python+selenium+opencv验证滑块
我们在使用selenium爬虫的时候在登录时经常会遇到滑块验证码问题,导致登录受阻,正所谓万事开头难。
登录就登录不进去更别提往后的操作的。今天以登录京东后台来演示下如何破解滑块。
一.登录
首先我们先进入XXXX后台登录页面,输入用户名和密码进入滑块页面
import time from selenium import webdriver
from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.implicitly_wait(10) # 设置隐形等待
driver.maximize_window()
driver.get("https://passport.xxxx.com/new/login?")
driver.find_element(by=By.XPATH, value="//a[contains(text(),'账户登录')]").click()
driver.find_element(by=By.ID, value="loginname").send_keys("1935762273")
driver.find_element(by=By.ID, value="nloginpwd").send_keys("13833979764")
driver.find_element(by=By.ID, value="loginsubmit").click()
time.sleep(2)
二.获取缺口图和滑块保存到本地
1)首先获取滑块图

我们可以发现滑块图是用base64加密过的,因此在获取img_url时需要base64解密才能将图片保存到本地
img_list = driver.find_elements(by=By.TAG_NAME, value="img")
hk_img = img_list[4].get_attribute("src") # 获取定位滑块的src
hk_img = hk_img[22:] # 截取所需要的url
with open("./img/hk.png", mode="wb") as f:
f.write(base64.b64decode(hk_img)) # base64解密后保存到本地img下
2)获取缺口图

缺口图的获取和滑块方法是一样的,这里直接贴代码了。
qk_img = img_list[3].get_attribute("src") # 获取定位缺口的src
qk_img = qk_img[22:] # 截取所需要的url
with open("./img/qk.png", mode="wb") as f:
f.write(base64.b64decode(qk_img)) # base64解密后保存到本地img下
driver.quit()
三.opencv处理
将缺口图和滑块图保存到本地后工作量就已经完成一半了,离胜利还有半步之遥,接下来就是用opencv处
理图片计算出偏移量
1)安装opencv
pip install opencv-python
2)opencv处理图片计算偏移量
灰度化处理滑块/缺口图,这一步骤需要导包 :import cv2.cv2 as cv2
hk_img_01 = cv2.imread("./img/hk.png", 0) # 灰度化
qk_img_01 = cv2.imread("./img/qk.png", 0)
获取滑块在缺口图中匹配的位置
late = cv2.matchTemplate(qk_img_01, hk_img_01, cv2.TM_CCOEFF_NORMED)
计算偏移量
loc = cv2.minMaxLoc(late)
我们打印loc可以发现最终给出来的值是四个,我们直接取最大的那个即可(71)

我们得到的71这个数字其实还不是最终的偏移量,还需要获取到滑块图Rendered size和Intrinsic size
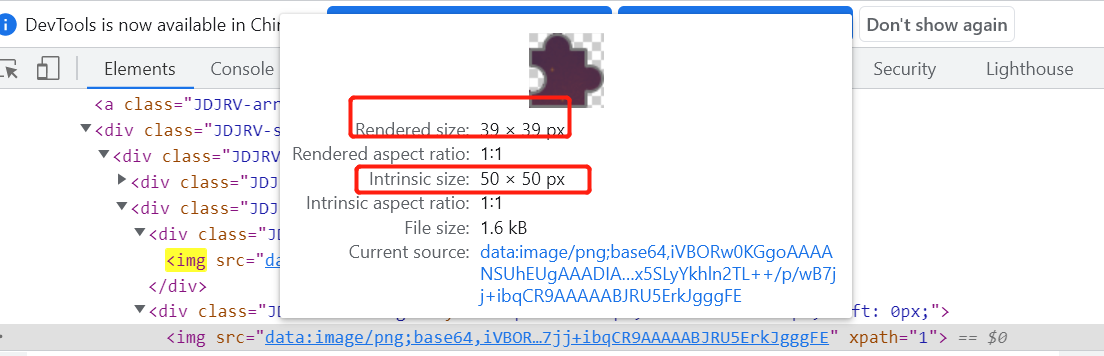
拿获取的loc*Rendered/Intrinsic得到的才是最后要偏移的距离
y = int(loc[2][0] * 39 / 50)
四.模拟鼠标事件拖拽滑块
这一步超级简单,就直接copy代码了
action = ActionChains(driver)
action.click_and_hold(img_list[4])
action.move_by_offset(x, 0)
action.release().perform()
这里需要注意的是万事都不是绝对的,计算偏移量也是一样,不能达到100%成功,但也有个七八十,所以
模拟鼠标拖拽时加个while循环即可,这里就不做过多演示了。
五.破解反爬机制
当你执行到第四步的时候你会发现有时即使滑块和缺口对应上了,但还是会提示验证失败,这是因为京东代码含反
爬机制,检验出你使用的是selenium,所以给你干掉了。下面就来介绍下小编的反反爬之苦逼之路。
1)改变请求头设置无痕模式
当遇到上面的情况后第一时间想到的就是改变请求头,设置无痕模式,于是抱着试试的心态我写了如下代码。
option = webdriver.ChromeOptions()
option.add_argument("--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/104.0.0.0 Safari/537.36")
option.add_experimental_option("excludeSwitches", ["enable-automation"])
driver = webdriver.Chrome(options=option)
结果可想而知,苍天助error不助succeed。
2)模拟手动拖拽轨迹
一条路走不通那么就走第二条,在尝试多次后可以发现,selenium打开页面到验证滑块的时,这个时候手动去拖拽
滑块,最后可以拼接成功,那么就有一种可能,反爬机制不是一开始就检测出来的,而是在模拟鼠标拖拽时检测出
来的。那么我们只需要模拟手动推拽轨迹使其更像人为操作即可。下面是封装好的方法(网上copy的,如有侵权,
请告知删除)
def get_track(distance):
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.2
# 初速度
v = 1
while current < distance:
if current < mid:
# 加速度为2
a = 4
else:
# 加速度为-2
a = -3
v0 = v
# 当前速度
v = v0 + a * t
# 移动距离
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track
这个方法如果高中物理学的不好的人就不要了解了,直接拿来用即可。下面贴下最后代码
action = ActionChains(driver)
tracks = get_track(x)
action.click_and_hold(img_list[4]).perform()
for i in tracks:
action.move_by_offset(i, 0).perform()
action.move_by_offset(3, 0).perform()
action.move_by_offset(-3, 0).perform()
action.release().perform()
time.sleep(3)
3)修改window.navigator.webdrive
正常来说第二种方法就可以跳过检测验证成功,那么在了解一种也不错呢,正所谓艺多不压身。
我们在手动进入登录页面时window.navigator.webdrive是为undefined的。但用selenium打开登录
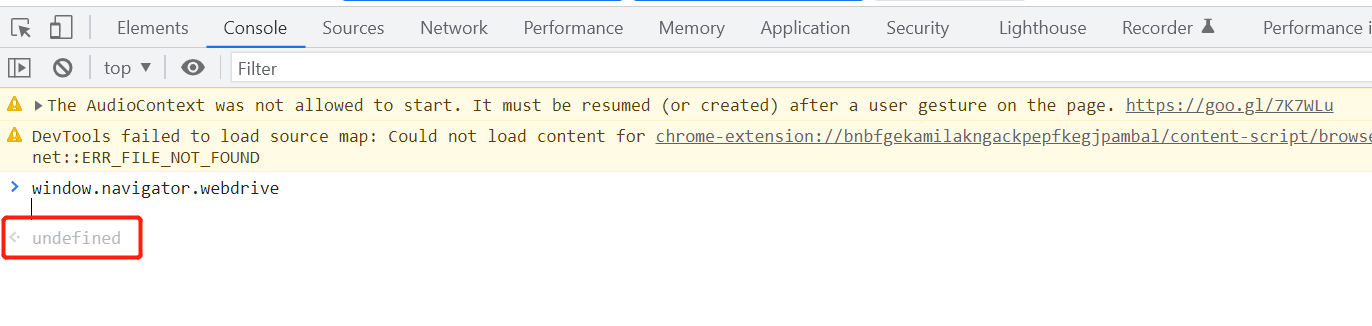
页面时window.navigator.webdrive的值为true,所以在进入页面时我们需要修改该值,最简单的方法
加入一行代码即可。
option.add_argument("--disable-blink-features=AutomationControlled")
4)禁用Chrome浏览器的自动化扩展
option.add_experimental_option('useAutomationExtension', False)
六.验证结果
很抱歉的说句未能成功,原因是什么呢,其实通过模拟手动拖拽轨迹是可以验证成功的,这个亲测有效,
但不知为何xxxx网站又做了什么骚操作,目前无法验证成功,这个会后续研究,有好的方法再更新。
七.源码
import time from selenium import webdriver
from selenium.webdriver.common.by import By
import base64
import cv2.cv2 as cv2
from selenium.webdriver import ActionChains option = webdriver.ChromeOptions()
# option.add_argument("--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
# "Chrome/104.0.0.0 Safari/537.36")
# option.add_experimental_option("excludeSwitches", ["enable-automation"])
# option.add_argument("--disable-blink-features=AutomationControlled")
option.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=option) driver.implicitly_wait(10) # 设置隐形等待
driver.maximize_window()
driver.get("https://passport.xxxx.com/new/login?")
driver.find_element(by=By.XPATH, value="//a[contains(text(),'账户登录')]").click()
driver.find_element(by=By.ID, value="loginname").send_keys("15161581519")
driver.find_element(by=By.ID, value="nloginpwd").send_keys("13633979764")
driver.find_element(by=By.ID, value="loginsubmit").click()
time.sleep(2) def get_track(distance):
# 移动轨迹
track = []
# 当前位移
current = 0
# 减速阈值
mid = distance * 4 / 5
# 计算间隔
t = 0.2
# 初速度
v = 1
while current < distance:
if current < mid:
# 加速度为2
a = 4
else:
# 加速度为-2
a = -3
v0 = v
# 当前速度
v = v0 + a * t
# 移动距离
move = v0 * t + 1 / 2 * a * t * t
# 当前位移
current += move
# 加入轨迹
track.append(round(move))
return track while True:
img_list = driver.find_elements(by=By.TAG_NAME, value="img")
hk_img = img_list[4].get_attribute("src") # 获取定位滑块的src
hk_img = hk_img[22:] # 截取所需要的url
with open("./img/hk.png", mode="wb") as f:
f.write(base64.b64decode(hk_img)) # base64解密后保存到本地img下 qk_img = img_list[3].get_attribute("src") # 获取定位缺口的src
qk_img = qk_img[22:] # 截取所需要的url
with open("./img/qk.png", mode="wb") as f:
f.write(base64.b64decode(qk_img)) # base64解密后保存到本地img下 hk_img_01 = cv2.imread("./img/hk.png", 0) # 灰度化
qk_img_01 = cv2.imread("./img/qk.png", 0)
late = cv2.matchTemplate(qk_img_01, hk_img_01, cv2.TM_CCOEFF_NORMED) # 获取滑块在缺口图的位置
loc = cv2.minMaxLoc(late) # 获取位置
x = int(loc[2][0] * 39 / 50)
print(x)
action = ActionChains(driver)
tracks = get_track(x)
action.click_and_hold(img_list[4]).perform()
for i in tracks:
action.move_by_offset(i, 0).perform()
action.move_by_offset(3, 0).perform()
action.move_by_offset(-3, 0).perform()
action.release().perform()
time.sleep(3)
文章来源:https://www.cnblogs.com/lihongtaoya/ ,请勿转载
部分参考:https://blog.csdn.net/m0_59874815/article/details/121195481
python+selenium+opencv验证滑块的更多相关文章
- 使用Python + Selenium破解滑块验证码
在前面一篇博客<使用 Python + Selenium 打造浏览器爬虫>中,我介绍了 Selenium 的基本用法和爬虫开发过程中经常使用的一些小技巧,利用这些写出一个浏览器爬虫已经完全 ...
- python+selenium破解极验验证登录
1.前言: 目前很多网站会在正常的账号密码认证之外加一些验证码,以此来明确区分人/机行为,最典型的就是极验滑动验证.(如下图) 这里我们以简单实例说明如何实现自动校验类似验证. 2.步骤: 1)点击验 ...
- 学霸笔记系列 - Python Selenium项目实战(一)—— 怎么去验证一个按钮是启用的(可点击)?
Q: 使用 Python Selenium WebDriver 怎么去验证一个按钮是启用的(可点击)? A:Selenium WebDriver API 里面给出了解决方法is_enabled() 使 ...
- Python 阿里云盾滑块验证
本文仅供学习交流使用,如侵立删! 记一次阿里云盾滑块验证分析并通过 操作环境 win10 . mac Python3.9 selenium.pyautogui 分析 最近在做中国庭审公开网数据分析的时 ...
- python+selenium+unnitest写一个完整的登陆的验证
import unittest from selenium import webdriver from time import sleep class lonInTest (unittest.Test ...
- 在windows 8.1 64位配置python和opencv
之前在linux下安装python和opencv及相关的库,都可以直接命令行操作.最近需要在windows下配置一下,查了一些资料,发现网上有很多关于python和opencv的配置,但由于不同版本问 ...
- Python Selenium设计模式-POM
前言 本文就python selenium自动化测试实践中所需要的POM设计模式进行分享,以便大家在实践中对POM的特点.应用场景和核心思想有一定的理解和掌握. 为什么要用POM 基于python s ...
- Python selenium自动化网页抓取器
(开开心心每一天~ ---虫瘾师) 直接入正题---Python selenium自动控制浏览器对网页的数据进行抓取,其中包含按钮点击.跳转页面.搜索框的输入.页面的价值数据存储.mongodb自动i ...
- Python+Selenium基础篇之1-环境搭建
Python + Selenium 自动化环境搭建过程 1. 所需组建 1.1 Selenium for python 1.2 Python 1.3 Notepad++ 作为刚初学者,这里不建议使用P ...
- WEB自动化(Python+selenium)的API
在做Web自动化过程中,汇总了Python+selenium的API相关方法,给公司里的同事做了第二次培训,分享给大家 ...
随机推荐
- Cesium球心坐标与本地坐标系经纬转换的数学原理—矩阵变换
之前整理过:<透析矩阵,由浅入深娓娓道来-高数-线性代数-矩阵>.<三维旋转笔记:欧拉角/四元数/旋转矩阵/轴角-记忆点整理>,这次转载 FuckGIS的<Cesium之 ...
- 用火山引擎DataTester,这家企业开始了“数据驱动增长”
年末购物季已至,近些年来,预售抵扣.平台满减.品类专享券.大额补贴--动辄四五种计算方法叠加的大促活动,让不少消费者"懵"感十足.同一样商品,到底谁家卖的最便宜?比价平台应声发展而 ...
- Solon Aop 特色开发(2)注入或手动获取Bean
Solon,更小.更快.更自由!本系列专门介绍Solon Aop方面的特色: <Solon Aop 特色开发(1)注入或手动获取配置> <Solon Aop 特色开发(2)注入或手动 ...
- CJ88 DUMP The ASSERT condition was violated
一.CJ88运行某个项目时DUMP,其他项目正常 The ASSERT condition was violated. 源代码位置为交易货币为空导致DUMP 经过长时间的源码调试,也只定位在查询语句这 ...
- Leaflet 百度、高德地图瓦片坐标 偏移 纠偏
实现地图瓦片纠偏的leaflet.mapCorrection.js代码: //坐标转换 L.CoordConvertor = function () { /**百度转84*/ this.bd09_To ...
- OS | 进程和线程基础知识全家桶图文详解✨
前言 先来看看一则小故事 我们写好的一行行代码,为了让其工作起来,我们还得把它送进城(进程)里,那既然进了城里,那肯定不能胡作非为了. 城里人有城里人的规矩,城中有个专门管辖你们的城管(操作系统),人 ...
- JSP | 指令详解以及实例
原作者为 RioTian@cnblogs, 本作品采用 CC 4.0 BY 进行许可,转载请注明出处. 本篇学习自:C语言中文网,部分内容转载仅供学习使用. 前文 JSP 中有一个关键的知识点:指令; ...
- 国内pip源提示“not a trusted or secure host”解决方案
大家应该都知道怎么添加国内pip源(主要是豆瓣和阿里云),~/.pip/pip.conf文件配置大概如下(下面注释掉了豆瓣源): [global] # index-url = http://pypi. ...
- AtCoder ABC 165 D - Floor Function (Good, 手动模拟推出公式)
题目链接:Here 题意: 给出正整数 \(A,B,N (1\le A\le 1e6,1\le B,N\le1e12)\) ,对于 \(x\in [0,N]\) 求出 \(\left\lfloor\f ...
- 【每日一题】28. 模拟战役 (模拟 + DFS/BFS/并查集)
补题链接:Here 本题属于一道模拟题 虽然这题介绍一大堆,总结起来就是几句话,给出地图n列,前4行是a的地盘,后四行是b的地盘,每个人地盘上面有星号代表大炮. 大炮会 3 * 3的波及周围,会一直传 ...