使用Python批量爬取美女图片
运行截图
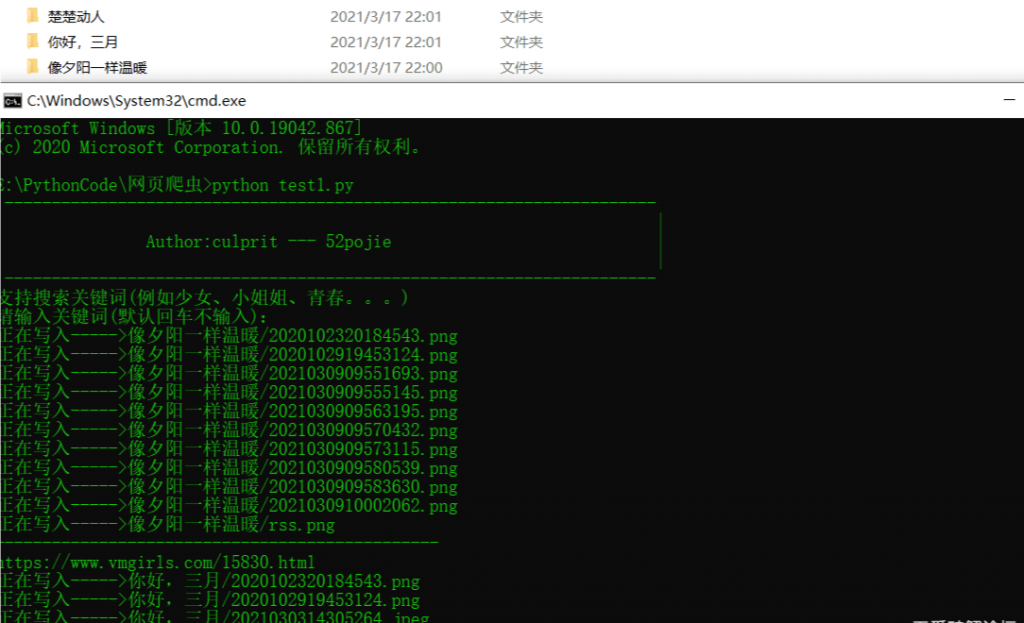
实列代码:
from bs4 import BeautifulSoup
import requests,re,os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
def Get_Url(url):
response = requests.get(url, headers=headers).text
soup = BeautifulSoup(response,'html.parser')
for data in soup.find_all('a',class_='list-title text-md h-2x'):
url_data = data.get('href')
urls = "https://www.vmgirls.com/" + str(url_data)
Down_Image(urls)
print('-----------------------------------------------')
print(urls)
def Down_Image(url):
response = requests.get(url, headers=headers).text
soup = BeautifulSoup(response, 'html.parser')
image_url = soup.find_all('img')
for data in image_url:
image_type = data.get('src').split('.')[-1]
if image_type == 'jpg' or image_type == 'jpeg' or image_type == 'png':
url_data = data.get('src')
# print(url_data)
dir_name = soup.find(class_='post-title h1').string
if not os.path.exists(dir_name):
os.mkdir(dir_name)
# print(dir_name)
image = requests.get("https:" + str(url_data), headers=headers).content
file_name = url_data.split('/')[-1]
# print(file_name)
with open(dir_name + '/' + file_name, 'wb') as f:
f.write(image)
print('正在写入----->' + dir_name + '/' + file_name)
if __name__ == '__main__':
print(' ---------------------------------------------------------------------')
print('| |')
print('| Author:culprit --- iamdd |')
print('| |')
print(' ---------------------------------------------------------------------')
print('支持搜索关键词(例如少女、小姐姐、青春。。。)')
key = input('请输入关键词(默认回车不输入):')
if key == '':
url = "https://www.vmgirls.com/"
else:
url = "https://www.vmgirls.com/?s=" + key
Get_Url(url)使用Python批量爬取美女图片的更多相关文章
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- Scrapy爬取美女图片第三集 代理ip(上) (原创)
首先说一声,让大家久等了.本来打算那天进行更新的,可是一细想,也只有我这样的单身狗还在做科研,大家可能没心思看更新的文章,所以就拖到了今天.不过忙了521,522这一天半,我把数据库也添加进来了,修复 ...
- Scrapy爬取美女图片第四集 突破反爬虫(上)
本周又和大家见面了,首先说一下我最近正在做和将要做的一些事情.(我的新书<Python爬虫开发与项目实战>出版了,大家可以看一下样章) 技术方面的事情:本次端午假期没有休息,正在使用fl ...
- Scrapy爬取美女图片续集 (原创)
上一篇咱们讲解了Scrapy的工作机制和如何使用Scrapy爬取美女图片,而今天接着讲解Scrapy爬取美女图片,不过采取了不同的方式和代码实现,对Scrapy的功能进行更深入的运用.(我的新书< ...
- python 3 爬取百度图片
python 3 爬取百度图片 学习了:https://blog.csdn.net/X_JS612/article/details/78149627
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
- android高仿抖音、点餐界面、天气项目、自定义view指示、爬取美女图片等源码
Android精选源码 一个爬取美女图片的app Android高仿抖音 android一个可以上拉下滑的Ui效果 android用shape方式实现样式源码 一款Android上的新浪微博第三方轻量 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- 从0实现python批量爬取p站插画
一.本文编写缘由 很久没有写过爬虫,已经忘得差不多了.以爬取p站图片为着手点,进行爬虫复习与实践. 欢迎学习Python的小伙伴可以加我扣群86七06七945,大家一起学习讨论 二.获取网页源码 爬取 ...
随机推荐
- Linux安装netstat命令
Linux安装netstat命令 1.查找netstat命令所属的依赖包 [root@localhost ~]# yum provides netstat netstat命令的安装包为net-tool ...
- synchronized下的 i+=2 和 i++ i++执行结果居然不一样
起因 逛[博客园-博问]时发现了一段有意思的问题: 问题链接:https://q.cnblogs.com/q/140032/ 这段代码是这样的: import java.util.concurrent ...
- Node.js精进(1)——模块化
模块化是一种将软件功能抽离成独立.可交互的软件设计技术,能促进大型应用程序和系统的构建. Node.js内置了两种模块系统,分别是默认的CommonJS模块和浏览器所支持的ECMAScript模块. ...
- npm切换到国内华为云的镜像
npm下载包很慢?不能忍,切换到国内华为云的镜像吧. npm config set registry https://repo.huaweicloud.com/repository/npm/ npm ...
- (数据科学学习手札139)geopandas 0.11版本重要新特性一览
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,就在几天前,geopandas ...
- Kubebuilder简介与架构
什么是Kubebuilder Kubebuilder是一个用Go原因构建Kubernetes APIs的框架,通过使用KubeBuilder,用户可以遵循一套简单的编程框架,使用CRD构建API.Co ...
- C#《原CSharp》第三回 万文疑谋生思绪 璃月港口见清玉
第三回 万文疑谋生思绪 璃月港口见清玉 ===================================================================== 云溪愣了下,在他的认 ...
- STC8H开发(十三): I2C驱动DS3231高精度实时时钟芯片
目录 STC8H开发(一): 在Keil5中配置和使用FwLib_STC8封装库(图文详解) STC8H开发(二): 在Linux VSCode中配置和使用FwLib_STC8封装库(图文详解) ST ...
- ubuntu 20.04 安装 vim8.2
由于ubuntu 20.04自带的vim版本比较老了,有些新装的插件适配不上,所以需要安装最新版本的vim.在网上找了很久也没有比较官方的安装教程所以记录一下. 安装依赖库 sudo apt inst ...
- windows10 使用elasticsearch和kibana
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.6.2-windows-x86_64.zip https:// ...