使用Navicat创建存储过程(顺带插入百万级数据量)
一、建表
DROP TABLE IF EXISTS `test_user`;
CREATE TABLE `test_user` (
`id` bigint(20) PRIMARY key not null AUTO_INCREMENT,
`username` varchar(11) DEFAULT NULL,
`gender` varchar(2) DEFAULT NULL,
`password` varchar(100) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
二、建立函数


将SQL放在下图位置处
while num <= 1000000 do
insert into test_user(username,gender,password) values(num,'保密',PASSWORD(num));
set num=num+1;
end while;
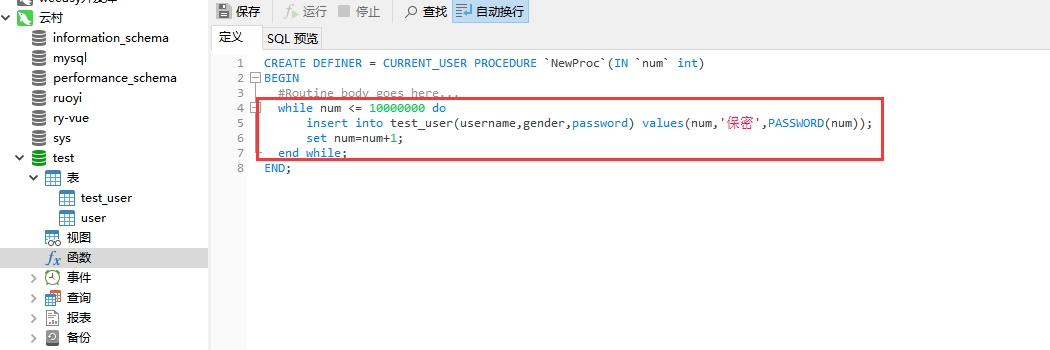
保存SQL,运行。
输入参数1,即从1开始插入一百万条数据。
耗时:27.996s


本文中使用的存储引擎为MyISAM。因为它不支持事务,所以插入数据才会如此之快。
若选择INNODB,插入一百万条数据则需要耗时:1297.971s。
附带数据(可自行测试):

参考:https://blog.csdn.net/qq_33556185/article/details/52192551
使用Navicat创建存储过程(顺带插入百万级数据量)的更多相关文章
- 利用navicat创建存储过程、触发器和使用游标的简单实例
利用navicat创建存储过程.触发器和使用游标的简单实例 标签: navicat存储过程触发器mysql游标 2013-08-03 21:34 15516人阅读 评论(1) 收藏 举报 分类: 数 ...
- navicat创建存储过程的小问题
再简单的东西长时间不用了就会出错,特此即时的记录下来,以便以后参考! 转自:http://blog.csdn.net/winy_lm/article/details/49690633 以下为navic ...
- 存储过程 ----- navicat 创建存储过程
以下为navicat 创建存储过程步骤图解: 1. 2. 3. 4. 在存储过程正文中是输入一行语句测试用,点击保存 5.输入存储过程名称,点击确定 6.到这来那么问题来了,会提示错误 7.切记存储过 ...
- navicat创建存储过程、触发器和使用游标
创建存储过程和触发器 1.建表 首先先建两张表(users表和number表),具体设计如下图: 2.存储过程 写一个存储过程,往users表中插入数据,创建过程如下: 代码如下: BEGIN #Ro ...
- navicat创建存储过程时报错1064
1.这是创建的存储过程 2.一保存就会出错 3.后来上网查了一下是存储过程的参数没有设定长度导致的,我们在Navicat中创建存储过程时参数的长度需要自己动手去添加的否则就会包这种错误. 添加上参数的 ...
- 用NaviCat创建存储过程批量添加测试数据
打开navicat连接上数据库,然后打开左上角函数,新建一个函数. BEGIN DECLARE i int; --声明变量 DECLARE groupid int; set i=LAST_INSERT ...
- navicat创建存储过程报错
搞了半天这个恶心的报错,最后发现竟然是存储过程的一个varchar类型的参数没给长度,如varchar(64)长度必须指定不然就会报错: mark一记
- 十万级百万级数据量的Excel文件导入并写入数据库
一.需求分析 最近接到一个需求,导入十万级,甚至可能百万数据量的记录了车辆黑名单的Excel文件,借此机会分析下编码过程; 首先将这个需求拆解,发现有三个比较复杂的问题: 问题一:Excel文件导入后 ...
- Java实现Sunday百万级数据量的字符串快速匹配算法
背景 在平时的项目中,几乎都会用到比较两个字符串时候相等的问题,通常是用==或者equals()进行,这是在数据相对比较少的情况下是没问题的,当数据库中的数据达到几十万甚至是上百万千万的数 ...
随机推荐
- 比 Navicat 还要好用、功能更强大的工具!
DBeaver 是一个基于 Java 开发,免费开源的通用数据库管理和开发工具,使用非常友好的 ASL 协议.可以通过官方网站或者 Github 进行下载. 由于 DBeaver 基于 Java 开发 ...
- 9.1 Linux存储结构和文件系统
1. 存储结构 Linux系统中的一切文件都是从"根"目录(/)开始的,并按照文件系统层次标准(FHS)采用倒树状结构来存放文件,以及定义了常见目录的用途. 目录名称 应放置文件的 ...
- JVM垃圾回收篇
点赞再看,养成习惯,微信搜索「小大白日志」关注这个搬砖人. 文章不定期同步公众号,还有各种一线大厂面试原题.我的学习系列笔记. 基础概念 GC=jvm垃圾回收,垃圾回收机制是由垃圾回收器Garbage ...
- spring boot的配置文件
1.SpringBootApplication是标志启动类,启动后可以把这个类所在的包资源发布到服务器,不用再启动tomcat 2.利用spring boot工程可以和以前一样直接在Controlll ...
- 微信小程序订阅消息
概述 消息能力是小程序能力中的重要组成,我们为开发者提供了订阅消息能力,以便实现服务的闭环和更优的体验. 订阅消息推送位置:服务通知 订阅消息下发条件:用户自主订阅 订阅消息卡片跳转能力:点击查看详情 ...
- Azure Service Fabric 踩坑日志
近期项目上面用到了Azure Service Fabric这个服务,它是用来做微服务架构的,由于这套代码和架构都是以前同学留下来的,缺少文档,项目组在折腾时也曾遇到几个问题,这里整理如下,以供参考. ...
- Neo4j数据和Cypher查询语法笔记
Cypher数据结构 Cypher的数据结构: 属性类型, 复合类型和结构类型 属性类型 属性类型 Integer Float String: 'Hello', "World" B ...
- Docker系列教程05-Docker数据卷(Data Volume)学习
引言 在Docker中,容器的数据读写默认发生在容器的存储层,当容器被删除时其上的数据将会丢失.要想实现数据的持久化,需要将数据从宿主机挂载到容器中.目前Docker提供了三种方式将数据从宿主机挂载到 ...
- 容器内的Linux诊断工具0x.tools
原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,转载请保留出处. 简介 Linux上有大量的问题诊断工具,如perf.bcc等,但这些诊断工具,虽然功能强大,但却需要很高的权限才可以使用 ...
- redis 基础1
1.redis是什么? redis是非关系型数据库key-value数据库,开源免费.是当下NoSQL技术之一 2.redis能干吗? (1)内存存储,可以持久化,redis存储在内存中,内存的话是断 ...