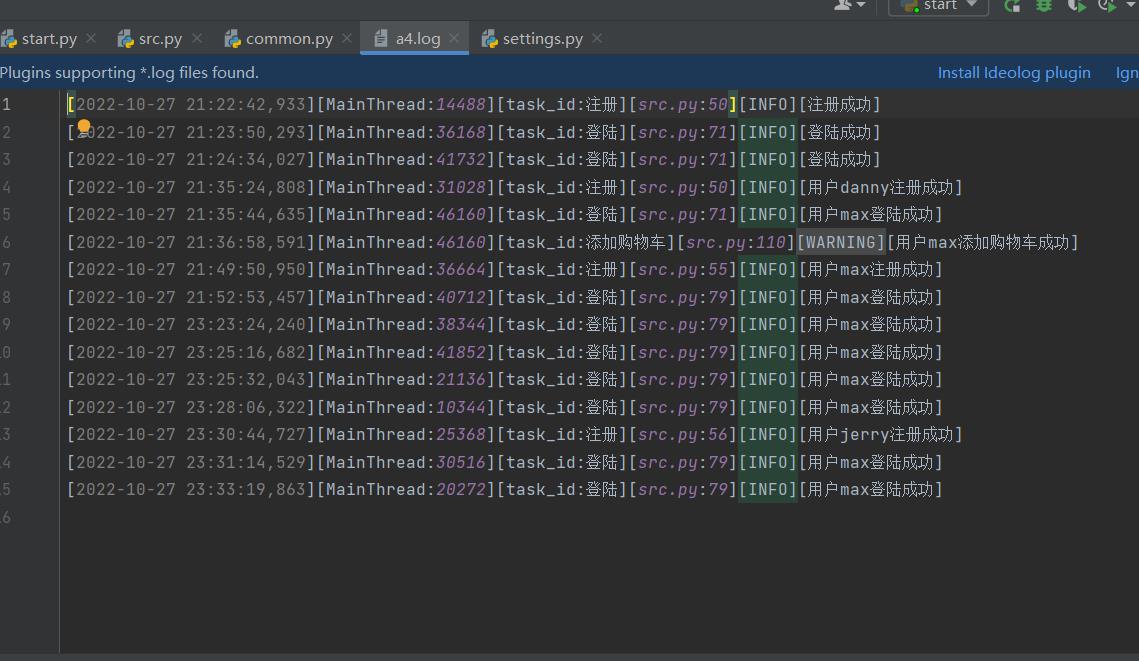
日志展示:
```
日志总结
settings.py中代码:
import os
BASE_DIR = os.path.dirname(os.path.dirname(__file__))
DB_DIR = os.path.join(BASE_DIR, 'db')
if not os.path.exists(DB_DIR):
os.mkdir(DB_DIR)
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' # 其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
# 自定义文件路径
LOG_DIR = os.path.join(BASE_DIR, 'log')
if not os.path.isdir(LOG_DIR):
os.mkdir(LOG_DIR)
LOGFILE_PATH = os.path.join(LOG_DIR, 'ATM.log')
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # 过滤日志
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': LOGFILE_PATH, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
# '购物车记录': {
# 'handlers': ['default','console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
# 'level': 'WARNING',
# 'propagate': True, # 向上(更高level的logger)传递
# }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
},
}
common.py中代码:
import logging
import logging.config
def get_logger(msg):
logging.config.dictConfig(settings.LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger(msg)
return logger1
interface.py中代码:
logger = common.get_logger('银行(可根据interface功能修改)模块')
# 在代码中加(debug可根据等级修改,括号内的内容根据功能自定义):
logger.debug(f'用户{username}查看了自己的账户余额')
hashlib加密、subprocess、logging日志模块的更多相关文章
- hashlib加密模块、logging日志模块
hashlib模块 加密:将明文数据通过一系列算法变成密文数据 目的: 就是为了数据的安全 基本使用 基本使用 import hashlib # 1.先确定算法类型(md5普遍使用) md5 = ha ...
- 约束、自定义异常、hashlib模块、logging日志模块
一.约束(重要***) 1.首先我们来说一下java和c#中的一些知识,学过java的人应该知道,java中除了有类和对象之外,还有接口类型,java规定,接口中不允许在方法内部写代码,只能约束继承它 ...
- 包,logging日志模块,copy深浅拷贝
一 包 package 包就是一个包含了 __init__.py文件的文件夹 包是模块的一种表现形式,包即模块 首次导入包: 先创建一个执行文件的名称空间 1.创建包下面的__init__.py文件的 ...
- logging 日志模块学习
logging 日志模块,用于记录系统在运行过程中的一些关键信息,以便于对系统的运行状况进行跟踪,所以还是灰常重要滴,下面我就来从入门到放弃的系统学习一下日志既可以在屏幕上显示,又可以在文件中体现. ...
- logging日志模块
为什么要做日志: 审计跟踪:但错误发生时,你需要清除知道该如何处理,通过对日志跟踪,你可以获取该错误发生的具体环境,你需要确切知道什么是什么引起该错误,什么对该错误不会造成影响. 跟踪应用的警告和错误 ...
- python 自动化之路 logging日志模块
logging 日志模块 http://python.usyiyi.cn/python_278/library/logging.html 中文官方http://blog.csdn.net/zyz511 ...
- day31 logging 日志模块
# logging 日志模块 ****** # 记录用户行为或者代码执行过程 # print 来回注释比较麻烦的 # logging # 我能够“一键”控制 # 排错的时候需要打印很多细节来帮助我排错 ...
- logging日志模块的使用
logging日志模块的使用 logging模块中有5个日志级别: debug 10 info 20 warning 30 error 40 critical 50 通常使用日志模块,是用字典进行配置 ...
- Python入门之logging日志模块以及多进程日志
本篇文章主要对 python logging 的介绍加深理解.更主要是 讨论在多进程环境下如何使用logging 来输出日志, 如何安全地切分日志文件. 1. logging日志模块介绍 python ...
- Python 中 logging 日志模块在多进程环境下的使用
因为我的个人网站 restran.net 已经启用,博客园的内容已经不再更新.请访问我的个人网站获取这篇文章的最新内容,Python 中 logging 日志模块在多进程环境下的使用 使用 Pytho ...
随机推荐
- Java继承Frame画一个窗口显示图片
将图片显示到窗口上. 在工程目录下准备好图片5.png 运行代码: import javax.imageio.ImageIO; import java.awt.*; import java.awt.e ...
- VMware ESXi 8.0 SLIC 2.6 & macOS Unlocker (Oct 2022 GA)
ESXi 8.0.0 GA (General Availability) 请访问原文 VMware ESXi 8.0 SLIC 2.6 & macOS Unlocker (Oct 2022 G ...
- TreeUtils工具类一行代码实现列表转树【第三版优化】 三级菜单 三级分类 附视频
一.序言 在日常一线开发过程中,总有列表转树的需求,几乎是项目的标配,比方说做多级菜单.多级目录.多级分类等,有没有一种通用且跨项目的解决方式呢?帮助广大技术朋友给业务瘦身,提高开发效率. 本文将基于 ...
- Clickhouse表引擎之MergeTree
1.概述 在Clickhouse中有多种表引擎,不同的表引擎拥有不同的功能,它直接决定了数据如何读写.是否能够并发读写.是否支持索引.数据是否可备份等等.本篇博客笔者将为大家介绍Clickhouse中 ...
- .net如何优雅的使用EFCore
EFCore是微软官方的一款ORM框架,主要是用于实体和数据库对象之间的操作.功能非常强大,在老版本的时候叫做EF,后来.net core问世,EFCore也随之问世. 本文我们将用一个控制台项目Ho ...
- js-day05-对象
为什么要学习对象 没有对象时,保存网站用户信息时不方便,很难区别 对象是什么 1.对象是一种数据类型 2.无序的数据集合 对象有什么特点 1.无序的数据的集合 2.可以详细的描述某个事物' 对象使用 ...
- 【离线数仓】Day01-用户行为数据采集:数仓概念、需求及架构、数据生成及采集、linux命令及其他组件常见知识
一.数据仓库概念 二.项目需求及架构设计 1.需求分析 2.项目框架 3.框架版本选型 服务器选型:云主机 服务器规划 三.数据生成模块 1.数据基本格式 公共字段:所有手机都包含 业务字段:埋点上报 ...
- new的函数如果有return
1 function FnA() { return { a: 1 } } 2 function FnB() { return false } 3 function FnC() { return tru ...
- lv逻辑卷
一.逻辑卷的使用 1.逻辑卷的概念 LVM(逻辑卷管理) 适合于管理大存储设备,并允许用户动态调整文件系统的大小.此外,LVM 的快照功能可以帮助我们快速备份数据.LVM 为我们提供了逻辑概念上的磁盘 ...
- 数据库MySQL(完结)
SQL注入问题 简介 针对SQL注入的攻击行为可描述为通过用户可控参数中注入SQL语法,破坏原有SQL结构,达到编写程序意料之外结果的攻击行为. 其成因可归结为以下两个原理叠加造成: 程序编写者在处理 ...