python3使用pandas备份mysql数据表
操作系统 :CentOS 7.6_x64
Python版本:3.9.12
MySQL版本:5.7.38
日常开发过程中,会遇到mysql数据表的备份需求,需要针对单独的数据表进行备份并定时清理数据。
今天记录下python3如何使用pandas进行mysql数据表的备份,我将从以下几个方面进行展开:
数据表备份逻辑描述
使用的相关接口及文档
以FreeSWITCH的cdr表为例进行示例
提供示例代码及运行效果视频
一、数据表表备份逻辑
大致流程如下:

备份逻辑是“定时处理”部分的功能。
业务表A:
定义最大预留天数;
定义最大预留条数;
达到最大预留天数后,按时间(6小时为跨度)来删除,直到满足最大预留条数的要求。
备份表B:
预留时间可以hard code为2年;
2小时一检查,当前时间为设定时间(2、3、4、5、6)时,才执行备份操作;
数据搬迁时需要批量提交,以提高性能。
二、相关接口及文档
pandas版本:2.1.4
sqlalchemy 版本:1.4.39
pymysql 版本:1.0.2

CentOS7环境源码安装python3.9可参考如下文章:
三、以FreeSWITCH的cdr为例进行示例
1、FreeSWITCH配置CDR
freeswitch-1.10.9.-release/src/mod/event_handlers/mod_odbc_cdr/conf/autoload_configs/odbc_cdr.conf.xml
[fsdb]
Description=MySQL freeswitch database
Driver=MySQL
SERVER =192.168.137.1
PORT =3306
USER=root
PASSWORD=123456
DATABASE = fsdb32
OPTION =67108864
CHARSET = UTF8
<configuration name="odbc_cdr.conf" description="ODBC CDR Configuration">
<settings>
<!-- <param name="odbc-dsn" value="database:username:password"/> -->
<param name="odbc-dsn" value="fsdb:root:123456"/>
<!-- global value can be "a-leg", "b-leg", "both" (default is "both") -->
<param name="log-leg" value="both"/>
<!-- value can be "always", "never", "on-db-fail" -->
<param name="write-csv" value="on-db-fail"/>
<!-- location to store csv copy of CDR -->
<param name="csv-path" value="/usr/local/freeswitch/log/odbc_cdr"/>
<!-- if "csv-path-on-fail" is set, failed INSERTs will be placed here as CSV files otherwise they will be placed in "csv-path" -->
<param name="csv-path-on-fail" value="/usr/local/freeswitch/log/odbc_cdr/failed"/>
<!-- dump SQL statement after leg ends -->
<param name="debug-sql" value="true"/>
</settings>
<tables> <table name="call_detail">
<field name="uuid" chan-var-name="uuid"/>
<field name="call_uuid" chan-var-name="call_uuid"/>
<field name="caller_number" chan-var-name="caller_id_number"/>
<field name="callee_number" chan-var-name="destination_number"/>
<field name="start_time" chan-var-name="start_stamp"/>
<field name="answer_time" chan-var-name="answer_stamp"/>
<field name="hangup_time" chan-var-name="end_stamp"/>
<field name="billsec" chan-var-name="billsec"/>
<field name="hangup_cause" chan-var-name="hangup_cause"/>
</table> </tables>
</configuration>
CREATE TABLE `call_detail` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`uuid` VARCHAR(50) NOT NULL DEFAULT '0',
`call_uuid` VARCHAR(50) NOT NULL DEFAULT '0',
`caller_number` VARCHAR(20) NOT NULL DEFAULT '0',
`callee_number` VARCHAR(50) NOT NULL DEFAULT '0',
`start_time` DATETIME NULL DEFAULT NULL,
`answer_time` DATETIME NULL DEFAULT NULL,
`hangup_time` DATETIME NULL DEFAULT NULL,
`billsec` INT(11) NOT NULL DEFAULT '0',
`hangup_cause` VARCHAR(50) NOT NULL,
`timestamp` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
)
COLLATE='latin1_swedish_ci'
ENGINE=InnoDB
;
2、使用pandas进行数据备份
CREATE TABLE `call_detail_history` (
`id` BIGINT(20) NOT NULL AUTO_INCREMENT,
`uuid` VARCHAR(50) NOT NULL DEFAULT '0',
`call_uuid` VARCHAR(50) NOT NULL DEFAULT '0',
`caller_number` VARCHAR(20) NOT NULL DEFAULT '0',
`callee_number` VARCHAR(50) NOT NULL DEFAULT '0',
`start_time` DATETIME NULL DEFAULT NULL,
`answer_time` DATETIME NULL DEFAULT NULL,
`hangup_time` DATETIME NULL DEFAULT NULL,
`billsec` INT(11) NOT NULL DEFAULT '0',
`hangup_cause` VARCHAR(50) NOT NULL,
`timestamp` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
)
COLLATE='latin1_swedish_ci'
ENGINE=InnoDB
;
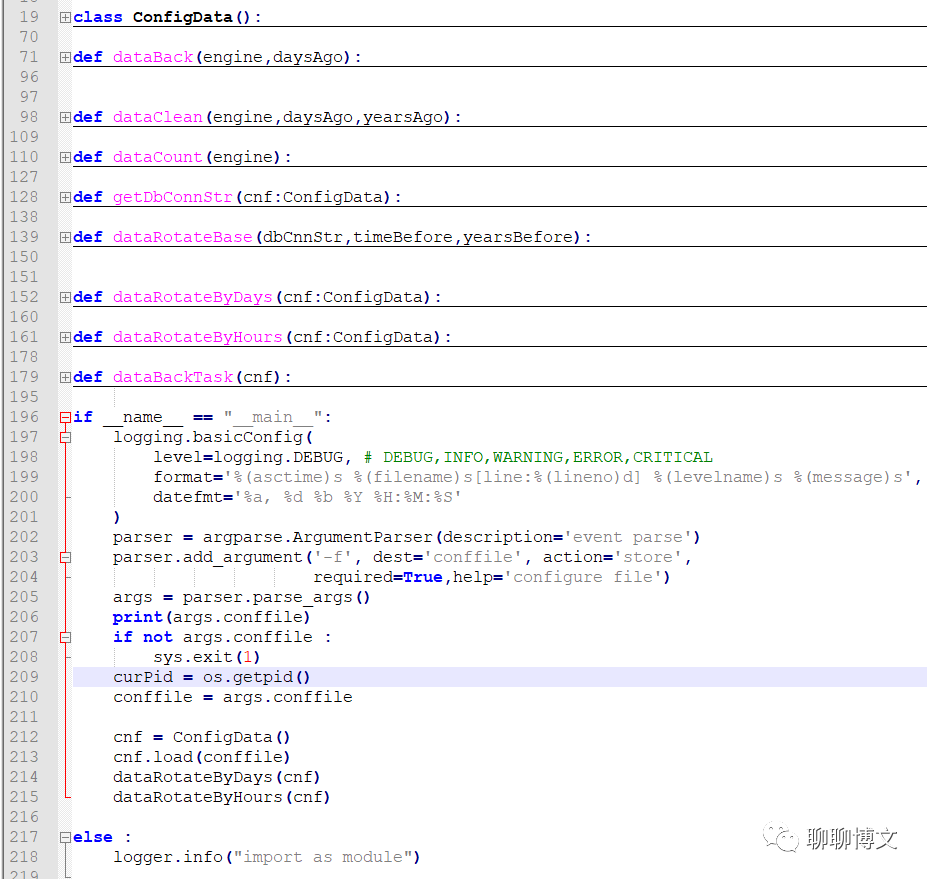
说明:
- ConfigData类
读取配置文件 - dataBack函数
以天为单位进行数据备份 - dataClean函数
执行数据清理功能(业务表和备份表) - dataCount函数
统计业务表里面的数据条目 - getDbConnStr函数
生成数据库连接字符串 - dataRotateBase函数
数据循环备份功能的具体实现,执行数据备份、数据清理操作。 - dataRotateByDays函数
按天循环备份 - dataRotateByHours函数
按小时循环备份 - dataBackTask函数
执行具体的备份任务
完整代码可从如下渠道获取:
关注微信公众号(聊聊博文,文末可扫码)后回复 20231209 获取。
<config>
<cdrReserve>
<maxDays>15</maxDays>
<maxItems>100000</maxItems>
</cdrReserve> <mysql>
<host>192.168.137.1</host>
<port>3306</port>
<user>root</user>
<password>123456</password>
<dbname>fsdb32</dbname>
</mysql> </config>
#! /bin/bash pydir=/root/py39env
export CFLAGS="-I$pydir/include"
export LDFLAGS="-L$pydir/lib"
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$pydir/lib $pydir/bin/python3.9 dataBack.py -f default.xml
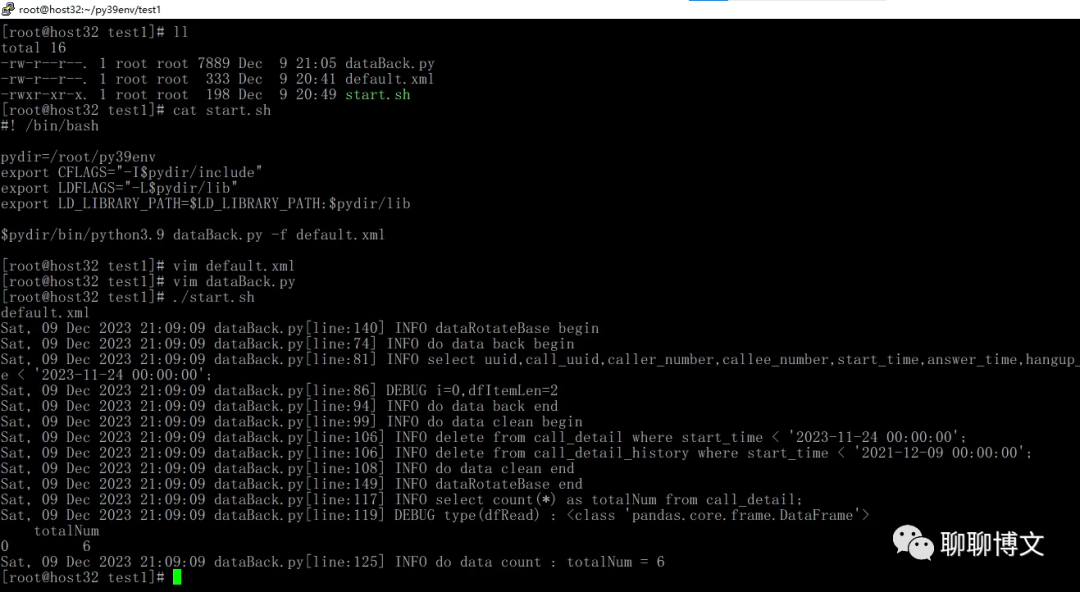
四、运行效果
python3使用pandas备份mysql数据表的更多相关文章
- 用Myisamchk让MySQL数据表更健康
用Myisamchk让MySQL数据表更健康 2011-03-15 09:15 水太深 ITPUB 字号:T | T 为了让MySQL数据库中的数据表“更健康”,就需要对其进行定期体检.在这里笔者推荐 ...
- shell编程系列25--shell操作数据库实战之备份MySQL数据,并通过FTP将其传输到远端主机
shell编程系列25--shell操作数据库实战之备份MySQL数据,并通过FTP将其传输到远端主机 备份mysql中的库或者表 mysqldump 常用参数详解: -u 用户名 -p 密码 -h ...
- MYSQL数据表损坏的原因分析和修复方法小结
MYSQL数据表损坏的原因分析和修复方法小结 1.表损坏的原因分析 以下原因是导致mysql 表毁坏的常见原因: 1. 服务器突然断电导致数据文件损坏. 2. 强制关机,没有先关闭mysql 服务. ...
- 如何优雅的备份MySQL数据?看这篇文章就够了
大家好,我是一灯,今天一块学习一下如何优雅安全的备份MySQL数据? 1. 为什么要备份数据 先说一下为什么需要备份MySQL数据? 一句话总结就是:为了保证数据的安全性. 如果我们把数据只存储在一个 ...
- 随机获取Mysql数据表的一条或多条记录
随机获得Mysql数据表的一条或多条记录有很多方法,下面我就以users(userId,userName,password......)表(有一百多万条记录)为例,对比讲解下几个方法效率问题: sel ...
- (转)MySQL数据表中带LIKE的字符匹配查询
MySQL数据表中带LIKE的字符匹配查询 2014年07月15日09:56 百科369 MySQL数据表中带LIKE的字符匹配查询 LIKE关键字可以匹配字符串是否相等. 如果字段的值与指定的 ...
- MySQL 数据表修复及数据恢复
1. MYSQL数据表在什么情况下容易损坏? 服务器突然断电导致数据文件损坏. 强制关机,没有先关闭mysql 服务等. 2. 数据表损坏后的主要现象是什么? 从表中选择数据之时,得到如下错误:I ...
- 设置MySQL数据表主键
设置MySQL数据表主键: 使用“primary key”关键字创建主键数据列.被设置为主键列不允许出现重复的值,很多情况下与“auto_increment”递增数字相结合.如下SQL语句所示: My ...
- 谈谈MySQL数据表的类型(转)
谈谈MySQL数据表的类型 通常意义上,数据库也就是数据的集合,具体到计算机上数据库可以是存储器上一些文件的集合或者一些内存数据的集合. 我们通常说的MySql数据库,sql server数据库等等其 ...
- mysql数据表增删改查
http://www.runoob.com/mysql/mysql-tutorial.html 一.MySQL 创建数据表 创建MySQL数据表需要以下信息: 表名 表字段名 定义每个表字段 语法 以 ...
随机推荐
- Pandas 使用教程 JSON
目录 JSON 转换为 CSV 简单 JSON 从 URL 中读取 JSON 数据: 字典转化为 DataFrame 数据 内嵌的 JSON 数据 复杂 JSON Pandas 可以很方便的处理 JS ...
- 【matplotlib基础】--子图
使用Matplotlib对分析结果可视化时,比较各类分析结果是常见的场景.在这类场景之下,将多个分析结果绘制在一张图上,可以帮助用户方便地组合和分析多个数据集,提高数据可视化的效率和准确性. 本篇介绍 ...
- HDFS核心概念与架构
HDFS简介 HDFS是Hadoop项目的核心子项目,在大数据开发中通过分布式计算对海量数据进行存储与管理,它基于流数据模式访问和处理超大文件的需求而开发,可以运行在廉价的商用服务器上,为海量数据提供 ...
- 拯救“消失的她”——双系统grub完美恢复方案
双系统grub意外消失怎么办? 不用重装系统.不用去维修店.不会丢数据,教你一招,完美恢复grub! 背景 我的电脑是windows和linux双系统,启动项使用的grub.某天准备切换linux时突 ...
- numpy_tricks
Numpy Tricks 这篇文章不定期更新,主要是记录在使用numpy过程中一些有效的tricks(或者重要的API) import numpy as np numpy.where() numpy. ...
- Ionic3 与Electron制作桌面应用
Ionic3 与Electron制作桌面应用 原文:https://medium.com/@LohaniDamodar/lets-make-desktop-application-with-ionic ...
- Solution -「SP 106」BINSTIRL
Description Link. 求 \(\begin{Bmatrix}n \\ m\end{Bmatrix}\bmod2\) Solution 求 \[\begin{aligned} \begin ...
- Centos7使用ssh免密登陆同时禁用root密码登陆
Centos7使用ssh免密登陆同时禁用root密码登陆 首先配置免密登陆,参考:ssh免密登陆 禁用root密码登陆 修改 /etc/ssh/sshd_config 文件 找到: RSAAuthen ...
- 解密IP分片与重组:数据传输中的关键技术
引言 在上一章节中,我们详细讨论了IP的分类和无分类原则的原理以及其在网络通信中的应用.IP分片与重组是在数据包传输过程中起到关键作用的机制.当数据包的大小超过网络链路的MTU(最大传输单元)限制时, ...
- C++中::和:, .和->的作用和区别
符号::和:的作用和区别 ::是作用域运算符,A::B表示作用域A中的-名称B,A可以是名字空间.类.结构: 类作用域操作符 "::"指明了成员函数所属的类.如:M::f(s)就表 ...