lec-5-Policy Gradients
直接策略微分
- Goal:
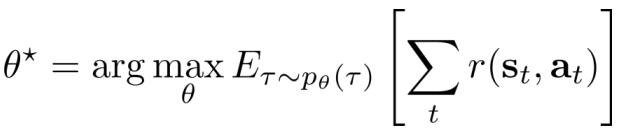
- idea:求最大值:直接求导
- tip:利用log导数等式进行变换
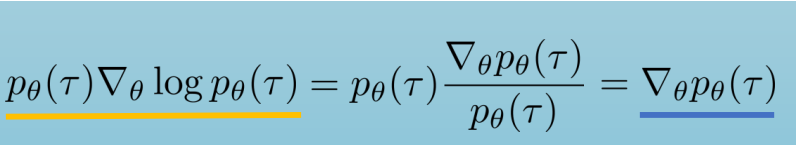
- 具体推导:
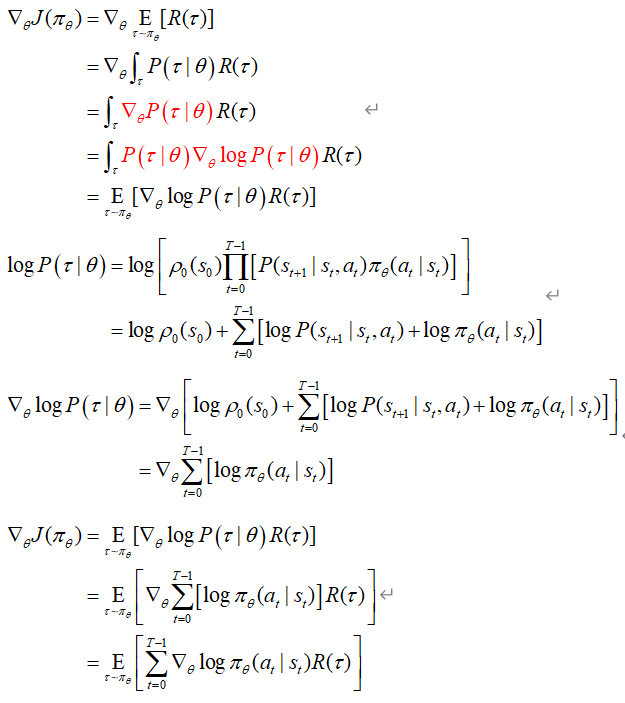
理解策略梯度
假定开始policy服从高斯分布,采样得到回报,计算梯度,根据reward增加动作概率,改变policy分布
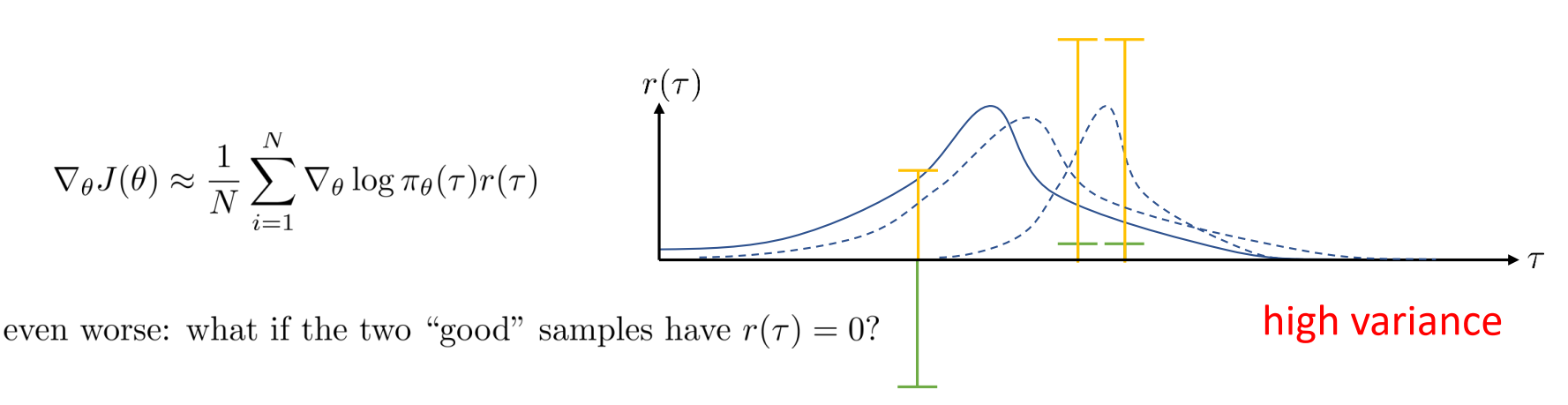
- 会发生的错误:高方差
- 当采样有负奖励样本的时候(绿色奖励),原本policy改变向右移动更多(最右边的虚曲线);改变奖励(添加常量),变为正奖励(黄色奖励),向右移动的少了(中间虚曲线),从而这导致了高差异(相比于之前的曲线)。
- 如果对于无限样本,不会导致差异。
- 如果回报为0,那么它们的policy梯度就不重要。
减少方差
- 因果关系:放弃过去的回报,policy不会影响t之前的回报
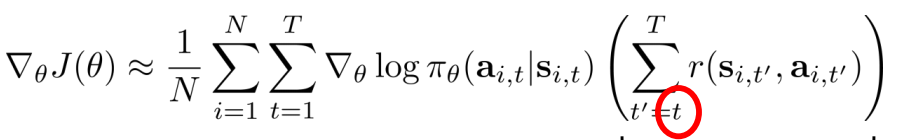
- Baselines:不会改变期望值,会改变方差
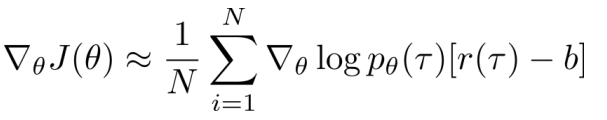
一般取b为回报均值: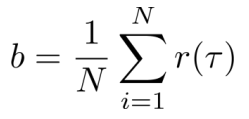 【but使得方差最小(即方差为0)的b不是回报均值】
【but使得方差最小(即方差为0)的b不是回报均值】
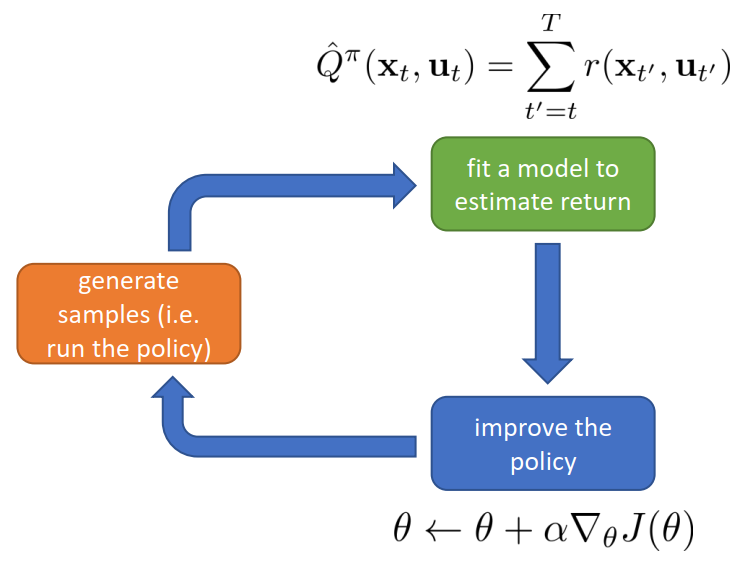
Off-policy PG
- REINFORCE algorithm(on-policy)
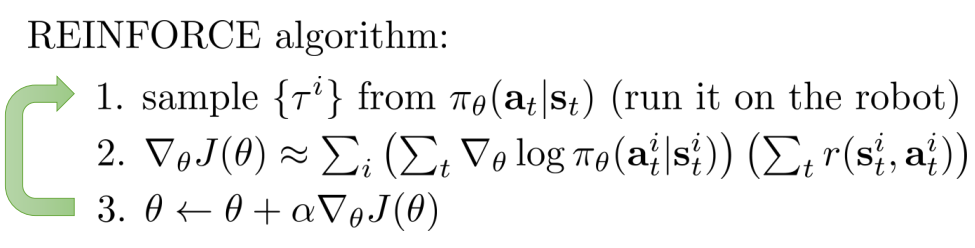
- 缺点:每次改进参数都要扔掉样本(样本利用率低);单步梯度更新
- 在基本RL过程中的表示:
- 重要性采样原理(IS):实现从on-policy到off-policy
- 原理:

- 应用于RL:重用以前的policy(用 旧policy 进行采样,然后改进参数)
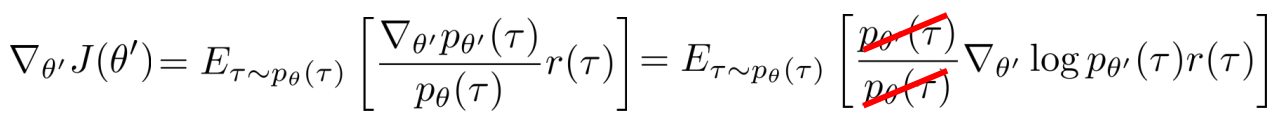
- 原理:
- 应用
- 使用自动差分器:伪loss进行反向传播
- 实际要考虑
- 梯度的高方差
- 批量学习batch size
- 学习率的调整learning rate
- 优化器的选择optimizers
Advanced PG
- 学习率的难题
policy参数服从高斯分布,梯度总会趋向于更小的方差的方向移动,方差就成了决定性因素,均值就不动了,梯度速度就慢了,继而收敛慢了。故学习率调整的难题,如果 速度小,学习率大,会使得policy在均值方向上很快不动。 - 自然梯度
- 自动步长调整
.....
Resource:CS285官网资料
版权归原作者 Lee_ing 所有
未经原作者允许不得转载本文内容,否则将视为侵权;转载或者引用本文内容请注明来源及原作者
lec-5-Policy Gradients的更多相关文章
- (zhuan) Deep Deterministic Policy Gradients in TensorFlow
Deep Deterministic Policy Gradients in TensorFlow AUG 21, 2016 This blog from: http://pemami49 ...
- 几句话总结一个算法之Policy Gradients
强化学习与监督学习的区别在于,监督学习的每条样本都有一个独立的label,而强化学习的奖励(label)是有延后性,往往需要等这个回合结束才知道输赢 Policy Gradients(PG)计算某个状 ...
- Policy Gradient Algorithms
Policy Gradient Algorithms 2019-10-02 17:37:47 This blog is from: https://lilianweng.github.io/lil-l ...
- (转)RL — Policy Gradient Explained
RL — Policy Gradient Explained 2019-05-02 21:12:57 This blog is copied from: https://medium.com/@jon ...
- (转) How to Train a GAN? Tips and tricks to make GANs work
How to Train a GAN? Tips and tricks to make GANs work 转自:https://github.com/soumith/ganhacks While r ...
- (转) Deep Learning Research Review Week 2: Reinforcement Learning
Deep Learning Research Review Week 2: Reinforcement Learning 转载自: https://adeshpande3.github.io/ad ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- [Reinforcement Learning] 强化学习介绍
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视.最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下. 强化学习定义 先借用维基百科上对强化 ...
- 花十分钟,让你变成AI产品经理
花十分钟,让你变成AI产品经理 https://www.jianshu.com/p/eba6a1ca98a4 先说一下你阅读本文可以得到什么.你能得到AI的理论知识框架:你能学习到如何成为一个AI产品 ...
- 学习笔记TF037:实现强化学习策略网络
强化学习(Reinforcement Learing),机器学习重要分支,解决连续决策问题.强化学习问题三概念,环境状态(Environment State).行动(Action).奖励(Reward ...
随机推荐
- spring aop切面说明
execution:处理Join Point的类型,例如call.execution (* android.app.Activity.on**(..)):这个是最重要的表达式,第一个*表示返回值,*表 ...
- vivo全球商城:库存系统架构设计与实践
作者:vivo官网商城开发团队 - Xu Yi.Yan Chao 本文是vivo商城系列文章,主要介绍vivo商城库存系统发展历程.架构设计思路以及应对业务场景的实践. 一.业务背景 库存系统是电商商 ...
- Java-02对象传递和返回
Java-02对象传递和返回 当你在"传递"一个对象的时候,你实际上是在传递它的引用 1引用 1.1传递引用 当你将一个引用传给方法后,该引用指向的仍然是原来的对象: /** * ...
- 阿里云镜像创建Spring Boot工厂
参考博客:https://blog.csdn.net/qq_40052237/article/details/115794368 http://start.aliyun.com
- Spring Cloud 学习笔记(周阳)
参考博客:https://blog.csdn.net/u011863024/article/details/114298270 内容:netflix,alibaba
- 百炼成钢 —— 声网实时网络的自动运维丨Dev for Dev 专栏
本文为「Dev for Dev 专栏」系列内容,作者为声网大数据算法工程师黄南薰. 01 自动运维介绍 2016 年,Gartner 创新性地提出了 AIOps 的概念[1],开创了人工智能辅助运维决 ...
- MySQL查询练习 (转载)
转载 @香草味的橙子 侵删 Evernote Export body, td { font-family: 微软雅黑; font-size: 10pt } mysql查询练习 新建一个查询用的数据库: ...
- Qt实用技巧:在CentOS上使用linuxdeployqt打包发布qt程序
前言 之前在ubuntu上发布qt程序相对还好,使用脚本,在麒麟上发布的时候,使用脚本就不太兼容,同时为了实现直接点击应用可以启动应用的效果,使用linuxdeployqt发布qt程序. 本篇文 ...
- Vue基础语法整理
vue基础用法&基础原理整理 1. vue基础知识和原理 1.1 初识Vue 想让Vue工作,就必须创建一个Vue实例,且要传入一个配置对象 demo容器里的代码依然符合html规范,只不过混 ...
- vue双向监听proxy
console.log('判断页面是否有滚动条', this.hasScrollbar) const that = this that.count = 0 // 计数 that.scrollProxy ...