[oeasy]python0128_unicode_字符集_character_set_八卦_星座
- 中国的简体和繁体汉字
- 字符数量都超级大
- 彼此还认对方为乱码
- 如果有一种编码所有的字符都能编进去就好了
- 中日韩(CJK)
- 欧洲拼音
- 梵文
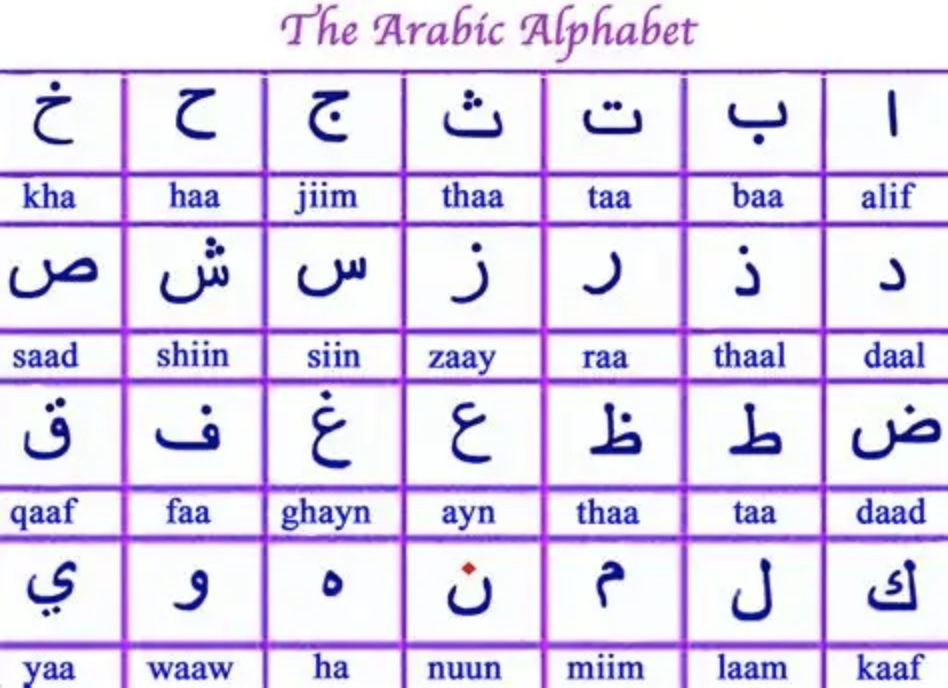
- 阿拉伯文
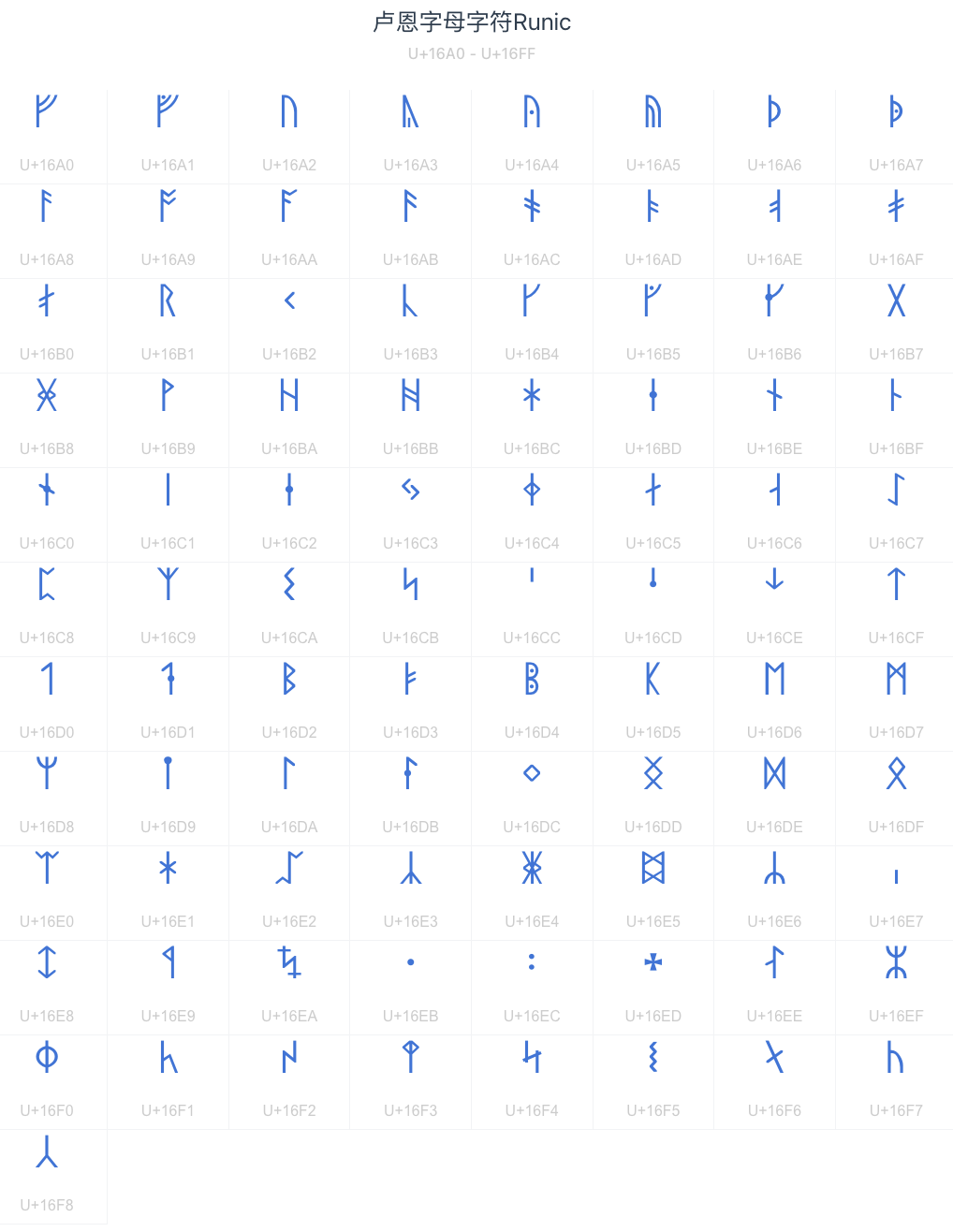
- 卢恩字符
- 等等等都包括进去
- 能有么?
- 计算机中只有 0 和 1
- 并且是存储在字节里的
- 原来只能表示和处理数字
- 字符无法处理
- 后来某些二进制数固定下来代表某个字符
- 形成了字符集
- 从博多码(5bits)到 BCDIC(6bits)
- 再到 EBCDIC码(8bits) 最后统一于 ascii

- 但是 各国家和地区
- 都有 自己的文字
- 这一领域 没有 统一的标准
- 所以每个国家和地区
- 都制定自己的编码标准
- 想要同时显示 法语字符和西里尔字符 是不可能的
- 同样字节状态 在不同编码格式里 代表不同的字符
- 都认为对方是乱码
- 彼此不兼容
- 编码方式有上百种之多
- 互为乱码
- 无法解决的问题背后 可能是机会
- 1980 年代
- Xerox(施乐公司) 在 开始尝试一种编码
- 能融合多语言
- Xerox 字符集包括
- 拉丁
- 阿拉伯
- 希伯来
- 希腊
- 西里尔
- 中日韩字符

- 这个字符集 1988 年进化为 unicode
- uni的意思是一
- uni 来自于
- unique
- unified
- universal
- unicorn
- university
- uniform
- unit
- union

- uni-开头的单词都有这个特点
- universe
- uni
- 一
- verse
- 旋转
- universe
- 绕着一个东西转的
- 从一转化而来的
- 一生二 二生三 三生万物

- 后来日语
- 将universe翻译成宇宙
- 宇宙一词 中文以前就有
- 上下四方曰宇
- 古往今来曰宙
- 这个词头计算机领域也有很多很牛的单词
- unit、unix、unity、unicode
- 这名字得一了啊
- 少则得,多则惑,是以圣人抱一为天下式
- 天得一以清,地得一以宁,神得一以灵,谷得一以盈,万物得一以生,侯王得一而以为正
- 这个版本叫做 unicode88
- 是 16 位的 unicode
- 1989 年
- Unicode 这个工作组来了一些从大厂来的人
- 微软和 sun 都来了
- 1991/1/3 日
- Unicode 委员会在加州成立
- 1991 年 8 月
- unicode 第一卷发布
- 1992 年 6 月
- 第 2 卷发布
- 这里面包含了汉语字符
- unicode 委员会 形成
- Adobe, Apple, Facebook, Google, IBM, Microsoft, Netflix 和 SAP SE 等公司的工程师加入

- 字符的全球标准化开始了
- ascii 还是牢牢占据着 0-127 这最关键的位置
- 紧挨着 ascii 的字符的就是 Latin-1
- 由 iso-8859-1 西欧、北欧字符集进化而来

- 这其实也 标识出unicode的 编码排序规则
- 以书写系统为单位
- 分类和收录
- 比如卢恩字符
- 再去捋一捋
- 拉丁字符进化过程吧
|
发音
|
词义
|
埃及圣书体
|
楔形写法
|
希腊字符
|
拉丁字符
|
|---|---|---|---|---|---|
|
alpha
|
牛
|
|
|
Αα
|
Aa
|
|
beta
|
房子
|
|
|
Ββ
|
Bb
|
|
gīml
|
棍子
|
|
|
Γγ
|
Cc,Gg
|
|
dālet
|
门或者鱼
|
|
|
Δδ
|
Dd
|
- 去看看他们的序号
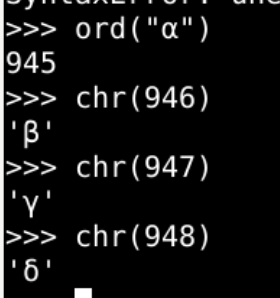
- 希腊字符比较好找
- 序号较小
- 不过希腊字符之前只有大写字母
- 小写字母怎么来的呢?

- 手写画风固定下来后
- 又被印刷术 再次固定

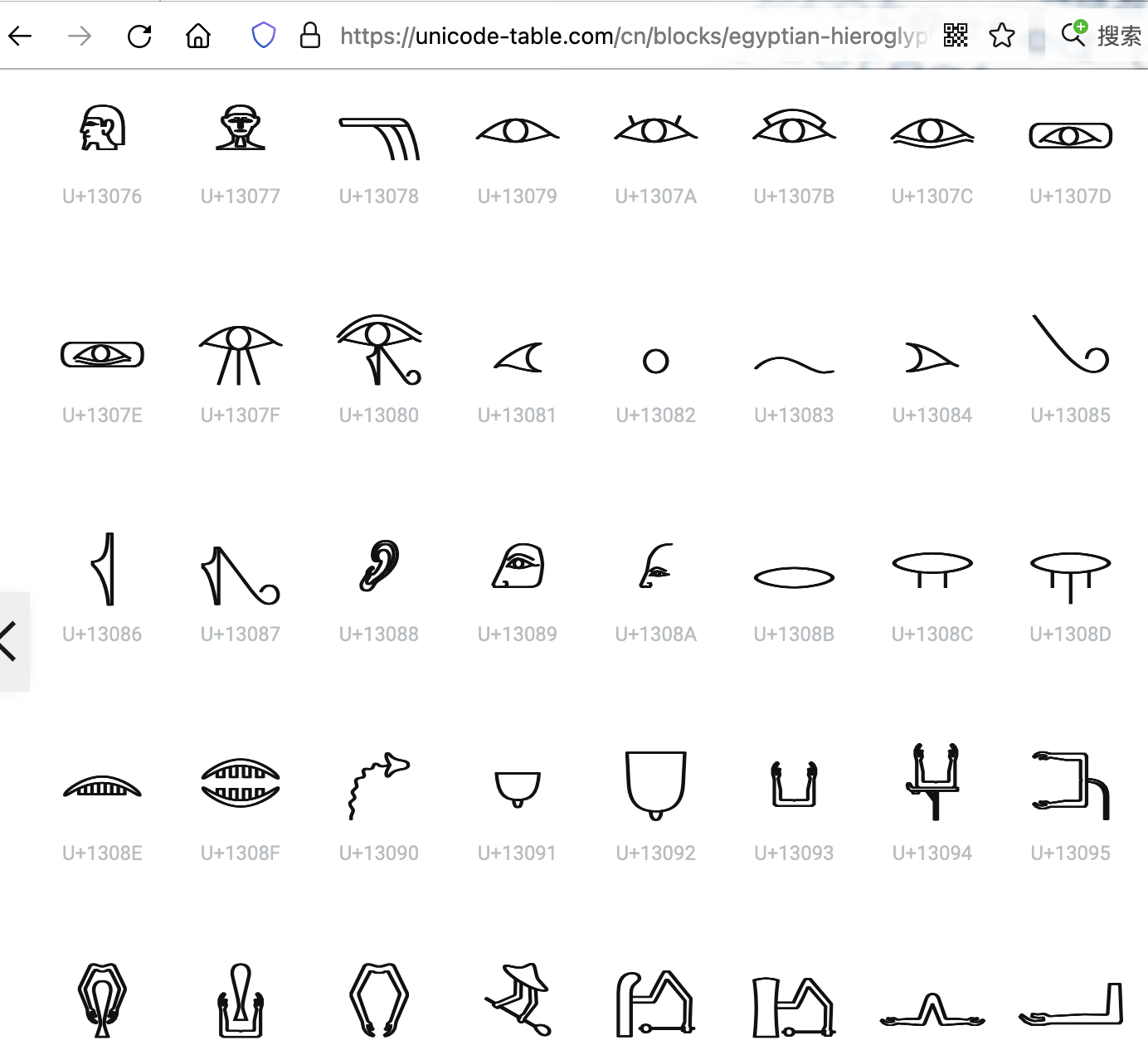
- 能找到埃及文字的序号吗?
- unicode 确实给埃及文字排了序号
- 但是序号很大
- 而且目前终端没有字型支持
- 字型文件 实现难度不小
- 实际需求 也不确定
- 同为 拼音文字的不同书写系统
- 可能会用到 长得一样的字符
- 会是一个序号吗?
- 英文字母、拉丁字母、西里尔文字母
- 都源自希腊文字母 Omicron
- 不同的书写系统
- 可能会长相一样的字母
- 但对应着不同的序号

- 虽然字形一模一样
- 但是属于三个书写系统
- 希腊文字母
- 英文字母
- 西里尔字母
- 所以 有不同的序号
- 每个版本都会有些变化
- 整个编码区域分成若干个 blocks
- 新版本对于这些 blocks 里面的字符有所增加

- 除了字符之外还有很多符号
- 比如十二个星座
- 集装箱 标准化一旦开始
- 就会 反过来 约束火车轮船飞机
- 你要想 加入这个交流的行列
- 必须先了解相应的接口
- 从遵守现有的规则开始
- 新编码unicode的时代来了
- 他会把一切字符吸收进去

- 同一个文档
- 可以既有中文
- 又有日文
- 还有韩文
- 一切字符都能正常显示
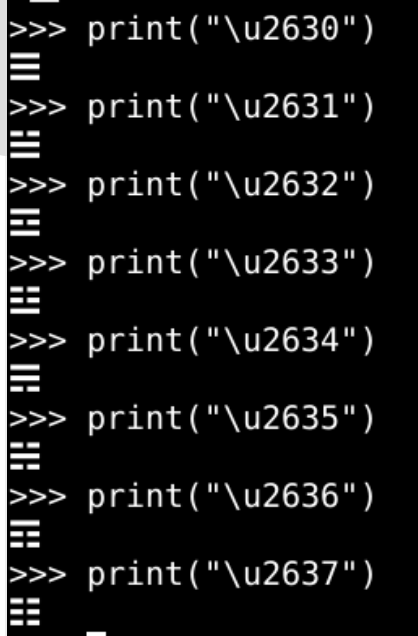
- 易有太极
- ️☯

- 是生两仪
- ⚊ 陽 (U+268A) ⚋ 陰 (U+268B)
- 两仪生四象
- ⚌(太陽,U+268C)、⚍(少陰,U+268D)、⚎(少陽,U+268E)、⚏(太陰,U+268F)

- 四象生八卦
- ☰ ☱ ☲ ☳ ☴ ☵ ☶ ☷
- 如果把
- ⚊ 陽 (U+268A)当做1
- ⚋ 陰 (U+268B)当做0
- 顺序是逆序(递减)
- 从外而内
- 天
- 泽
- 水
- 雷
- 风
- 火
- 山
- 地
- 八卦有了
- 可以重卦么?
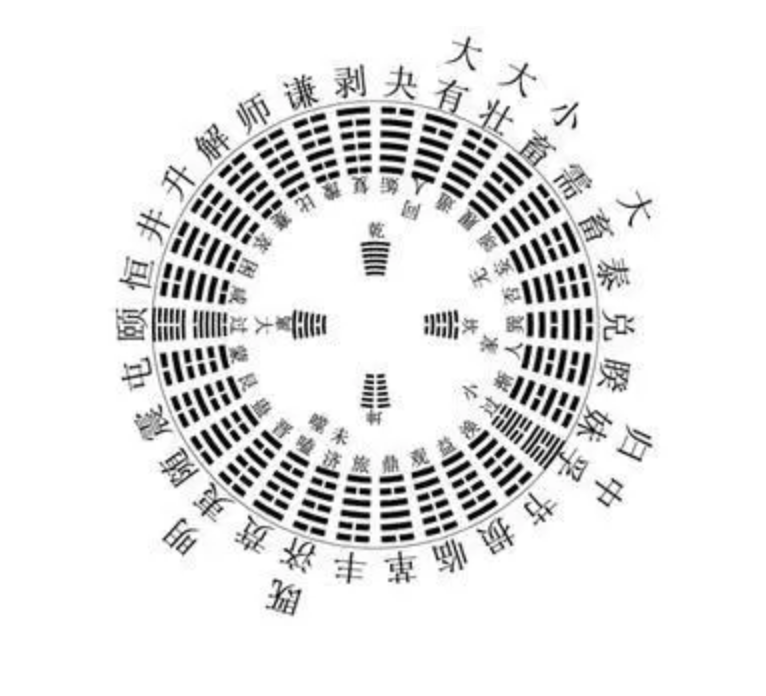
- 八八六十四卦

- 看起来都可以玩算卦了
- 还能做什么呢?
- 来随便试一个
- 看看这是什么字?
- 中文编码原来是 gbk
- unicode 现在unicode把中日韩(CJK)当成一组
- 排序是CJK
- 位置是unicode.org下方的code chart中找到
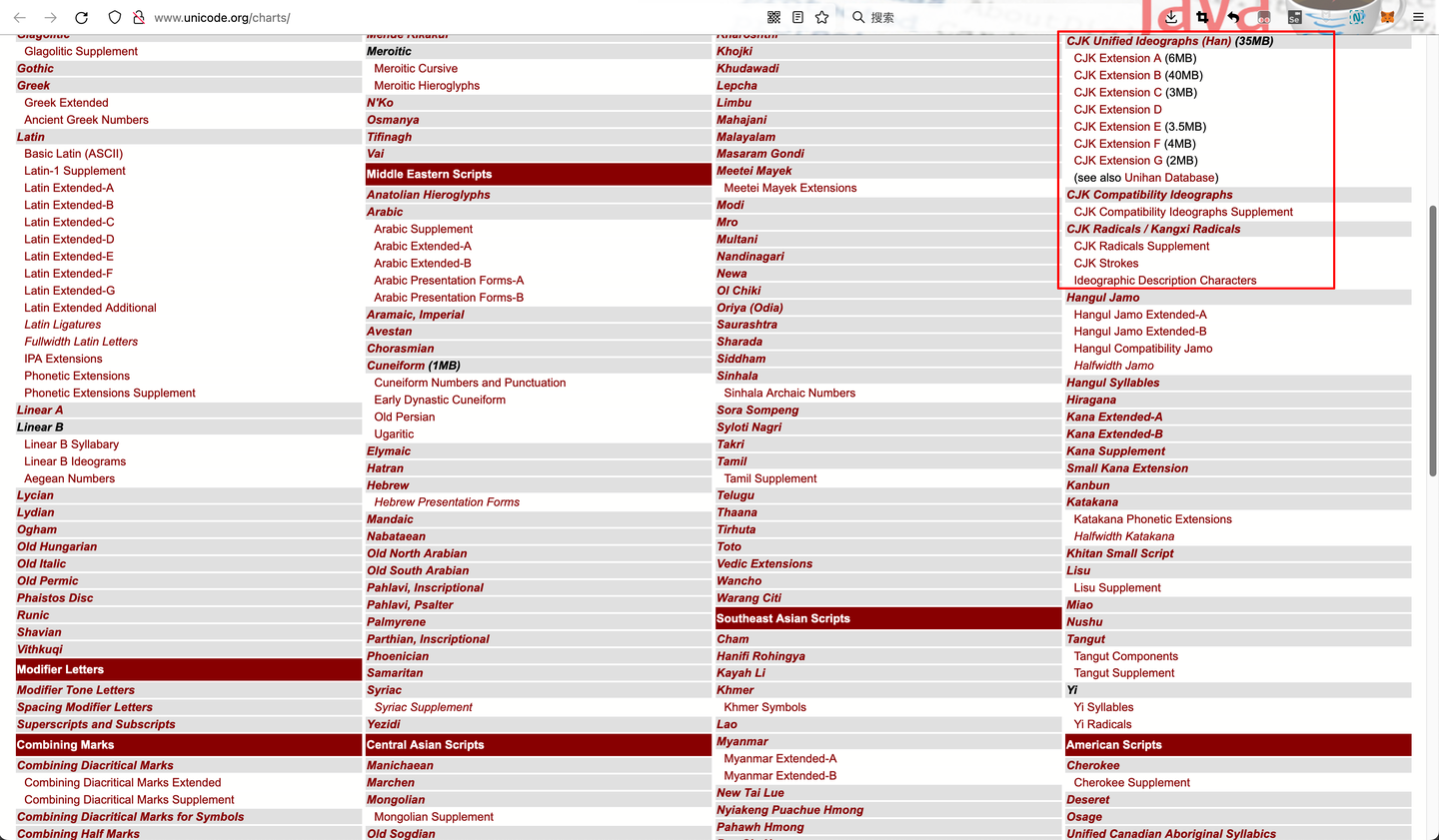
- 当然关于排序各有各的排法
- 中国是中日韩
- 日本是日中韩
- 韩国是韩中日
- unicode组织的CJK显然综合了东亚文化圈的排名
- 我仿佛听到卡吉玛
- 象形文字数量确实是拼音文字没有办法比的

- 他们听到我们有两万个字母的时候都傻了
- unicode中的文字将
- 中国汉字
- 朝鲜汉字
- 日本汉字
- 综合起来

- 得到一个汉字
- 那如果有很多异体字怎么办?

- 这些都是异体字
- 或者叫做通假字
- 在计算机里是如何的呢?
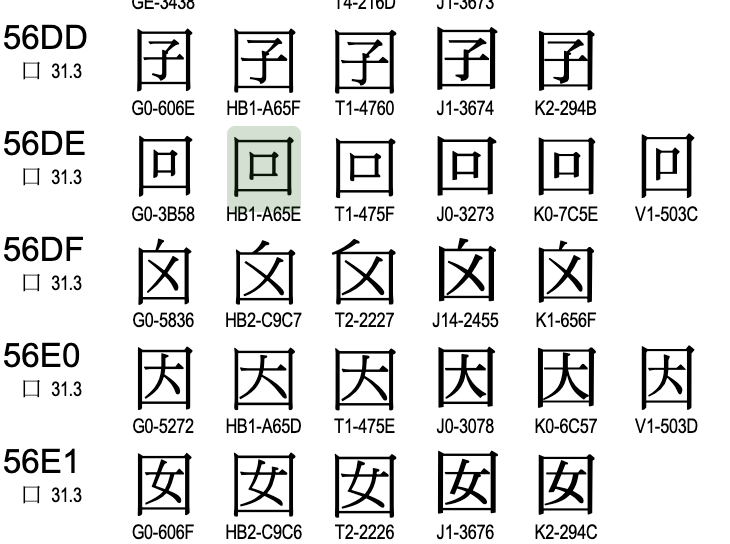
- 在0x4e00到0x9fff这个范围内
- 基本一个汉字就只有一种写法

- 字符集
- 从博多码
- 到 ascii
- 再到 8859
- 各自割据
- 如何把世界上各种字符统进行编码
- unicode顺势而生不断进化
- 不过字符总量超过了65536
- 每个汉字都有位置
- 所有汉字里面第一个汉字是什么呢?
- 我们下次再说!

[oeasy]python0128_unicode_字符集_character_set_八卦_星座的更多相关文章
- Sharp Memory LCD (ls013b7dh03)驱动
网上找不到什么靠谱的资料,甚至我调好了夏普原厂和代理商还来找我要demo, 哎,苦逼的码农. lcd_main.c #include "ls013b7dh03.h" #inclu ...
- STM32—4线SPI驱动SSD1306 OLED
文章目录 一.OLED简介 二.驱动SSD1306所需知识 1.引脚介绍 2.通信时序 3.显存GRAM 4.字库 5.SSD1306基本命令 三.代码讲解 1.相关引脚配置 2.模拟SPI通信 3. ...
- 怎样让Oracle支持中文? 语言_地域.字符集
暂时不涉及数据库业务,但是今天入库的时候中文入库报错,考虑可能是字体不支持,留待备用. 来源:Linux社区 作者:robertkun 语言_地域.字符集SIMPLIFIED CHINESE_CHI ...
- Windows默认字符集_查询
https://zhidao.baidu.com/question/32462047.html Windows95. XP……7操作系统自带的都是GBK字符集(含2万余汉字),是完全兼容GB2312( ...
- 【DBA-Oracle】更改Oracle数据字符集_转为常用的ZHS16GBK
A.oracle server 端 字符集查询 select userenv('language') from dual 其中NLS_CHARACTERSET 为server端字符集 NLS_LAN ...
- 编写Java程序_找星座朋友应用软件
一.About the Project 项目介绍 自古以来,人对于恒星的排列和形状很感兴趣,并很自然地把一些位置相近的星联系起来,组成星座.占星术亦称"占星学"."星占学 ...
- hibernate.cfg.xml_属性"connection.url"_指定字符集
1.Oracle 2.MySQL 3. 4. 5.
- MySQL字符集
字符集的选择 1.如果数据库只需要支持中文,数据量很大,性能要求也很高,应该选择双字节定长编码的中文字符集(如GBK).因为相对于UTF-8而言,GBK"较小",每个汉字只占2个字 ...
- ORACLE字符集基础知识
概念描叙 ORACLE数据库有国家字符集(national character set)与数据库字符集(database character set)之分.两者都是在创建数据库时需要设置的.国家 ...
- mysql配置命令 CHARACTER_SET_%字符集设置
参照: http://blog.csdn.net/mzlqh/article/details/7621307点击打开链接 其实现在的ubuntu12. 直接sudo apt-get install M ...
随机推荐
- uniapp video组件全屏导致页面横竖错乱问题
uniapp video组件全屏导致页面横竖错乱问题 背景介绍 使用 video组件做一个视频播放功能,不全屏的情况正常.在苹果手机上全屏后,点击左上角退出全屏,页面出现问题如下图问题,主要系统iOS ...
- IceRPC之调度管道->快乐的RPC
作者引言 很高兴啊,我们来到了IceRPC之调度管道->快乐的RPC, 基础引导,有点小压力,打好基础,才能让自已不在迷茫,快乐的畅游世界. 调度管道 Dispatch pipeline 了解如 ...
- Windows系统命令行的最佳实践
更多博文请关注:https://blog.bigcoder.cn 每次看到Mac生态中炫酷的命令行工具,我就一脸羡慕,但是奈何财力不足,整不起动辄上万的电脑,搬砖人就只能折腾折腾手里的这台window ...
- MyBatis两级缓存机制详解
缓存是提高软硬件系统性能的一种重要手段:硬件层面,现代先进CPU有三级缓存,而MyBatis也提供了缓存机制,通过缓存机制可以大大提高我们查询性能. 一级缓存 Mybatis对缓存提供支持,但是在 ...
- 7.21考试总结(NOIP模拟22)[d·e·f]
你驻足于春色中,于那独一无二的春色之中. 前言 首先,这套题的暴力分数十分丰厚,大概是 81+89+30=200 . T1 的特殊性质比较多,也都很好想,于是考场 81pts 是没有问题的. T2 暴 ...
- C# 指针简单使用
1. 使用unsafe C# 支持 unsafe 上下文,你可在其中编写不可验证的代码. 在 unsafe 上下文中,代码可使用指针.分配和释放内存块,以及使用函数指针调用方法. C# 中的不安全代码 ...
- kettle从入门到精通 第二十三课 kettle carte 错误(java.lang.OutOfMemoryError: GC overhead limit exceeded,Could not emit buffer due to lack of requests,java heap space)分析
1.Could not emit buffer due to lack of requests(无法发出缓冲区,因为请求不足.) 原因有两点:1)消费者处理数据能力较弱,如表输出步骤.2)消费者没有处 ...
- 使用WinSW把nginx做成windows服务
1.下载nginx:http://nginx.org/en/download.html 2.下载win sw:https://github.com/winsw/winsw/releases/tag/v ...
- koishi-跨平台、可扩展、高性能的机器人
koishi 介绍 Koishi 是一个跨平台.可扩展.高性能的聊天机器人框架. 它的名字和图标设计来源于东方 Project 中的角色 古明地恋 (Komeiji Koishi).古明地恋是一个会做 ...
- JAVA发送邮件报错: 535 Error: authentication failed, system busy。
解决方法: 1.设置 -> 微信绑定 -> 开启安全登录 -> 生成新密码 2.使用生成的新密码替换邮箱登录密