Kafka Topic 中明明有可拉取的消息,为什么 poll 不到
开心一刻
今天小学女同学给我发消息
她:你现在是毕业了吗
我:嗯,今年刚毕业
她给我发了一张照片,怀里抱着一只大橘猫
她:我的眯眯长这么大了,好看吗
我:你把猫挪开点,它挡住了,我看不到
她:你是 sb 吗,滚
我解释道:你说的是猫呀
可消息刚发出,就出现了红色感叹号,并提示:消息已发出,但被对方拒收了

kafka搭建
出于简单考虑,基于 docker 搭建一个 kafka 节点;因为一些原因,国内的 Docker Hub 镜像加速器都不可用了,目前比较靠谱的做法是搭建个人镜像仓库,可参考:Docker无法拉取镜像解决办法,我已经试过了,是可行的,但还是想补充几点
sync-image-example.yml只需要修改最后的镜像拷贝,其他内容不需要改
支持一次配置多个镜像的拷贝
镜像拷贝
docker 镜像拷贝命令的格式
skopeo copy docker://docker.io/命名空间/镜像名:TAG docker://阿里云镜像地址/命名空间/镜像名:TAG
我们以 kafka 为例,去 Docker Hub 一搜,好家伙,搜出来上万个
我们将搜索条件精确化一些,搜
wurstmeister/kafka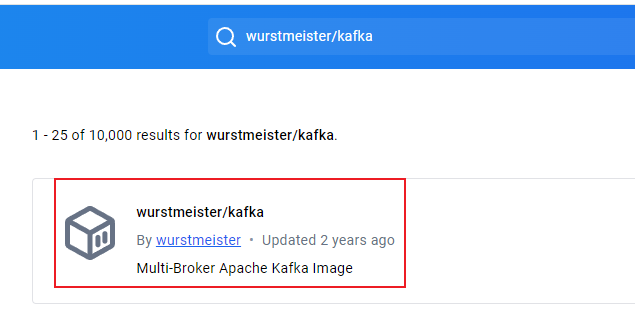
点进去,它在 Docker Hub 的地址是:
那它的 docker 地址就是
docker://docker.io/wurstmeister/kafka
其他的镜像用类似的方式去找,所以最终的拷贝命令类似如下:
skopeo copy docker://docker.io/wurstmeister/kafka:latest docker://registry.cn-hangzhou.aliyuncs.com/qingshilu/wurstmeister_kafka:latest
如果一切顺利,那么在我们的阿里云个人镜像仓库就能看到我们拷贝的镜像了
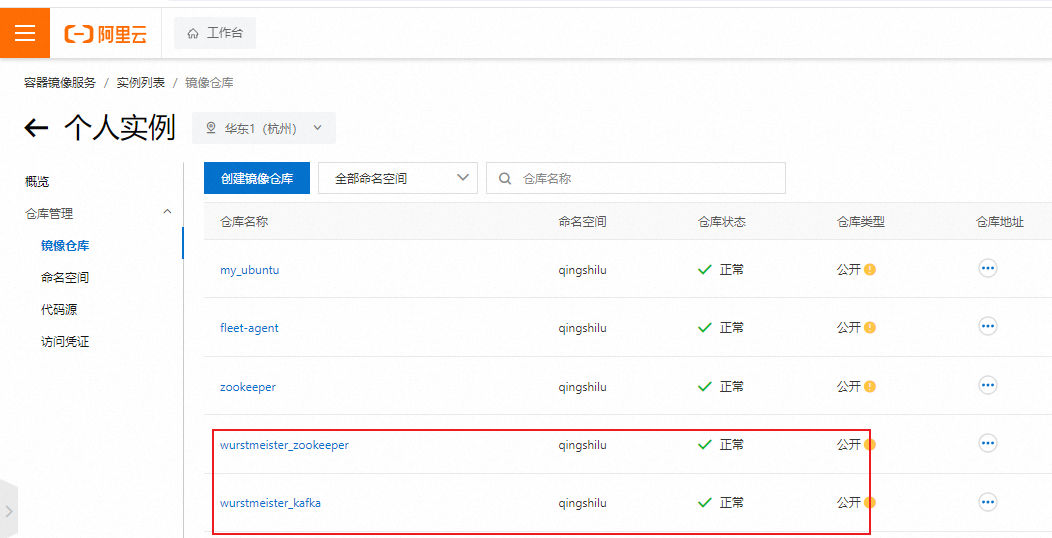
如何 pull
在个人仓库点镜像名,会看到
操作指南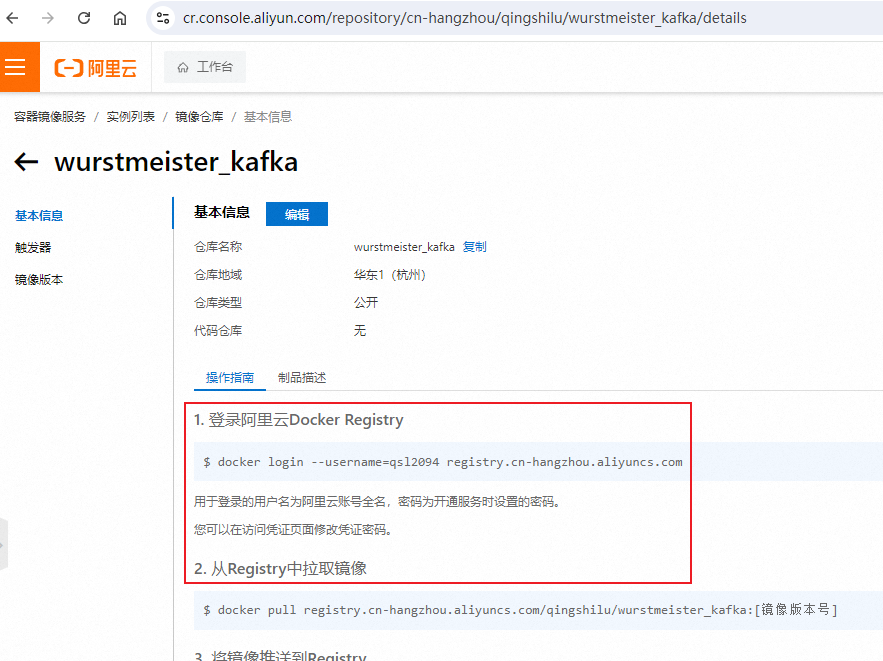
我们只关注前两步,就可以将镜像 pull 下来

镜像获取到之后,就可以搭建 kafka 了;因为依赖 zookeeper,我们先启动它
docker run -d --name zookeeper-test -p 2181:2181 \
--env ZOO_MY_ID=1 \
-v zookeeper_vol:/data \
-v zookeeper_vol:/datalog \
-v zookeeper_vol:/logs \
registry.cn-hangzhou.aliyuncs.com/qingshilu/wurstmeister_zookeeper
然后启动 kafka
docker run -d --name kafka-test -p 9092:9092 \
--env KAFKA_ZOOKEEPER_CONNECT=192.168.2.118:2181 \
--env KAFKA_ADVERTISED_HOST_NAME=192.168.2.118 \
--env KAFKA_ADVERTISED_PORT=9092 \
--env KAFKA_LOG_DIRS=/kafka/logs \
-v kafka_vol:/kafka \
registry.cn-hangzhou.aliyuncs.com/qingshilu/wurstmeister_kafka
不出意外的话,都启动成功

如果出意外了,大家也别慌,用 docker log 去查看日志,然后找对应的解决方案
# 1.先找到启动失败的容器id
docker ps -a
# 2.用 docker log 查看容器启动日志
docker log 容器id
如果需要开启 kafka 的 SASL 认证,可参考:Docker-Compose搭建带SASL用户密码验证的Kafka 来搭建
Kafka Tool
详情可查看:kafka可视化客户端工具(Kafka Tool)的基本使用
创建 Topic:test-topic,并发送一条消息

此时 test-topic 中有 1 条消息
消费者 poll
代码很简单
/**
* @author: 青石路
*/
public class MsgConsumer {
private static final Logger LOGGER = LoggerFactory.getLogger(MsgConsumer.class);
public static void main(String[] args) {
Properties props = new Properties();
props.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.2.118:9092");
props.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "test_group");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 如果在kafka中找不到当前消费者的偏移量,则设置为最旧的
props.setProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 500);
KafkaConsumer<String, String> consumer = new KafkaConsumer<String,String>(props);
// 订阅主题
consumer.subscribe(Collections.singleton("test-topic"));
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
LOGGER.info("records count = {}", records.count());
records.forEach(record -> LOGGER.info("{} - {} - {}", record.offset(), record.key(), record.value()));
// consumer.commitAsync();
consumer.close();
}
}
我们执行下,输出日志如下

竟然 poll 不到消息,为什么呀?

我们调整下代码,循环 poll
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
LOGGER.info("records count = {}", records.count());
records.forEach(record -> LOGGER.info("{} - {} - {}", record.offset(), record.key(), record.value()));
}
我们再执行下,输出日志如下
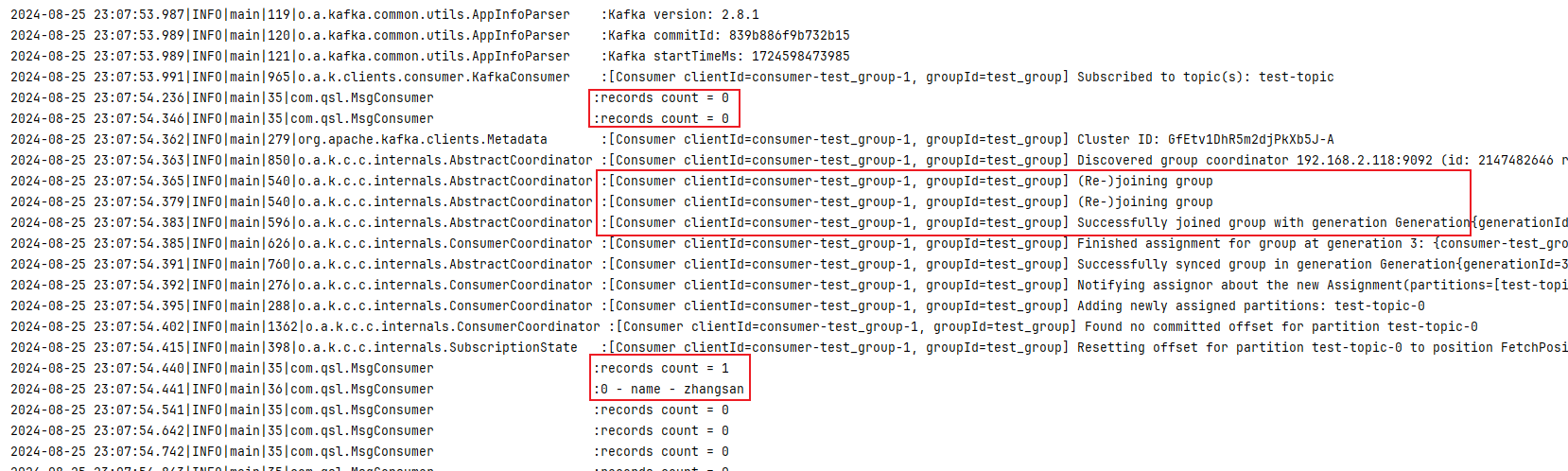
消费者 poll 的过程中会先判断当前消费者是否在 消费者组 中,如果不在,会先加入消费者组,在加入过程中,ConsumerCoordinator 会对这个消费者组 Rebalance,整个过程中该消费者组内的所有消费者都不能工作,而 poll 又配置了超时时间(100 毫秒),如果在超时时间内,当前消费者还未正常加入消费者组中,那么 poll 肯定是拉取不到数据的;根据日志可以看出,第 3 次 poll 的时候,消费者已经正常加入消费者组中,那么就能 poll 到数据了
很多小伙伴可能可能会有这样的疑问
平时在项目中使用的时候,从来没有感受到这样的问题,为什么呢
原因有以下几点
- poll 的超时时间设置比较长,超时时间内消费者能够正常加入到消费者组中
- 消费者随项目的启动创建,存活周期与项目一致,那么只有前几次 poll 的时候,可能会因为消费者未加入到消费者组中而拉取不到数据,而一旦消费者成功加入到消费者组之后,那么只要 Topic 中有数据,poll 肯定能拉取到数据;从整个次数占比来看,poll 拉取不到数据的异常情况(Topic 中有可拉取的数据,但 poll 不到)占比非常小,小到可以忽略不计了
所以你们感受不到这样;但如果某些场景下,比如 DataX 从 kafka 读数据
消费者要不断新建,那么 poll 不到数据的异常情况的占比就会上来了,那就需要通过一些机制来降低其所造成的的影响了,比如说重试机制
总结
- 示例代码:kafka-demo
- 如果大家平时用 docker 比较多,推荐通过搭建个人镜像仓库来解决镜像拉取超时的问题
- kakfa 消费者 poll 的时候,消费者如果不在消费者组中,会先加入消费者组,那么超时时间内可能 poll 不到数据,可以通过增大超时时间,或者重试机制来降低 poll 不到数据的异常次数(Topic 中没有可拉取的数据而 poll 不到的情况不算异常情况)
Kafka Topic 中明明有可拉取的消息,为什么 poll 不到的更多相关文章
- 解决 MySQL 比如我要拉取一个消息表中用户id为1的前10条最新数据
我们都知道,各种主流的社交应用或者阅读应用,基本都有列表类视图,并且都有滑到底部加载更多这一功能, 对应后端就是分页拉取数据.好处不言而喻,一般来说,这些数据项都是按时间倒序排列的,用户只关心最新的动 ...
- 源码分析Kafka 消息拉取流程
目录 1.KafkaConsumer poll 详解 2.Fetcher 类详解 本节重点讨论 Kafka 的消息拉起流程. @(本节目录) 1.KafkaConsumer poll 详解 消息拉起主 ...
- RocketMQ中PullConsumer的消息拉取源码分析
在PullConsumer中,有关消息的拉取RocketMQ提供了很多API,但总的来说分为两种,同步消息拉取和异步消息拉取 同步消息拉取以同步方式拉取消息都是通过DefaultMQPullConsu ...
- RocketMQ 拉取消息-文件获取
看完了上一篇的<RocketMQ 拉取消息-通信模块>,请求进入PullMessageProcessor中,接着 PullMessageProcessor.processRequest(f ...
- 【mq读书笔记】消息拉取长轮训机制(Broker端)
RocketMQ并没有真正实现推模式,而是消费者主动想消息服务器拉取消息,推模式是循环向消息服务端发送消息拉取请求. 如果消息消费者向RocketMQ发送消息拉取时,消息未到达消费队列: 如果不启用长 ...
- 【RocketMQ】消息的拉取
RocketMQ消息的消费以组为单位,有两种消费模式: 广播模式:同一个消息队列可以分配给组内的每个消费者,每条消息可以被组内的消费者进行消费. 集群模式:同一个消费组下,一个消息队列同一时间只能分配 ...
- 【mq读书笔记】消息拉取
疑问:PullRequest何时添加? PullMessageService提供延迟添加与立即添加2种方式 疑问:PullRequest是在什么时候创建的呢? 1.上上图中 PullRequest p ...
- canal从mysql拉取数据,并以protobuf的格式往kafka中写数据
大致思路: canal去mysql拉取数据,放在canal所在的节点上,并且自身对外提供一个tcp服务,我们只要写一个连接该服务的客户端,去拉取数据并且指定往kafka写数据的格式就能达到以proto ...
- FLUME安装&环境(二):拉取MySQL数据库数据到Kafka
Flume安装成功,环境变量配置成功后,开始进行agent配置文件设置. 1.agent配置文件(mysql+flume+Kafka) #利用Flume将MySQL表数据准实时抽取到Kafka a1. ...
- Kafka消费者拉取数据异常Unexpected error code 2 while fetching data
Kafka消费程序间歇性报同一个错: 上网没查到相关资料,只好自己分析.通过进一步分析日志发现,只有在拉取某一个特定的topic的数据时报错,如果拉取其他topic的数据则不会报错.而从这个异常信息来 ...
随机推荐
- 基于Bootstrap Blazor开源的.NET通用后台权限管理系统
前言 今天大姚给大家分享一个基于Bootstrap Blazor开源的.NET通用后台权限管理系统,后台管理页面兼容所有主流浏览器,完全响应式布局(支持电脑.平板.手机等所有主流设备),可切换至 Bl ...
- Python脚本报错:DeprecationWarning: Using or importing the ABCs from 'collections' instead of from 'collections.abc' is deprecated since Python 3.3,and in 3.9 it will stop working import pymssql
报错信息: monitor_mssql.py:10: DeprecationWarning: Using or importing the ABCs from 'collections' instea ...
- vs code 设置中文
1.安装 下载地址:官网 打开 安装后打开默认显示英文界面. 2.修改 使用快捷键 ctrl+shift+p, 输入configure display language 下拉框选择 install ...
- c 语言学习第二天
常量 字符串常量 字符 例如:'f','i','z','a'编译器为每个字符分配空间. 'f' 'i' 'z' 'a' 字符串 例如:"hello"编译器为字符串里的每个字符分配空 ...
- 可能是全网最适合入门的面向对象编程教程:Python实现-嵌入式爱好者必看!
前言 对于嵌入式入门的同学来说,往往会遇到设备端处理能力不足.在面对大规模计算情况下需要借助上位机完成进一步的数据处理的情况.此时,Python 语言因其简单易用的特点和丰富多样的库成为了我们做上位机 ...
- 如何去除字符串中的 "\n" ?80% 的同学错了!
大家好,我是鱼皮,今天分享一个小知识. 我最近负责的工作是设计一个 SQL 解析引擎.简单来说,就是将一个 SQL 表达式字符串,解析为一颗对象树,从而执行查询等一系列操作. 在最开始,我就遇到了一个 ...
- PN转Modbus RTU模块连接ACS4QQ变频器通信
一台完整的机器在出厂前由许多部件组成.但是,由于各种原因,这些组件来自不同的制造商,导致设备之间的通信协议存在差异.Modbus和Profinet代表两种不同的通信协议,Profinet通常用于较新的 ...
- idea快捷键Ctrl+alt+m:如何快速抽离部分方法
Ctrl+alt+m 效果如下图
- 【JDBC】Extra02 SqlServer-JDBC
官网驱动获取地址: https://www.microsoft.com/zh-cn/download/details.aspx Maven仓库获取: https://mvnrepository.com ...
- 【Git】05 分支管理
查看所有分支: git branch Git将列出所有分支,如果是当前使用的分支,前面会加一个星号表示 创建一个新的分支: git branch 分支名称 创建一个分支并且指向该分支: git che ...